 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Rank Field-Weighted Factorization Machines for Low Latency Item Recommendation
Jul 22, 2024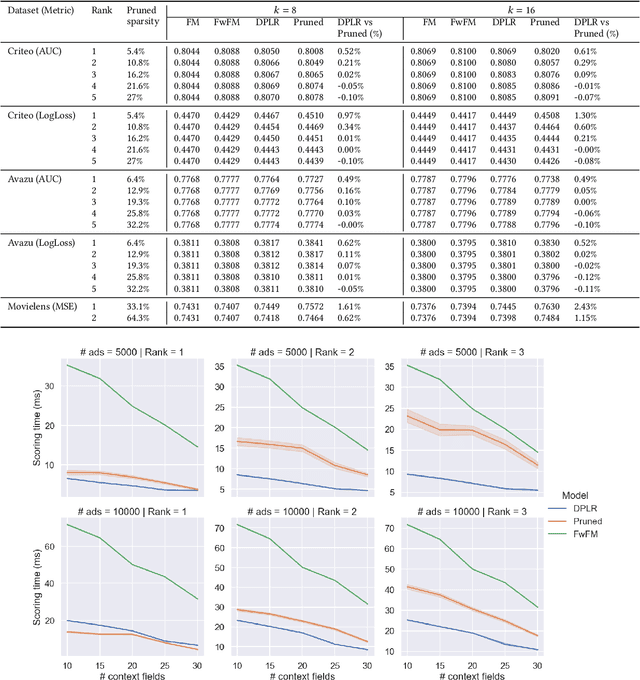
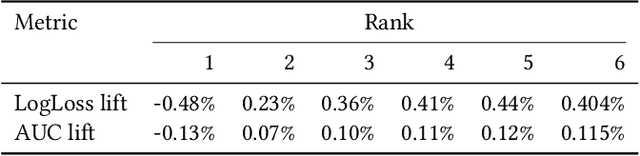
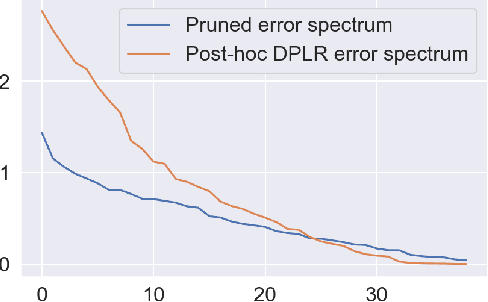

Factorization machine (FM) variants are widely used in recommendation systems that operate under strict throughput and latency requirements, such as online advertising systems. FMs are known both due to their ability to model pairwise feature interactions while being resilient to data sparsity, and their computational graphs that facilitate fast inference and training. Moreover, when items are ranked as a part of a query for each incoming user, these graphs facilitate computing the portion stemming from the user and context fields only once per query. Consequently, in terms of inference cost, the number of user or context fields is practically unlimited. More advanced FM variants, such as FwFM, provide better accuracy by learning a representation of field-wise interactions, but require computing all pairwise interaction terms explicitly. The computational cost during inference is proportional to the square of the number of fields, including user, context, and item. When the number of fields is large, this is prohibitive in systems with strict latency constraints. To mitigate this caveat, heuristic pruning of low intensity field interactions is commonly used to accelerate inference. In this work we propose an alternative to the pruning heuristic in FwFMs using a diagonal plus symmetric low-rank decomposition. Our technique reduces the computational cost of inference, by allowing it to be proportional to the number of item fields only. Using a set of experiments on real-world datasets, we show that aggressive rank reduction outperforms similarly aggressive pruning, both in terms of accuracy and item recommendation speed. We corroborate our claim of faster inference experimentally, both via a synthetic test, and by having deployed our solution to a major online advertising system. The code to reproduce our experimental results is at https://github.com/michaelviderman/pytorch-fm/tree/dev.
Improving conversion rate prediction via self-supervised pre-training in online advertising
Jan 25, 2024The task of predicting conversion rates (CVR) lies at the heart of online advertising systems aiming to optimize bids to meet advertiser performance requirements. Even with the recent rise of deep neural networks, these predictions are often made by factorization machines (FM), especially in commercial settings where inference latency is key. These models are trained using the logistic regression framework on labeled tabular data formed from past user activity that is relevant to the task at hand. Many advertisers only care about click-attributed conversions. A major challenge in training models that predict conversions-given-clicks comes from data sparsity - clicks are rare, conversions attributed to clicks are even rarer. However, mitigating sparsity by adding conversions that are not click-attributed to the training set impairs model calibration. Since calibration is critical to achieving advertiser goals, this is infeasible. In this work we use the well-known idea of self-supervised pre-training, and use an auxiliary auto-encoder model trained on all conversion events, both click-attributed and not, as a feature extractor to enrich the main CVR prediction model. Since the main model does not train on non click-attributed conversions, this does not impair calibration. We adapt the basic self-supervised pre-training idea to our online advertising setup by using a loss function designed for tabular data, facilitating continual learning by ensuring auto-encoder stability, and incorporating a neural network into a large-scale real-time ad auction that ranks tens of thousands of ads, under strict latency constraints, and without incurring a major engineering cost. We show improvements both offline, during training, and in an online A/B test. Following its success in A/B tests, our solution is now fully deployed to the Yahoo native advertising system.
Consistent Text Categorization using Data Augmentation in e-Commerce
May 09, 2023The categorization of massive e-Commerce data is a crucial, well-studied task, which is prevalent in industrial settings. In this work, we aim to improve an existing product categorization model that is already in use by a major web company, serving multiple applications. At its core, the product categorization model is a text classification model that takes a product title as an input and outputs the most suitable category out of thousands of available candidates. Upon a closer inspection, we found inconsistencies in the labeling of similar items. For example, minor modifications of the product title pertaining to colors or measurements majorly impacted the model's output. This phenomenon can negatively affect downstream recommendation or search applications, leading to a sub-optimal user experience. To address this issue, we propose a new framework for consistent text categorization. Our goal is to improve the model's consistency while maintaining its production-level performance. We use a semi-supervised approach for data augmentation and presents two different methods for utilizing unlabeled samples. One method relies directly on existing catalogs, while the other uses a generative model. We compare the pros and cons of each approach and present our experimental results.