 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Text Categorization using Data Augmentation in e-Commerce
May 09, 2023The categorization of massive e-Commerce data is a crucial, well-studied task, which is prevalent in industrial settings. In this work, we aim to improve an existing product categorization model that is already in use by a major web company, serving multiple applications. At its core, the product categorization model is a text classification model that takes a product title as an input and outputs the most suitable category out of thousands of available candidates. Upon a closer inspection, we found inconsistencies in the labeling of similar items. For example, minor modifications of the product title pertaining to colors or measurements majorly impacted the model's output. This phenomenon can negatively affect downstream recommendation or search applications, leading to a sub-optimal user experience. To address this issue, we propose a new framework for consistent text categorization. Our goal is to improve the model's consistency while maintaining its production-level performance. We use a semi-supervised approach for data augmentation and presents two different methods for utilizing unlabeled samples. One method relies directly on existing catalogs, while the other uses a generative model. We compare the pros and cons of each approach and present our experimental results.
Interpreting Complex Regression Models
Feb 26, 2018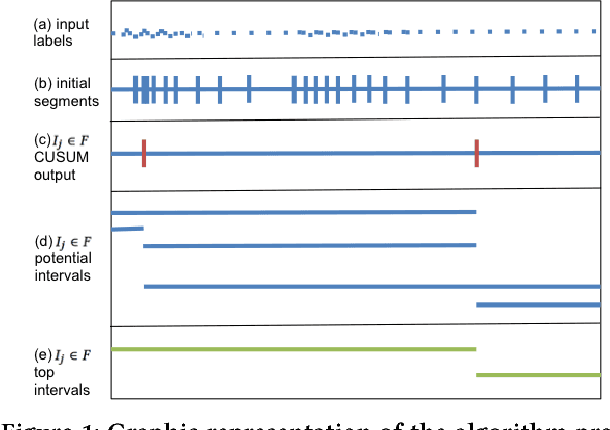
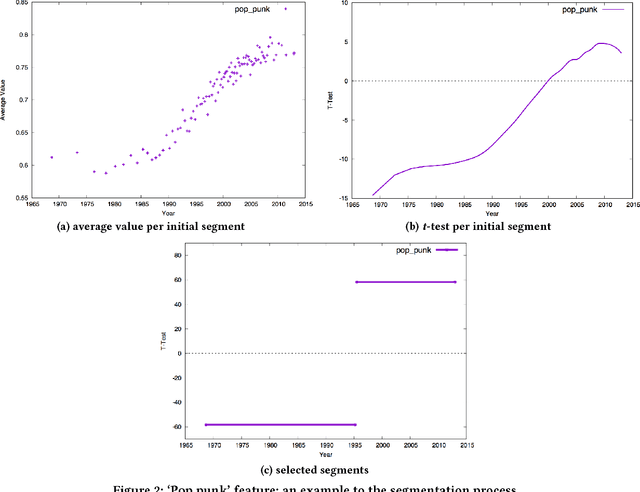
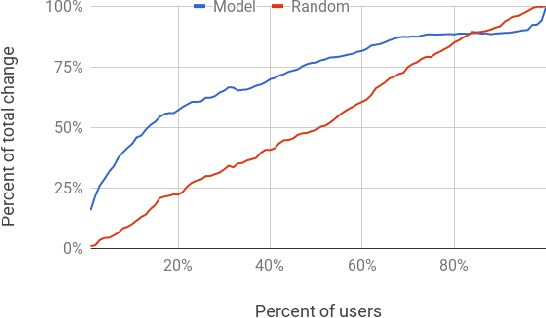
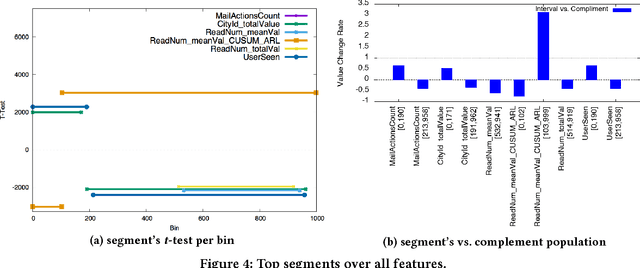
Interpretation of a machine learning induced models is critical for feature engineering, debugging, and, arguably, compliance. Yet, best of breed machine learning models tend to be very complex. This paper presents a method for model interpretation which has the main benefit that the simple interpretations it provides are always grounded in actual sets of learning examples. The method is validated on the task of interpreting a complex regression model in the context of both an academic problem -- predicting the year in which a song was recorded and an industrial one -- predicting mail user churn.