 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Generalized Skew Spectrum of Graphs
May 29, 2025



This paper proposes a family of permutation-invariant graph embeddings, generalizing the Skew Spectrum of graphs of Kondor & Borgwardt (2008). Grounded in group theory and harmonic analysis, our method introduces a new class of graph invariants that are isomorphism-invariant and capable of embedding richer graph structures - including attributed graphs, multilayer graphs, and hypergraphs - which the Skew Spectrum could not handle. Our generalization further defines a family of functions that enables a trade-off between computational complexity and expressivity. By applying generalization-preserving heuristics to this family, we improve the Skew Spectrum's expressivity at the same computational cost. We formally prove the invariance of our generalization, demonstrate its improved expressiveness through experiments, and discuss its efficient computation.
Do you know what q-means?
Aug 18, 2023Clustering is one of the most important tools for analysis of large datasets, and perhaps the most popular clustering algorithm is Lloyd's iteration for $k$-means. This iteration takes $N$ vectors $v_1,\dots,v_N\in\mathbb{R}^d$ and outputs $k$ centroids $c_1,\dots,c_k\in\mathbb{R}^d$; these partition the vectors into clusters based on which centroid is closest to a particular vector. We present an overall improved version of the "$q$-means" algorithm, the quantum algorithm originally proposed by Kerenidis, Landman, Luongo, and Prakash (2019) which performs $\varepsilon$-$k$-means, an approximate version of $k$-means clustering. This algorithm does not rely on the quantum linear algebra primitives of prior work, instead only using its QRAM to prepare and measure simple states based on the current iteration's clusters. The time complexity is $O\big(\frac{k^{2}}{\varepsilon^2}(\sqrt{k}d + \log(Nd))\big)$ and maintains the polylogarithmic dependence on $N$ while improving the dependence on most of the other parameters. We also present a "dequantized" algorithm for $\varepsilon$-$k$-means which runs in $O\big(\frac{k^{2}}{\varepsilon^2}(kd + \log(Nd))\big)$ time. Notably, this classical algorithm matches the polylogarithmic dependence on $N$ attained by the quantum algorithms.
Quantum Algorithms for Data Representation and Analysis
Apr 19, 2021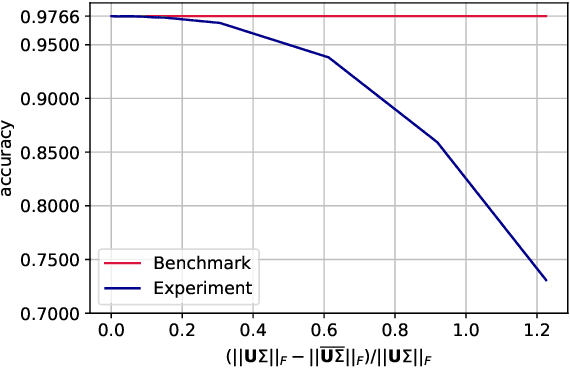
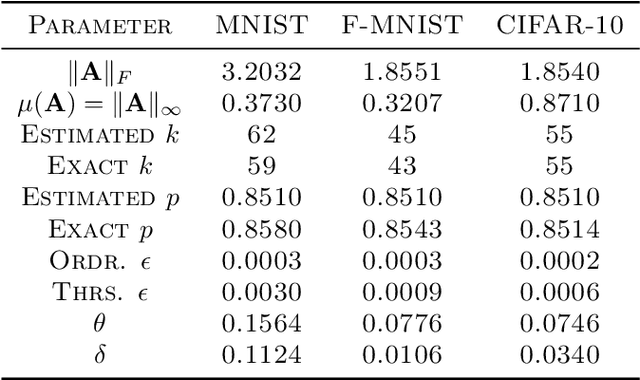
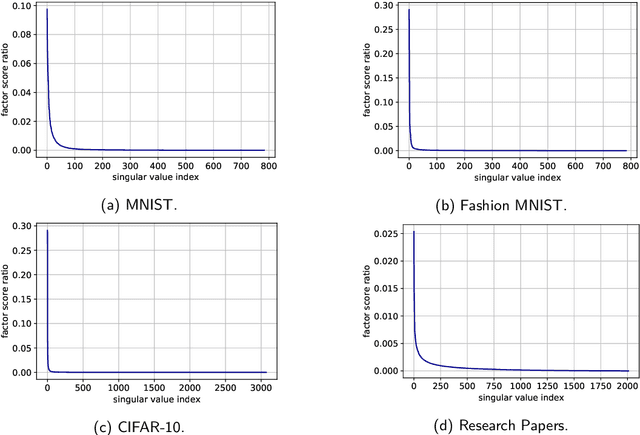
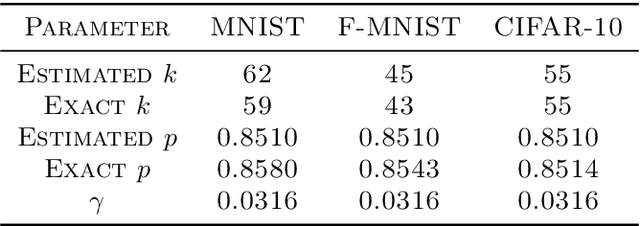
We narrow the gap between previous literature on quantum linear algebra and useful data analysis on a quantum computer, providing quantum procedures that speed-up the solution of eigenproblems for data representation in machine learning. The power and practical use of these subroutines is shown through new quantum algorithms, sublinear in the input matrix's size, for principal component analysis, correspondence analysis, and latent semantic analysis. We provide a theoretical analysis of the run-time and prove tight bounds on the randomized algorithms' error. We run experiments on multiple datasets, simulating PCA's dimensionality reduction for image classification with the novel routines. The results show that the run-time parameters that do not depend on the input's size are reasonable and that the error on the computed model is small, allowing for competitive classification performances.
Quantum algorithms for spectral sums
Nov 12, 2020
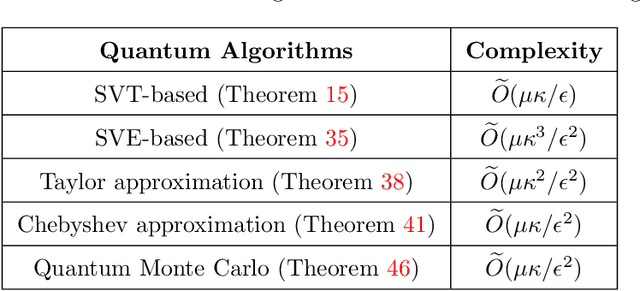
We propose and analyze new quantum algorithms for estimating the most common spectral sums of symmetric positive definite (SPD) matrices. For a function $f$ and a matrix $A \in \mathbb{R}^{n\times n}$, the spectral sum is defined as $S_f(A) :=\text{Tr}[f(A)] = \sum_j f(\lambda_j)$, where $\lambda_j$ are the eigenvalues. Examples of spectral sums are the von Neumann entropy, the trace of inverse, the log-determinant, and the Schatten-$p$ norm, where the latter does not require the matrix to be SPD. The fastest classical randomized algorithms estimate these quantities have a runtime that depends at least linearly on the number of nonzero components of the matrix. Assuming quantum access to the matrix, our algorithms are sub-linear in the matrix size, and depend at most quadratically on other quantities, like the condition number and the approximation error, and thus can compete with most of the randomized and distributed classical algorithms proposed in recent literature. These algorithms can be used as subroutines for solving many practical problems, for which the estimation of a spectral sum often represents a computational bottleneck.
Quantum Expectation-Maximization for Gaussian Mixture Models
Aug 19, 2019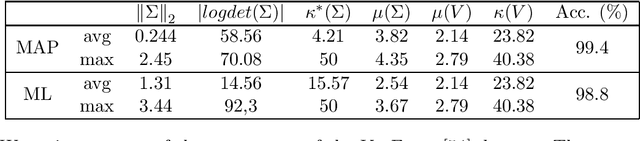
The Expectation-Maximization (EM) algorithm is a fundamental tool in unsupervised machine learning. It is often used as an efficient way to solve Maximum Likelihood (ML) estimation problems, especially for models with latent variables. It is also the algorithm of choice to fit mixture models: generative models that represent unlabelled points originating from $k$ different processes, as samples from $k$ multivariate distributions. In this work we define and use a quantum version of EM to fit a Gaussian Mixture Model. Given quantum access to a dataset of $n$ vectors of dimension $d$, our algorithm has convergence and precision guarantees similar to the classical algorithm, but the runtime is only polylogarithmic in the number of elements in the training set, and is polynomial in other parameters - as the dimension of the feature space, and the number of components in the mixture. We generalize further the algorithm in two directions. First, we show how to fit any mixture model of probability distributions in the exponential family. Then, we show how to use this algorithm to compute the Maximum a Posteriori (MAP) estimate of a mixture model: the Bayesian approach to likelihood estimation problems. We discuss the performance of the algorithm on datasets that are expected to be classified successfully by those algorithms, arguing that on those cases we can give strong guarantees on the runtime.
q-means: A quantum algorithm for unsupervised machine learning
Dec 11, 2018


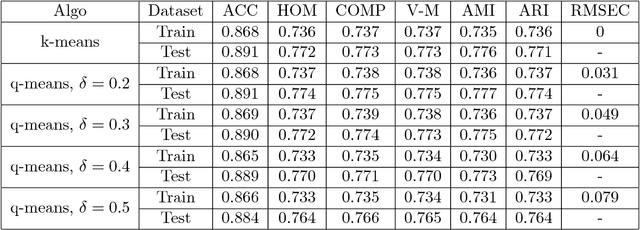
Quantum machine learning is one of the most promising applications of a full-scale quantum computer. Over the past few years, many quantum machine learning algorithms have been proposed that can potentially offer considerable speedups over the corresponding classical algorithms. In this paper, we introduce q-means, a new quantum algorithm for clustering which is a canonical problem in unsupervised machine learning. The $q$-means algorithm has convergence and precision guarantees similar to $k$-means, and it outputs with high probability a good approximation of the $k$ cluster centroids like the classical algorithm. Given a dataset of $N$ $d$-dimensional vectors $v_i$ (seen as a matrix $V \in \mathbb{R}^{N \times d})$ stored in QRAM, the running time of q-means is $\widetilde{O}\left( k d \frac{\eta}{\delta^2}\kappa(V)(\mu(V) + k \frac{\eta}{\delta}) + k^2 \frac{\eta^{1.5}}{\delta^2} \kappa(V)\mu(V) \right)$ per iteration, where $\kappa(V)$ is the condition number, $\mu(V)$ is a parameter that appears in quantum linear algebra procedures and $\eta = \max_{i} ||v_{i}||^{2}$. For a natural notion of well-clusterable datasets, the running time becomes $\widetilde{O}\left( k^2 d \frac{\eta^{2.5}}{\delta^3} + k^{2.5} \frac{\eta^2}{\delta^3} \right)$ per iteration, which is linear in the number of features $d$, and polynomial in the rank $k$, the maximum square norm $\eta$ and the error parameter $\delta$. Both running times are only polylogarithmic in the number of datapoints $N$. Our algorithm provides substantial savings compared to the classical $k$-means algorithm that runs in time $O(kdN)$ per iteration, particularly for the case of large datasets.
Quantum classification of the MNIST dataset via Slow Feature Analysis
Jun 12, 2018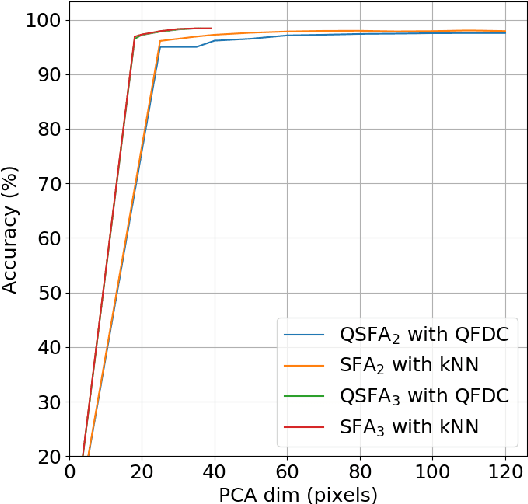
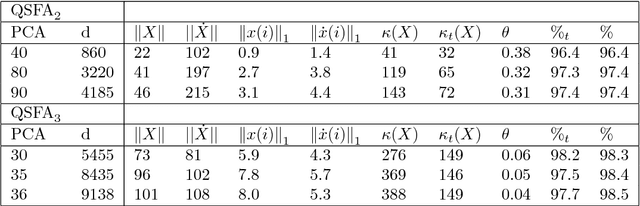
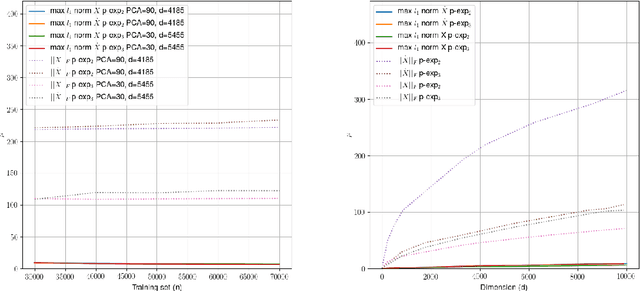
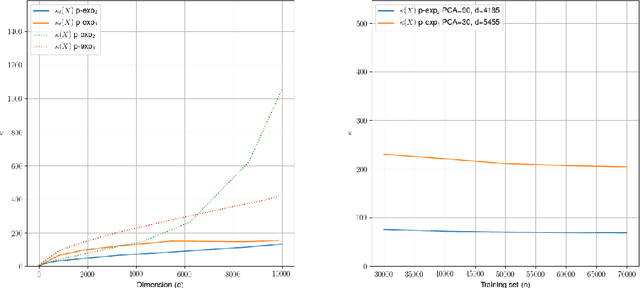
Quantum machine learning carries the promise to revolutionize information and communication technologies. While a number of quantum algorithms with potential exponential speedups have been proposed already, it is quite difficult to provide convincing evidence that quantum computers with quantum memories will be in fact useful to solve real-world problems. Our work makes considerable progress towards this goal. We design quantum techniques for Dimensionality Reduction and for Classification, and combine them to provide an efficient and high accuracy quantum classifier that we test on the MNIST dataset. More precisely, we propose a quantum version of Slow Feature Analysis (QSFA), a dimensionality reduction technique that maps the dataset in a lower dimensional space where we can apply a novel quantum classification procedure, the Quantum Frobenius Distance (QFD). We simulate the quantum classifier (including errors) and show that it can provide classification of the MNIST handwritten digit dataset, a widely used dataset for benchmarking classification algorithms, with $98.5\%$ accuracy, similar to the classical case. The running time of the quantum classifier is polylogarithmic in the dimension and number of data points. We also provide evidence that the other parameters on which the running time depends (condition number, Frobenius norm, error threshold, etc.) scale favorably in practice, thus ascertaining the efficiency of our algorithm.