 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnnatural Language Processing: Bridging the Gap Between Synthetic and Natural Language Data
Apr 28, 2020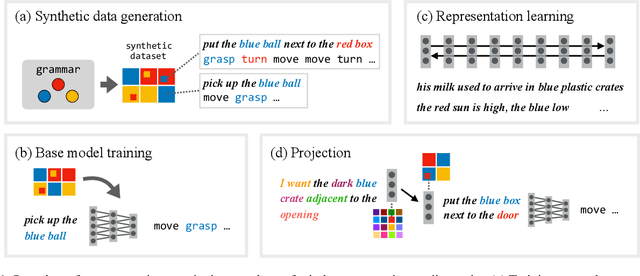
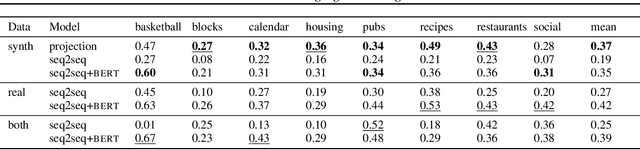
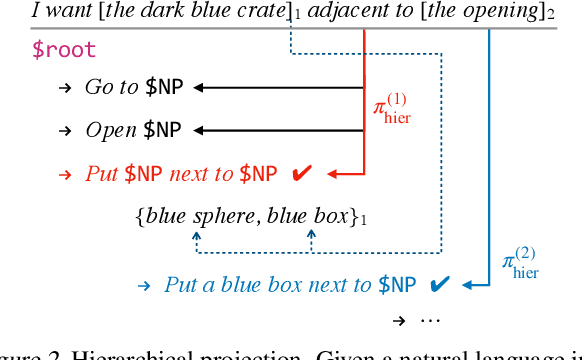

Large, human-annotated datasets are central to the development of natural language processing models. Collecting these datasets can be the most challenging part of the development process. We address this problem by introducing a general purpose technique for ``simulation-to-real'' transfer in language understanding problems with a delimited set of target behaviors, making it possible to develop models that can interpret natural utterances without natural training data. We begin with a synthetic data generation procedure, and train a model that can accurately interpret utterances produced by the data generator. To generalize to natural utterances, we automatically find projections of natural language utterances onto the support of the synthetic language, using learned sentence embeddings to define a distance metric. With only synthetic training data, our approach matches or outperforms state-of-the-art models trained on natural language data in several domains. These results suggest that simulation-to-real transfer is a practical framework for developing NLP applications, and that improved models for transfer might provide wide-ranging improvements in downstream tasks.
High-Accuracy Low-Precision Training
Mar 09, 2018
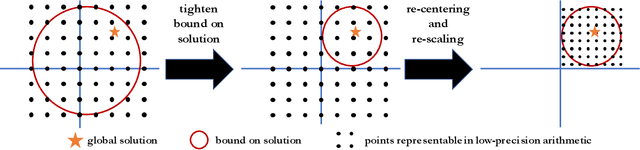
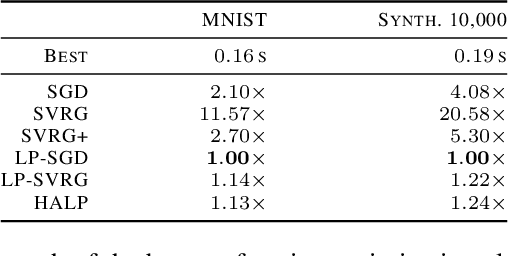
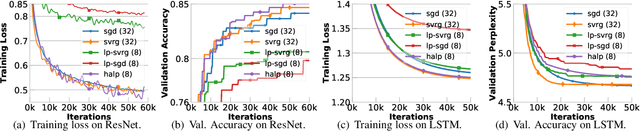
Low-precision computation is often used to lower the time and energy cost of machine learning, and recently hardware accelerators have been developed to support it. Still, it has been used primarily for inference - not training. Previous low-precision training algorithms suffered from a fundamental tradeoff: as the number of bits of precision is lowered, quantization noise is added to the model, which limits statistical accuracy. To address this issue, we describe a simple low-precision stochastic gradient descent variant called HALP. HALP converges at the same theoretical rate as full-precision algorithms despite the noise introduced by using low precision throughout execution. The key idea is to use SVRG to reduce gradient variance, and to combine this with a novel technique called bit centering to reduce quantization error. We show that on the CPU, HALP can run up to $4 \times$ faster than full-precision SVRG and can match its convergence trajectory. We implemented HALP in TensorQuant, and show that it exceeds the validation performance of plain low-precision SGD on two deep learning tasks.