 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-Answer Prediction in Q&A Sites Using User Information
Dec 15, 2022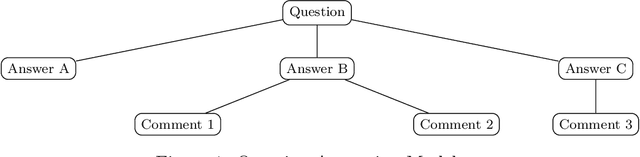

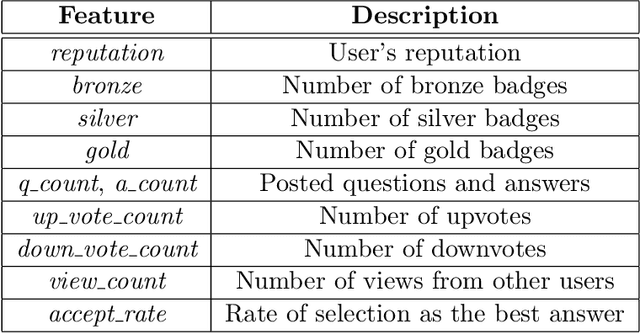
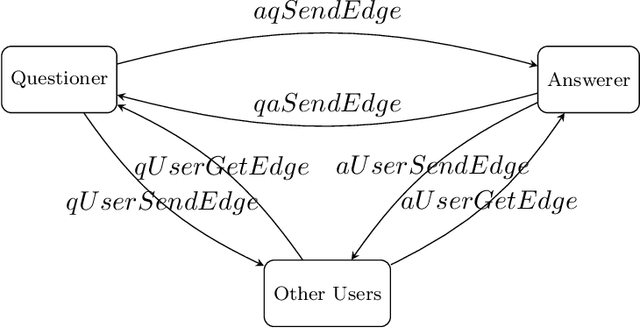
Community Question Answering (CQA) sites have spread and multiplied significantly in recent years. Sites like Reddit, Quora, and Stack Exchange are becoming popular amongst people interested in finding answers to diverse questions. One practical way of finding such answers is automatically predicting the best candidate given existing answers and comments. Many studies were conducted on answer prediction in CQA but with limited focus on using the background information of the questionnaires. We address this limitation using a novel method for predicting the best answers using the questioner's background information and other features, such as the textual content or the relationships with other participants. Our answer classification model was trained using the Stack Exchange dataset and validated using the Area Under the Curve (AUC) metric. The experimental results show that the proposed method complements previous methods by pointing out the importance of the relationships between users, particularly throughout the level of involvement in different communities on Stack Exchange. Furthermore, we point out that there is little overlap between user-relation information and the information represented by the shallow text features and the meta-features, such as time differences.
CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars
Dec 01, 2022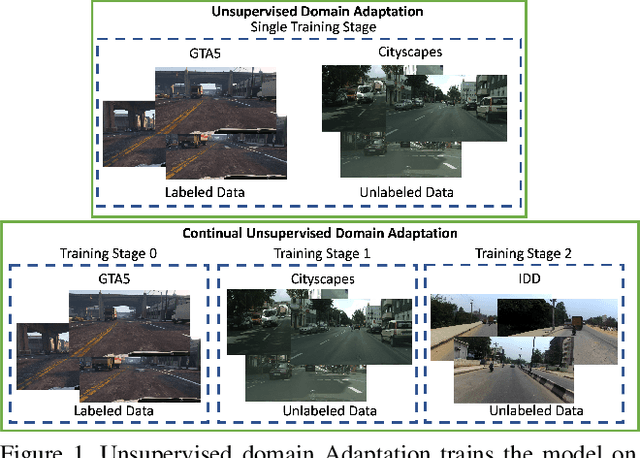
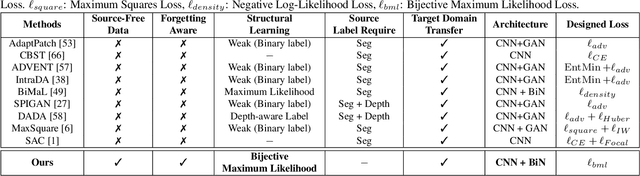
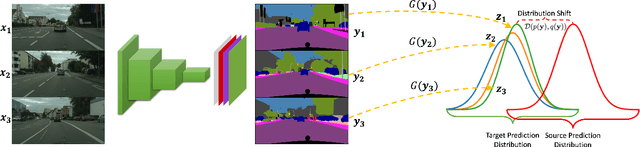
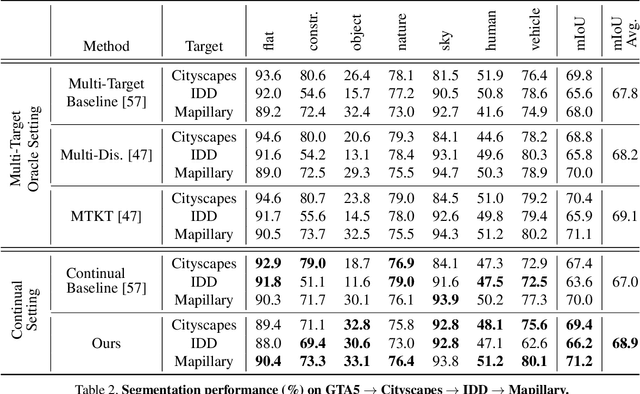
Although unsupervised domain adaptation methods have achieved remarkable performance in semantic scene segmentation in visual perception for self-driving cars, these approaches remain impractical in real-world use cases. In practice, the segmentation models may encounter new data that have not been seen yet. Also, the previous data training of segmentation models may be inaccessible due to privacy problems. Therefore, to address these problems, in this work, we propose a Continual Unsupervised Domain Adaptation (CONDA) approach that allows the model to continuously learn and adapt with respect to the presence of the new data. Moreover, our proposed approach is designed without the requirement of accessing previous training data. To avoid the catastrophic forgetting problem and maintain the performance of the segmentation models, we present a novel Bijective Maximum Likelihood loss to impose the constraint of predicted segmentation distribution shifts. The experimental results on the benchmark of continual unsupervised domain adaptation have shown the advanced performance of the proposed CONDA method.
Fairness based Multi-Preference Resource Allocation in Decentralised Open Markets
Sep 01, 2021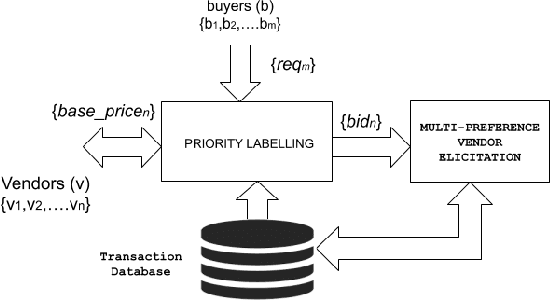
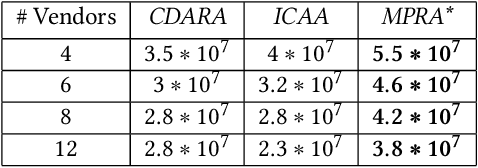
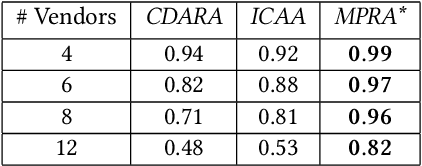
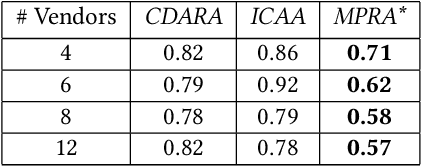
In this work, we focus on resource allocation in a decentralised open market. In decentralised open markets consists of multiple vendors and multiple dynamically-arriving buyers, thus makes the market complex and dynamic. Because, in these markets, negotiations among vendors and buyers take place over multiple conflicting issues such as price, scalability, robustness, delay, etc. As a result, optimising the resource allocation in such open markets becomes directly dependent on two key decisions, which are; incorporating a different kind of buyers' preferences, and fairness based vendor elicitation strategy. Towards this end, in this work, we propose a three-step resource allocation approach that employs a reverse-auction paradigm. At the first step, priority label is attached to each bidding vendor based on the proposed priority mechanism. Then, at the second step, the preference score is calculated for all the different kinds of preferences of the buyers. Finally, at the third step, based on the priority label of the vendor and the preference score winner is determined. Finally, we compare the proposed approach with two state-of-the-art resource pricing and allocation strategies. The experimental results show that the proposed approach outperforms the other two resource allocation approaches in terms of the independent utilities of buyers and the overall utility of the open market.
Federated Learning Versus Classical Machine Learning: A Convergence Comparison
Jul 22, 2021



In the past few decades, machine learning has revolutionized data processing for large scale applications. Simultaneously, increasing privacy threats in trending applications led to the redesign of classical data training models. In particular, classical machine learning involves centralized data training, where the data is gathered, and the entire training process executes at the central server. Despite significant convergence, this training involves several privacy threats on participants' data when shared with the central cloud server. To this end, federated learning has achieved significant importance over distributed data training. In particular, the federated learning allows participants to collaboratively train the local models on local data without revealing their sensitive information to the central cloud server. In this paper, we perform a convergence comparison between classical machine learning and federated learning on two publicly available datasets, namely, logistic-regression-MNIST dataset and image-classification-CIFAR-10 dataset. The simulation results demonstrate that federated learning achieves higher convergence within limited communication rounds while maintaining participants' anonymity. We hope that this research will show the benefits and help federated learning to be implemented widely.
Privacy Information Classification: A Hybrid Approach
Jan 27, 2021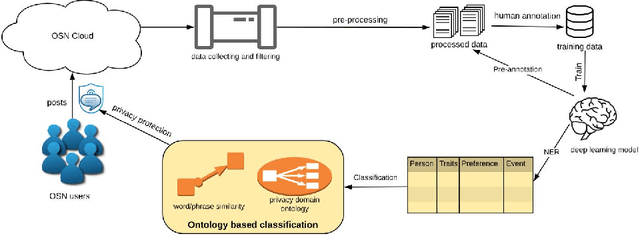
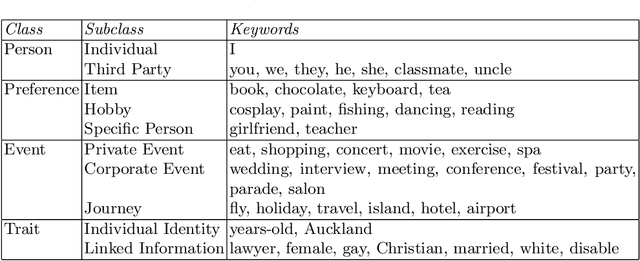
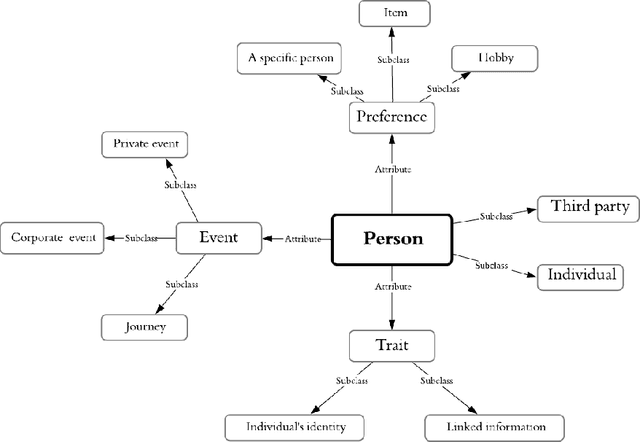
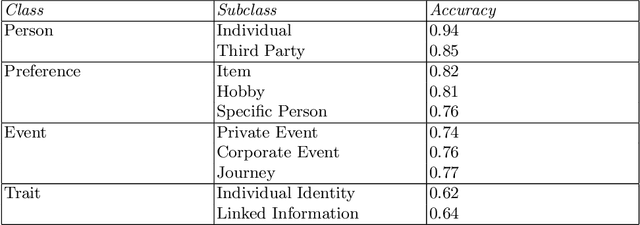
A large amount of information has been published to online social networks every day. Individual privacy-related information is also possibly disclosed unconsciously by the end-users. Identifying privacy-related data and protecting the online social network users from privacy leakage turn out to be significant. Under such a motivation, this study aims to propose and develop a hybrid privacy classification approach to detect and classify privacy information from OSNs. The proposed hybrid approach employs both deep learning models and ontology-based models for privacy-related information extraction. Extensive experiments are conducted to validate the proposed hybrid approach, and the empirical results demonstrate its superiority in assisting online social network users against privacy leakage.
Evaluating the Communication Efficiency in Federated Learning Algorithms
Apr 06, 2020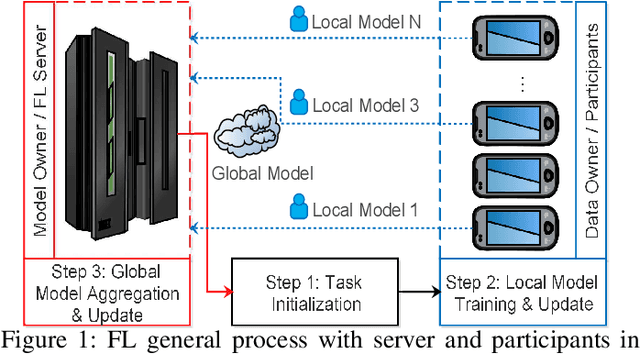
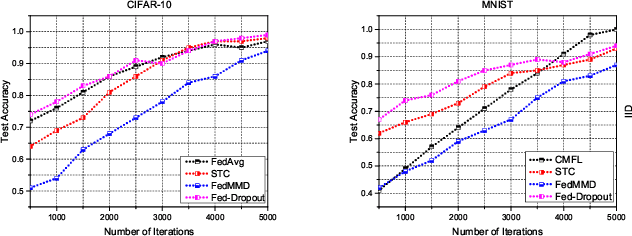
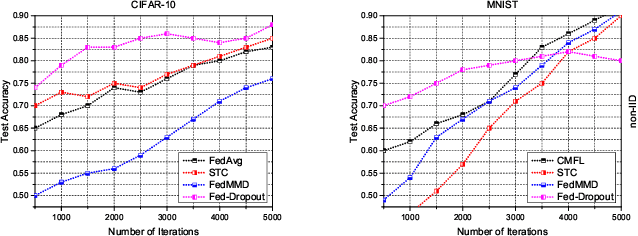
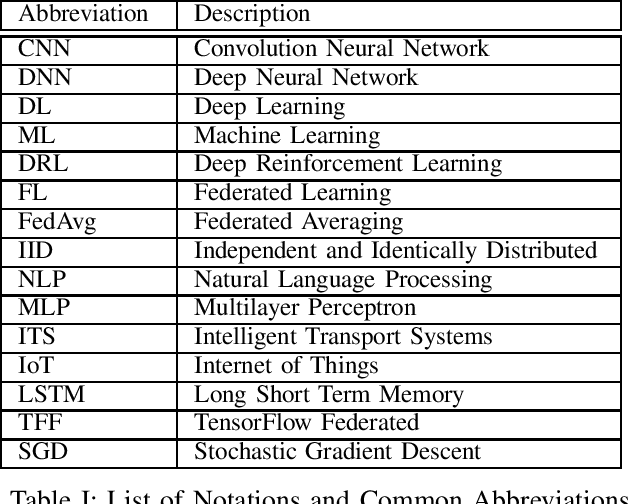
In the era of advanced technologies, mobile devices are equipped with computing and sensing capabilities that gather excessive amounts of data. These amounts of data are suitable for training different learning models. Cooperated with advancements in Deep Learning (DL), these learning models empower numerous useful applications, e.g., image processing, speech recognition, healthcare, vehicular network and many more. Traditionally, Machine Learning (ML) approaches require data to be centralised in cloud-based data-centres. However, this data is often large in quantity and privacy-sensitive which prevents logging into these data-centres for training the learning models. In turn, this results in critical issues of high latency and communication inefficiency. Recently, in light of new privacy legislations in many countries, the concept of Federated Learning (FL) has been introduced. In FL, mobile users are empowered to learn a global model by aggregating their local models, without sharing the privacy-sensitive data. Usually, these mobile users have slow network connections to the data-centre where the global model is maintained. Moreover, in a complex and large scale network, heterogeneous devices that have various energy constraints are involved. This raises the challenge of communication cost when implementing FL at large scale. To this end, in this research, we begin with the fundamentals of FL, and then, we highlight the recent FL algorithms and evaluate their communication efficiency with detailed comparisons. Furthermore, we propose a set of solutions to alleviate the existing FL problems both from communication perspective and privacy perspective.