 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMaL: Conditional Maximum Likelihood Approach to Self-supervised Domain Adaptation in Long-tail Semantic Segmentation
Apr 14, 2023



The research in self-supervised domain adaptation in semantic segmentation has recently received considerable attention. Although GAN-based methods have become one of the most popular approaches to domain adaptation, they have suffered from some limitations. They are insufficient to model both global and local structures of a given image, especially in small regions of tail classes. Moreover, they perform bad on the tail classes containing limited number of pixels or less training samples. In order to address these issues, we present a new self-supervised domain adaptation approach to tackle long-tail semantic segmentation in this paper. Firstly, a new metric is introduced to formulate long-tail domain adaptation in the segmentation problem. Secondly, a new Conditional Maximum Likelihood (CoMaL) approach in an autoregressive framework is presented to solve the problem of long-tail domain adaptation. Although other segmentation methods work under the pixel independence assumption, the long-tailed pixel distributions in CoMaL are generally solved in the context of structural dependency, as that is more realistic. Finally, the proposed method is evaluated on popular large-scale semantic segmentation benchmarks, i.e., "SYNTHIA to Cityscapes" and "GTA to Cityscapes", and outperforms the prior methods by a large margin in both the standard and the proposed evaluation protocols.
CONDA: Continual Unsupervised Domain Adaptation Learning in Visual Perception for Self-Driving Cars
Dec 01, 2022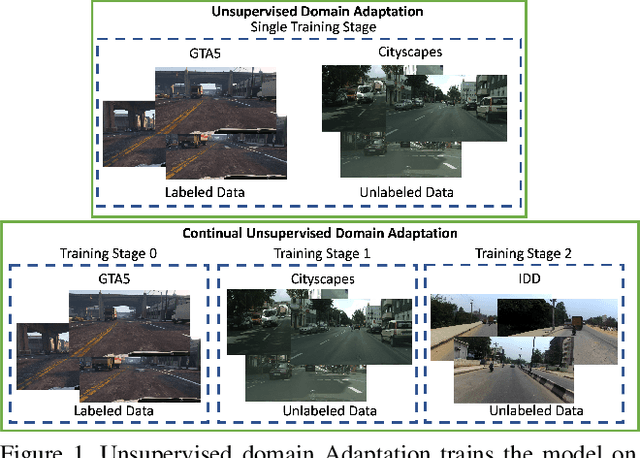
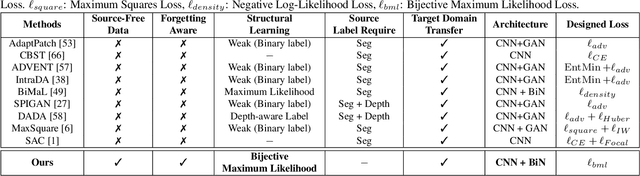
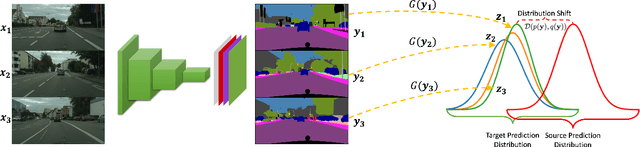
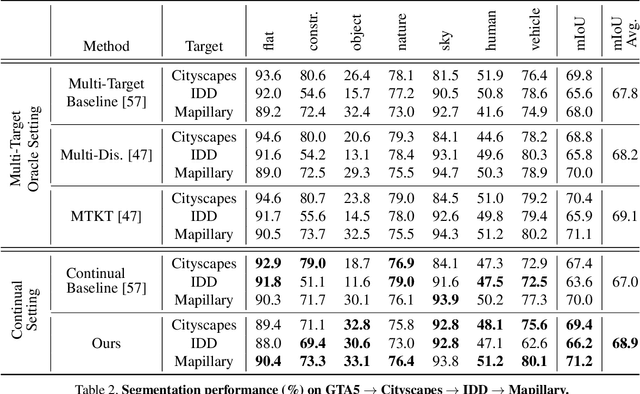
Although unsupervised domain adaptation methods have achieved remarkable performance in semantic scene segmentation in visual perception for self-driving cars, these approaches remain impractical in real-world use cases. In practice, the segmentation models may encounter new data that have not been seen yet. Also, the previous data training of segmentation models may be inaccessible due to privacy problems. Therefore, to address these problems, in this work, we propose a Continual Unsupervised Domain Adaptation (CONDA) approach that allows the model to continuously learn and adapt with respect to the presence of the new data. Moreover, our proposed approach is designed without the requirement of accessing previous training data. To avoid the catastrophic forgetting problem and maintain the performance of the segmentation models, we present a novel Bijective Maximum Likelihood loss to impose the constraint of predicted segmentation distribution shifts. The experimental results on the benchmark of continual unsupervised domain adaptation have shown the advanced performance of the proposed CONDA method.