 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest-Answer Prediction in Q&A Sites Using User Information
Paper and Code
Dec 15, 2022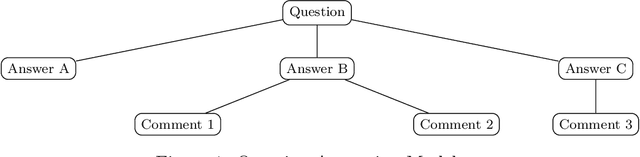

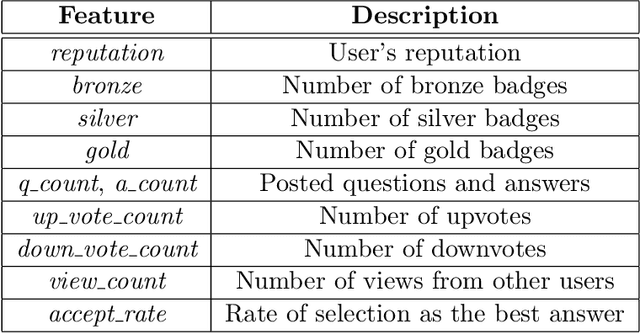
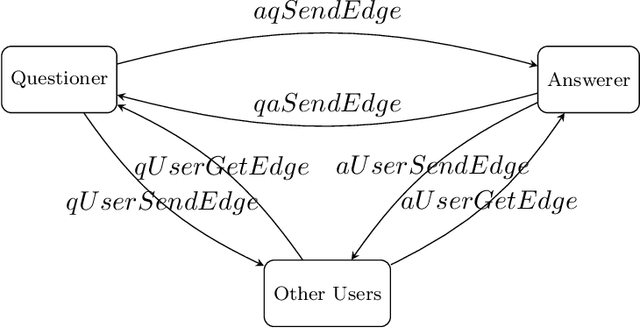
Community Question Answering (CQA) sites have spread and multiplied significantly in recent years. Sites like Reddit, Quora, and Stack Exchange are becoming popular amongst people interested in finding answers to diverse questions. One practical way of finding such answers is automatically predicting the best candidate given existing answers and comments. Many studies were conducted on answer prediction in CQA but with limited focus on using the background information of the questionnaires. We address this limitation using a novel method for predicting the best answers using the questioner's background information and other features, such as the textual content or the relationships with other participants. Our answer classification model was trained using the Stack Exchange dataset and validated using the Area Under the Curve (AUC) metric. The experimental results show that the proposed method complements previous methods by pointing out the importance of the relationships between users, particularly throughout the level of involvement in different communities on Stack Exchange. Furthermore, we point out that there is little overlap between user-relation information and the information represented by the shallow text features and the meta-features, such as time differences.