 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
Machine Learning-Based Prediction of Speech Arrest During Direct Cortical Stimulation Mapping
Sep 10, 2025Identifying cortical regions critical for speech is essential for safe brain surgery in or near language areas. While Electrical Stimulation Mapping (ESM) remains the clinical gold standard, it is invasive and time-consuming. To address this, we analyzed intracranial electrocorticographic (ECoG) data from 16 participants performing speech tasks and developed machine learning models to directly predict if the brain region underneath each ECoG electrode is critical. Ground truth labels indicating speech arrest were derived independently from Electrical Stimulation Mapping (ESM) and used to train classification models. Our framework integrates neural activity signals, anatomical region labels, and functional connectivity features to capture both local activity and network-level dynamics. We found that models combining region and connectivity features matched the performance of the full feature set, and outperformed models using either type alone. To classify each electrode, trial-level predictions were aggregated using an MLP applied to histogram-encoded scores. Our best-performing model, a trial-level RBF-kernel Support Vector Machine together with MLP-based aggregation, achieved strong accuracy on held-out participants (ROC-AUC: 0.87, PR-AUC: 0.57). These findings highlight the value of combining spatial and network information with non-linear modeling to improve functional mapping in presurgical evaluation.
A Scalable Pipeline for Estimating Verb Frame Frequencies Using Large Language Models
Jul 29, 2025We present an automated pipeline for estimating Verb Frame Frequencies (VFFs), the frequency with which a verb appears in particular syntactic frames. VFFs provide a powerful window into syntax in both human and machine language systems, but existing tools for calculating them are limited in scale, accuracy, or accessibility. We use large language models (LLMs) to generate a corpus of sentences containing 476 English verbs. Next, by instructing an LLM to behave like an expert linguist, we had it analyze the syntactic structure of the sentences in this corpus. This pipeline outperforms two widely used syntactic parsers across multiple evaluation datasets. Furthermore, it requires far fewer resources than manual parsing (the gold-standard), thereby enabling rapid, scalable VFF estimation. Using the LLM parser, we produce a new VFF database with broader verb coverage, finer-grained syntactic distinctions, and explicit estimates of the relative frequencies of structural alternates commonly studied in psycholinguistics. The pipeline is easily customizable and extensible to new verbs, syntactic frames, and even other languages. We present this work as a proof of concept for automated frame frequency estimation, and release all code and data to support future research.
AAD-LLM: Neural Attention-Driven Auditory Scene Understanding
Feb 24, 2025



Auditory foundation models, including auditory large language models (LLMs), process all sound inputs equally, independent of listener perception. However, human auditory perception is inherently selective: listeners focus on specific speakers while ignoring others in complex auditory scenes. Existing models do not incorporate this selectivity, limiting their ability to generate perception-aligned responses. To address this, we introduce Intention-Informed Auditory Scene Understanding (II-ASU) and present Auditory Attention-Driven LLM (AAD-LLM), a prototype system that integrates brain signals to infer listener attention. AAD-LLM extends an auditory LLM by incorporating intracranial electroencephalography (iEEG) recordings to decode which speaker a listener is attending to and refine responses accordingly. The model first predicts the attended speaker from neural activity, then conditions response generation on this inferred attentional state. We evaluate AAD-LLM on speaker description, speech transcription and extraction, and question answering in multitalker scenarios, with both objective and subjective ratings showing improved alignment with listener intention. By taking a first step toward intention-aware auditory AI, this work explores a new paradigm where listener perception informs machine listening, paving the way for future listener-centered auditory systems. Demo and code available: https://aad-llm.github.io.
GroupCDL: Interpretable Denoising and Compressed Sensing MRI via Learned Group-Sparsity and Circulant Attention
Jul 19, 2024



Nonlocal self-similarity within images has become an increasingly popular prior in deep-learning models. Despite their successful image restoration performance, such models remain largely uninterpretable due to their black-box construction. Our previous studies have shown that interpretable construction of a fully convolutional denoiser (CDLNet), with performance on par with state-of-the-art black-box counterparts, is achievable by unrolling a convolutional dictionary learning algorithm. In this manuscript, we seek an interpretable construction of a convolutional network with a nonlocal self-similarity prior that performs on par with black-box nonlocal models. We show that such an architecture can be effectively achieved by upgrading the L1 sparsity prior (soft-thresholding) of CDLNet to an image-adaptive group-sparsity prior (group-thresholding). The proposed learned group-thresholding makes use of nonlocal attention to perform spatially varying soft-thresholding on the latent representation. To enable effective training and inference on large images with global artifacts, we propose a novel circulant-sparse attention. We achieve competitive natural-image denoising performance compared to black-box nonlocal DNNs and transformers. The interpretable construction of our network allows for a straightforward extension to Compressed Sensing MRI (CS-MRI), yielding state-of-the-art performance. Lastly, we show robustness to noise-level mismatches between training and inference for denoising and CS-MRI reconstruction.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.
Fast and Interpretable Nonlocal Neural Networks for Image Denoising via Group-Sparse Convolutional Dictionary Learning
Jun 02, 2023



Nonlocal self-similarity within natural images has become an increasingly popular prior in deep-learning models. Despite their successful image restoration performance, such models remain largely uninterpretable due to their black-box construction. Our previous studies have shown that interpretable construction of a fully convolutional denoiser (CDLNet), with performance on par with state-of-the-art black-box counterparts, is achievable by unrolling a dictionary learning algorithm. In this manuscript, we seek an interpretable construction of a convolutional network with a nonlocal self-similarity prior that performs on par with black-box nonlocal models. We show that such an architecture can be effectively achieved by upgrading the $\ell 1$ sparsity prior of CDLNet to a weighted group-sparsity prior. From this formulation, we propose a novel sliding-window nonlocal operation, enabled by sparse array arithmetic. In addition to competitive performance with black-box nonlocal DNNs, we demonstrate the proposed sliding-window sparse attention enables inference speeds greater than an order of magnitude faster than its competitors.
Reconstructing Speech Stimuli From Human Auditory Cortex Activity Using a WaveNet Approach
Nov 08, 2018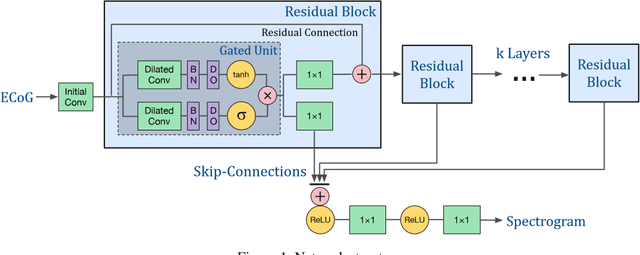
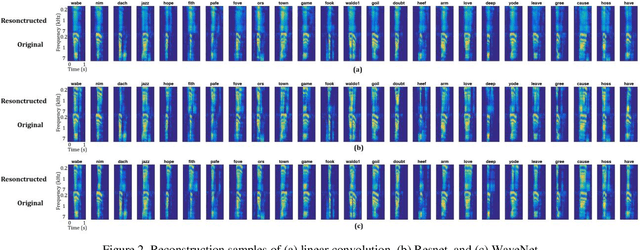
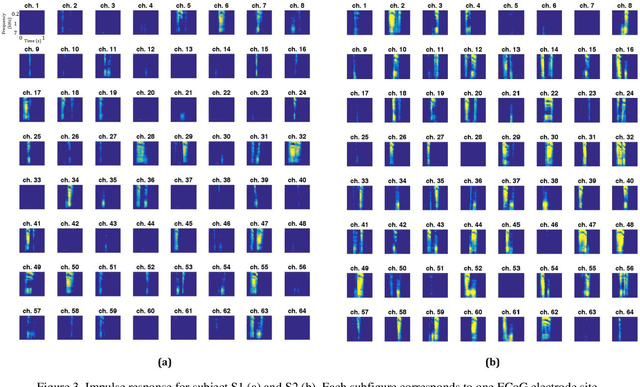

The superior temporal gyrus (STG) region of cortex critically contributes to speech recognition. In this work, we show that a proposed WaveNet, with limited available data, is able to reconstruct speech stimuli from STG intracranial recordings. We further investigate the impulse response of the fitted model for each recording electrode and observe phoneme level temporospectral tuning properties for the recorded area of cortex. This discovery is consistent with previous studies implicating the posterior STG (pSTG) in a phonetic representation of speech and provides detailed acoustic features that certain electrode sites possibly extract during speech recognition.