 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy MRI Reconstruction via MAP Estimation with an Implicit Deep-Denoiser Prior
Nov 15, 2025Accelerating magnetic resonance imaging (MRI) remains challenging, particularly under realistic acquisition noise. While diffusion models have recently shown promise for reconstructing undersampled MRI data, many approaches lack an explicit link to the underlying MRI physics, and their parameters are sensitive to measurement noise, limiting their reliability in practice. We introduce Implicit-MAP (ImMAP), a diffusion-based reconstruction framework that integrates the acquisition noise model directly into a maximum a posteriori (MAP) formulation. Specifically, we build on the stochastic ascent method of Kadkhodaie et al. and generalize it to handle MRI encoding operators and realistic measurement noise. Across both simulated and real noisy datasets, ImMAP consistently outperforms state-of-the-art deep learning (LPDSNet) and diffusion-based (DDS) methods. By clarifying the practical behavior and limitations of diffusion models under realistic noise conditions, ImMAP establishes a more reliable and interpretable
Machine Learning-Based Prediction of Speech Arrest During Direct Cortical Stimulation Mapping
Sep 10, 2025Identifying cortical regions critical for speech is essential for safe brain surgery in or near language areas. While Electrical Stimulation Mapping (ESM) remains the clinical gold standard, it is invasive and time-consuming. To address this, we analyzed intracranial electrocorticographic (ECoG) data from 16 participants performing speech tasks and developed machine learning models to directly predict if the brain region underneath each ECoG electrode is critical. Ground truth labels indicating speech arrest were derived independently from Electrical Stimulation Mapping (ESM) and used to train classification models. Our framework integrates neural activity signals, anatomical region labels, and functional connectivity features to capture both local activity and network-level dynamics. We found that models combining region and connectivity features matched the performance of the full feature set, and outperformed models using either type alone. To classify each electrode, trial-level predictions were aggregated using an MLP applied to histogram-encoded scores. Our best-performing model, a trial-level RBF-kernel Support Vector Machine together with MLP-based aggregation, achieved strong accuracy on held-out participants (ROC-AUC: 0.87, PR-AUC: 0.57). These findings highlight the value of combining spatial and network information with non-linear modeling to improve functional mapping in presurgical evaluation.
GroupCDL: Interpretable Denoising and Compressed Sensing MRI via Learned Group-Sparsity and Circulant Attention
Jul 19, 2024



Nonlocal self-similarity within images has become an increasingly popular prior in deep-learning models. Despite their successful image restoration performance, such models remain largely uninterpretable due to their black-box construction. Our previous studies have shown that interpretable construction of a fully convolutional denoiser (CDLNet), with performance on par with state-of-the-art black-box counterparts, is achievable by unrolling a convolutional dictionary learning algorithm. In this manuscript, we seek an interpretable construction of a convolutional network with a nonlocal self-similarity prior that performs on par with black-box nonlocal models. We show that such an architecture can be effectively achieved by upgrading the L1 sparsity prior (soft-thresholding) of CDLNet to an image-adaptive group-sparsity prior (group-thresholding). The proposed learned group-thresholding makes use of nonlocal attention to perform spatially varying soft-thresholding on the latent representation. To enable effective training and inference on large images with global artifacts, we propose a novel circulant-sparse attention. We achieve competitive natural-image denoising performance compared to black-box nonlocal DNNs and transformers. The interpretable construction of our network allows for a straightforward extension to Compressed Sensing MRI (CS-MRI), yielding state-of-the-art performance. Lastly, we show robustness to noise-level mismatches between training and inference for denoising and CS-MRI reconstruction.
Fast and Interpretable Nonlocal Neural Networks for Image Denoising via Group-Sparse Convolutional Dictionary Learning
Jun 02, 2023



Nonlocal self-similarity within natural images has become an increasingly popular prior in deep-learning models. Despite their successful image restoration performance, such models remain largely uninterpretable due to their black-box construction. Our previous studies have shown that interpretable construction of a fully convolutional denoiser (CDLNet), with performance on par with state-of-the-art black-box counterparts, is achievable by unrolling a dictionary learning algorithm. In this manuscript, we seek an interpretable construction of a convolutional network with a nonlocal self-similarity prior that performs on par with black-box nonlocal models. We show that such an architecture can be effectively achieved by upgrading the $\ell 1$ sparsity prior of CDLNet to a weighted group-sparsity prior. From this formulation, we propose a novel sliding-window nonlocal operation, enabled by sparse array arithmetic. In addition to competitive performance with black-box nonlocal DNNs, we demonstrate the proposed sliding-window sparse attention enables inference speeds greater than an order of magnitude faster than its competitors.
Gabor is Enough: Interpretable Deep Denoising with a Gabor Synthesis Dictionary Prior
Apr 23, 2022



Image processing neural networks, natural and artificial, have a long history with orientation-selectivity, often described mathematically as Gabor filters. Gabor-like filters have been observed in the early layers of CNN classifiers and even throughout low-level image processing networks. In this work, we take this observation to the extreme and explicitly constrain the filters of a natural-image denoising CNN to be learned 2D real Gabor filters. Surprisingly, we find that the proposed network (GDLNet) can achieve near state-of-the-art denoising performance amongst popular fully convolutional neural networks, with only a fraction of the learned parameters. We further verify that this parameterization maintains the noise-level generalization (training vs. inference mismatch) characteristics of the base network, and investigate the contribution of individual Gabor filter parameters to the performance of the denoiser. We present positive findings for the interpretation of dictionary learning networks as performing accelerated sparse-coding via the importance of untied learned scale parameters between network layers. Our network's success suggests that representations used by low-level image processing CNNs can be as simple and interpretable as Gabor filterbanks.
CDLNet: Noise-Adaptive Convolutional Dictionary Learning Network for Blind Denoising and Demosaicing
Dec 08, 2021

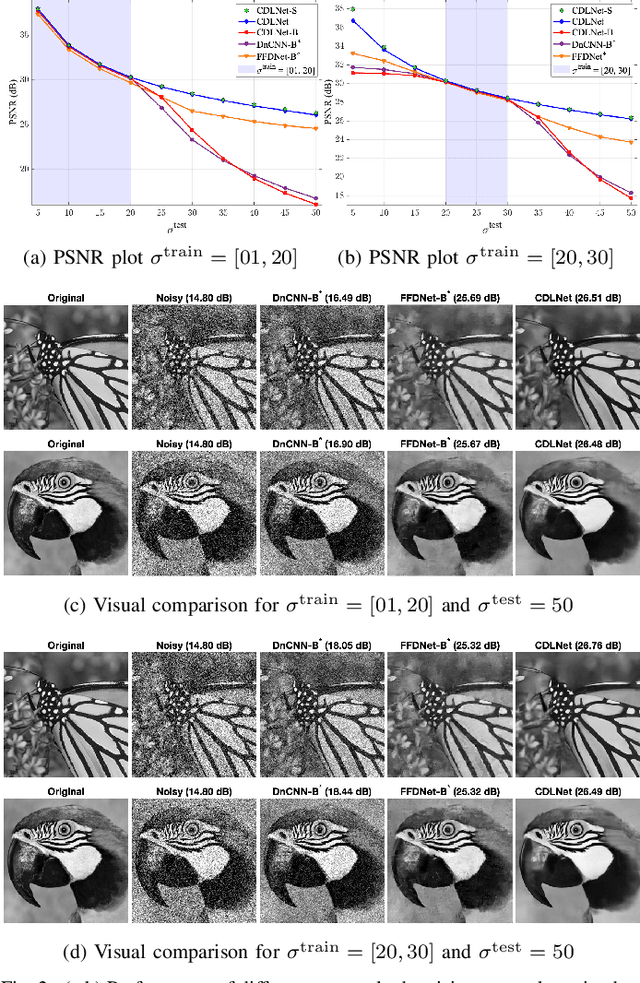

Deep learning based methods hold state-of-the-art results in low-level image processing tasks, but remain difficult to interpret due to their black-box construction. Unrolled optimization networks present an interpretable alternative to constructing deep neural networks by deriving their architecture from classical iterative optimization methods without use of tricks from the standard deep learning tool-box. So far, such methods have demonstrated performance close to that of state-of-the-art models while using their interpretable construction to achieve a comparably low learned parameter count. In this work, we propose an unrolled convolutional dictionary learning network (CDLNet) and demonstrate its competitive denoising and joint denoising and demosaicing (JDD) performance both in low and high parameter count regimes. Specifically, we show that the proposed model outperforms state-of-the-art fully convolutional denoising and JDD models when scaled to a similar parameter count. In addition, we leverage the model's interpretable construction to propose a noise-adaptive parameterization of thresholds in the network that enables state-of-the-art blind denoising performance, and near perfect generalization on noise-levels unseen during training. Furthermore, we show that such performance extends to the JDD task and unsupervised learning.
CDLNet: Robust and Interpretable Denoising Through Deep Convolutional Dictionary Learning
Mar 05, 2021

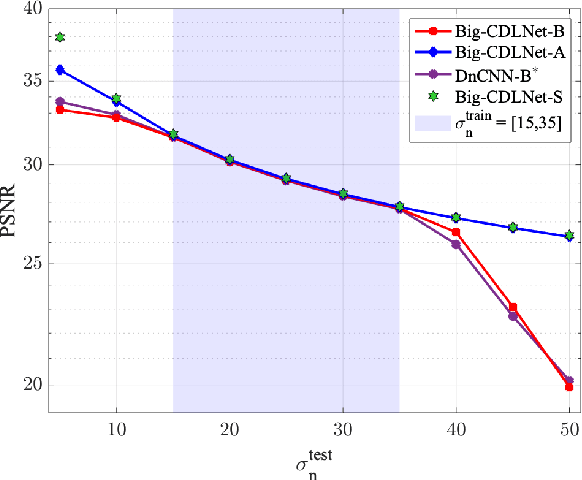

Deep learning based methods hold state-of-the-art results in image denoising, but remain difficult to interpret due to their construction from poorly understood building blocks such as batch-normalization, residual learning, and feature domain processing. Unrolled optimization networks propose an interpretable alternative to constructing deep neural networks by deriving their architecture from classical iterative optimization methods, without use of tricks from the standard deep learning tool-box. So far, such methods have demonstrated performance close to that of state-of-the-art models while using their interpretable construction to achieve a comparably low learned parameter count. In this work, we propose an unrolled convolutional dictionary learning network (CDLNet) and demonstrate its competitive denoising performance in both low and high parameter count regimes. Specifically, we show that the proposed model outperforms the state-of-the-art denoising models when scaled to similar parameter count. In addition, we leverage the model's interpretable construction to propose an augmentation of the network's thresholds that enables state-of-the-art blind denoising performance and near-perfect generalization on noise-levels unseen during training.
Masked-RPCA: Sparse and Low-rank Decomposition Under Overlaying Model and Application to Moving Object Detection
Sep 17, 2019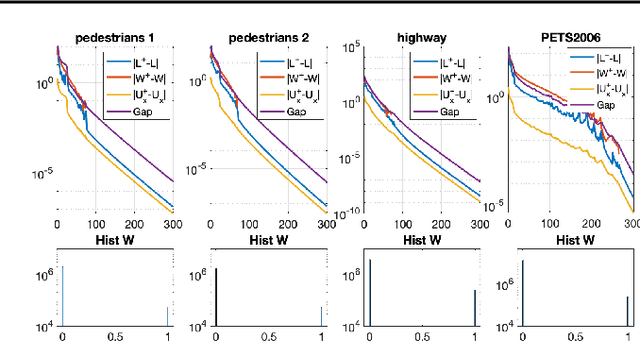
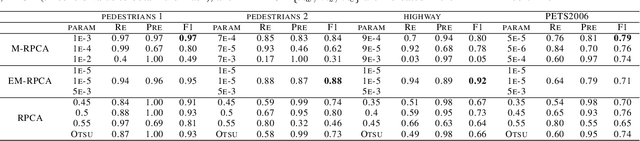


Foreground detection in a given video sequence is a pivotal step in many computer vision applications such as video surveillance system. Robust Principal Component Analysis (RPCA) performs low-rank and sparse decomposition and accomplishes such a task when the background is stationary and the foreground is dynamic and relatively small. A fundamental issue with RPCA is the assumption that the low-rank and sparse components are added at each element, whereas in reality, the moving foreground is overlaid on the background. We propose the representation via masked decomposition (i.e. an overlaying model) where each element either belongs to the low-rank or the sparse component, decided by a mask. We propose the Masked-RPCA algorithm to recover the mask and the low-rank components simultaneously, utilizing linearizing and alternating direction techniques. We further extend our formulation to be robust to dynamic changes in the background and enforce spatial connectivity in the foreground component. Our study shows significant improvement of the detected mask compared to post-processing on the sparse component obtained by other frameworks.