 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Hybrid Cross-Attention Fusion for Audio-Visual Event Recognition
Jun 02, 2026Audio-Visual Event Recognition (AVER) is essential for intelligent urban monitoring systems, where robust multimodal understanding of complex environments is required. This paper proposes a stable hybrid cross-attention fusion framework for audio-visual event recognition in smart urban environments. The proposed architecture combines pretrained Video Masked Autoencoder (VideoMAE) and Audio Spectrogram Transformer (AST) representations with FiLM-based audio conditioning, bidirectional cross-attention fusion, multimodal Transformer encoding, and modality-temporal attention. To improve computational efficiency and training stability, frozen pretrained backbones and cached feature extraction are employed. Extensive experiments on the AVE dataset show that the proposed framework achieves the highest average performance among the evaluated unimodal and multimodal baselines across multiple evaluation metrics, obtaining a best validation accuracy of 91.74% and a test accuracy of 83.85 plus/minus 1.40% over five independent runs. The results indicate that the proposed hybrid fusion strategy effectively captures complementary audio-visual information and provides robust multimodal representation learning for challenging realworld urban monitoring scenarios.
Robust Adaptive Backstepping Impedance Control of Robots in Unknown Environments
Apr 10, 2026This paper presents a Robust Adaptive Backstepping Impedance Control (RABIC) strategy for robots operating in contact-rich and uncertain environments. The proposed control strategy considers the complete coupled dynamics of the system and explicitly accounts for key sources of uncertainty, including external disturbances and unmodeled dynamics, while not requiring the robot's dynamic parameters in implementation. We propose a backstepping-based adaptive impedance control scheme for the inner loop to track the reference impedance model. To handle uncertainties, we employ a Taylor series-based estimator for system dynamics and an adaptive estimator for determining the upper bound of external forces. Stability analysis demonstrates the semi-global practical finite-time stability of the overall system. To demonstrate the effectiveness of the proposed method, a simulated mobile manipulator scenario and experimental evaluations on a real Franka Emika Panda robot were conducted. The proposed approach exhibits safer performance compared to PD control while ensuring trajectory tracking and force monitoring. Overall, the RABIC framework provides a solid basis for future research on adaptive and learning-based impedance control for coupled mobile and fixed serially linked manipulators.
Performance Comparison of CNN and AST Models with Stacked Features for Environmental Sound Classification
Feb 10, 2026Environmental sound classification (ESC) has gained significant attention due to its diverse applications in smart city monitoring, fault detection, acoustic surveillance, and manufacturing quality control. To enhance CNN performance, feature stacking techniques have been explored to aggregate complementary acoustic descriptors into richer input representations. In this paper, we investigate CNN-based models employing various stacked feature combinations, including Log-Mel Spectrogram (LM), Spectral Contrast (SPC), Chroma (CH), Tonnetz (TZ), Mel-Frequency Cepstral Coefficients (MFCCs), and Gammatone Cepstral Coefficients (GTCC). Experiments are conducted on the widely used ESC-50 and UrbanSound8K datasets under different training regimes, including pretraining on ESC-50, fine-tuning on UrbanSound8K, and comparison with Audio Spectrogram Transformer (AST) models pretrained on large-scale corpora such as AudioSet. This experimental design enables an analysis of how feature-stacked CNNs compare with transformer-based models under varying levels of training data and pretraining diversity. The results indicate that feature-stacked CNNs offer a more computationally and data-efficient alternative when large-scale pretraining or extensive training data are unavailable, making them particularly well suited for resource-constrained and edge-level sound classification scenarios.
Investigation of Feature Selection and Pooling Methods for Environmental Sound Classification
Nov 12, 2025


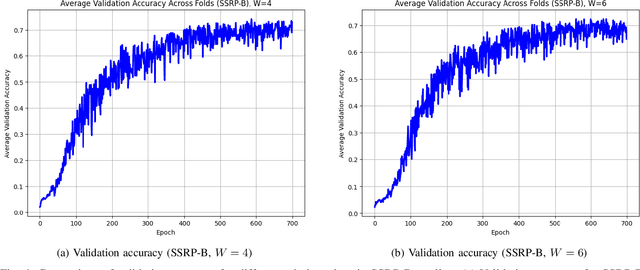
This paper explores the impact of dimensionality reduction and pooling methods for Environmental Sound Classification (ESC) using lightweight CNNs. We evaluate Sparse Salient Region Pooling (SSRP) and its variants, SSRP-Basic (SSRP-B) and SSRP-Top-K (SSRP-T), under various hyperparameter settings and compare them with Principal Component Analysis (PCA). Experiments on the ESC-50 dataset demonstrate that SSRP-T achieves up to 80.69 % accuracy, significantly outperforming both the baseline CNN (66.75 %) and the PCA-reduced model (37.60 %). Our findings confirm that a well-tuned sparse pooling strategy provides a robust, efficient, and high-performing solution for ESC tasks, particularly in resource-constrained scenarios where balancing accuracy and computational cost is crucial.
On Incremental Structure-from-Motion using Lines
May 24, 2021


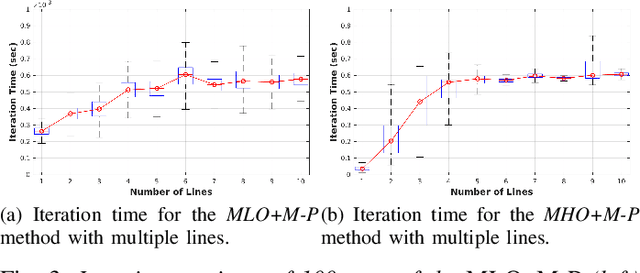
Humans tend to build environments with structure, which consists of mainly planar surfaces. From the intersection of planar surfaces arise straight lines. Lines have more degrees-of-freedom than points. Thus, line-based Structure-from-Motion (SfM) provides more information about the environment. In this paper, we present solutions for SfM using lines, namely, incremental SfM. These approaches consist of designing state observers for a camera's dynamical visual system looking at a 3D line. We start by presenting a model that uses spherical coordinates for representing the line's moment vector. We show that this parameterization has singularities, and therefore we introduce a more suitable model that considers the line's moment and shortest viewing ray. Concerning the observers, we present two different methodologies. The first uses a memory-less state-of-the-art framework for dynamic visual systems. Since the previous states of the robotic agent are accessible -- while performing the 3D mapping of the environment -- the second approach aims at exploiting the use of memory to improve the estimation accuracy and convergence speed. The two models and the two observers are evaluated in simulation and real data, where mobile and manipulator robots are used.
Active Depth Estimation: Stability Analysis and its Applications
Mar 16, 2020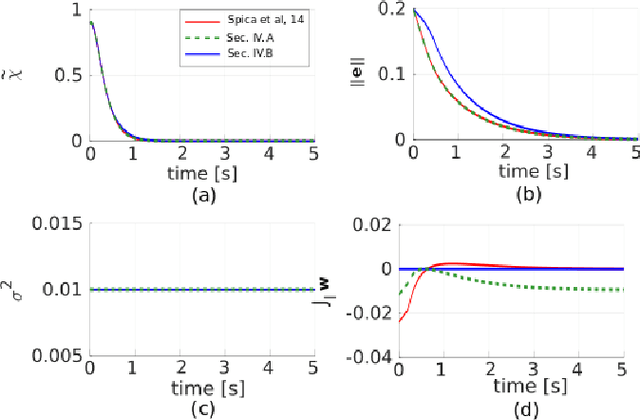
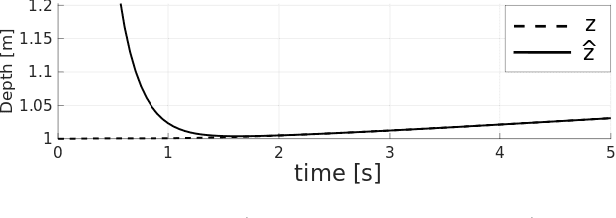
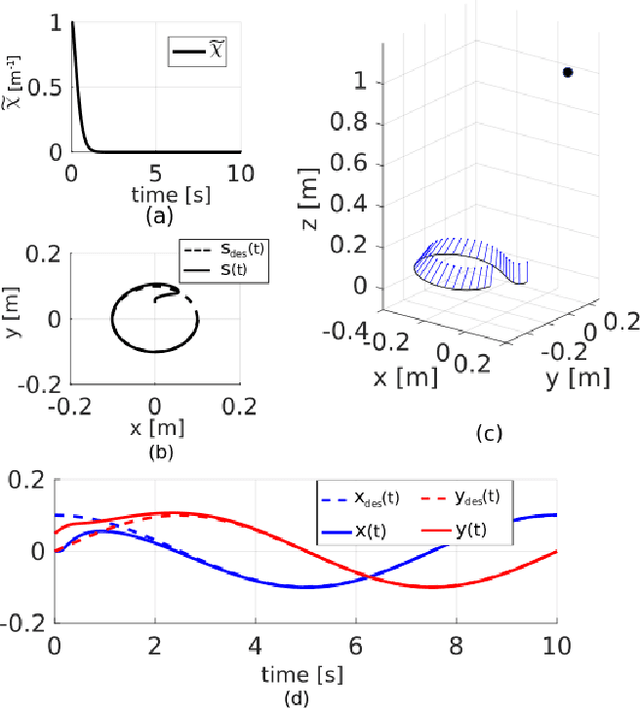
Recovering the 3D structure of the surrounding environment is an essential task in any vision-controlled Structure-from-Motion (SfM) scheme. This paper focuses on the theoretical properties of the SfM, known as the incremental active depth estimation. The term incremental stands for estimating the 3D structure of the scene over a chronological sequence of image frames. Active means that the camera actuation is such that it improves estimation performance. Starting from a known depth estimation filter, this paper presents the stability analysis of the filter in terms of the control inputs of the camera. By analyzing the convergence of the estimator using the Lyapunov theory, we relax the constraints on the projection of the 3D point in the image plane when compared to previous results. Nonetheless, our method is capable of dealing with the cameras' limited field-of-view constraints. The main results are validated through experiments with simulated data.
* 7 pages, 3 figures, conference
A Framework for Depth Estimation and Relative Localization of Ground Robots using Computer Vision
Aug 01, 2019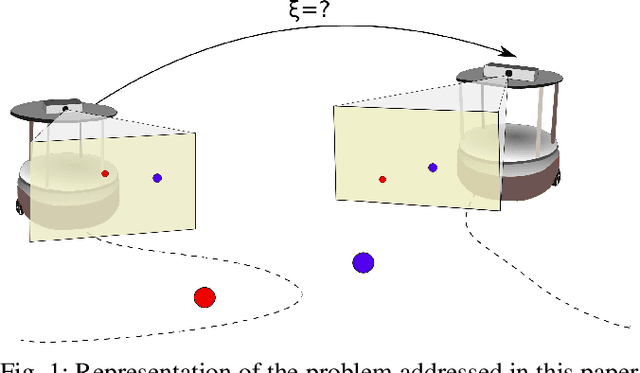
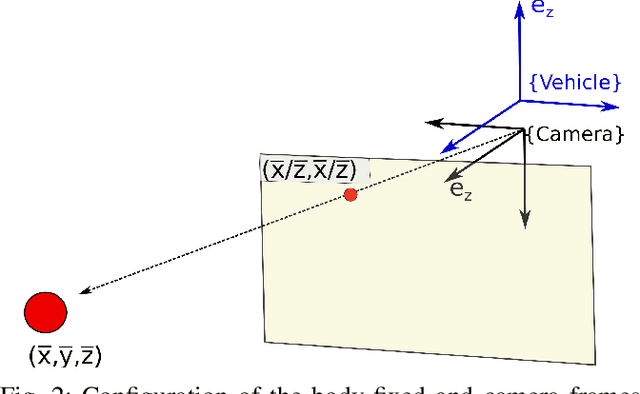
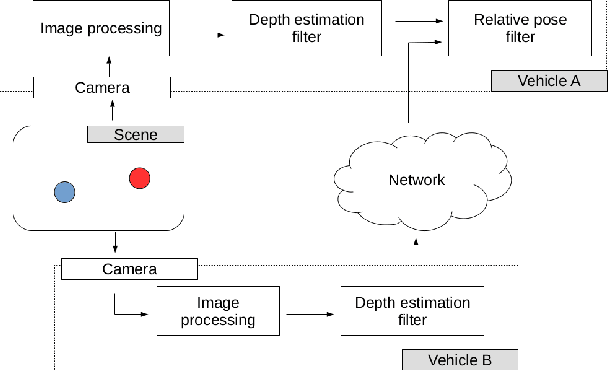
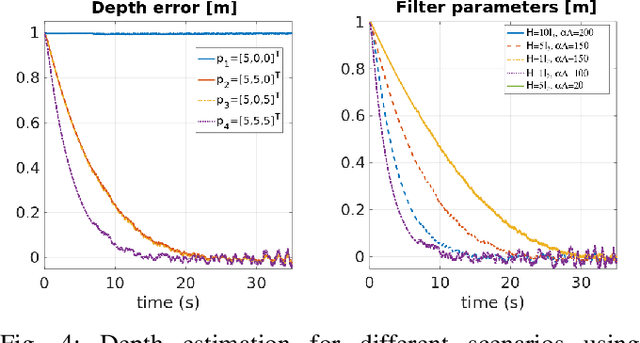
The 3D depth estimation and relative pose estimation problem within a decentralized architecture is a challenging problem that arises in missions that require coordination among multiple vision-controlled robots. The depth estimation problem aims at recovering the 3D information of the environment. The relative localization problem consists of estimating the relative pose between two robots, by sensing each other's pose or sharing information about the perceived environment. Most solutions for these problems use a set of discrete data without taking into account the chronological order of the events. This paper builds on recent results on continuous estimation to propose a framework that estimates the depth and relative pose between two non-holonomic vehicles. The basic idea consists in estimating the depth of the points by explicitly considering the dynamics of the camera mounted on a ground robot, and feeding the estimates of 3D points observed by both cameras in a filter that computes the relative pose between the robots. We evaluate the convergence for a set of simulated scenarios and show experimental results validating the proposed framework.
* 6 pages, 7 figures, conference
Low-level Active Visual Navigation: Increasing robustness of vision-based localization using potential fields
Mar 23, 2018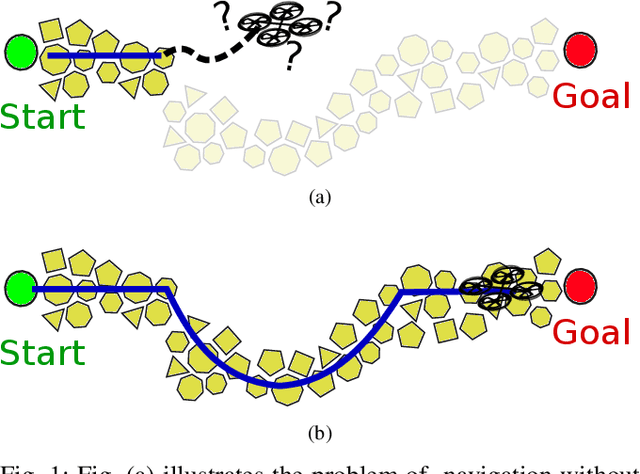
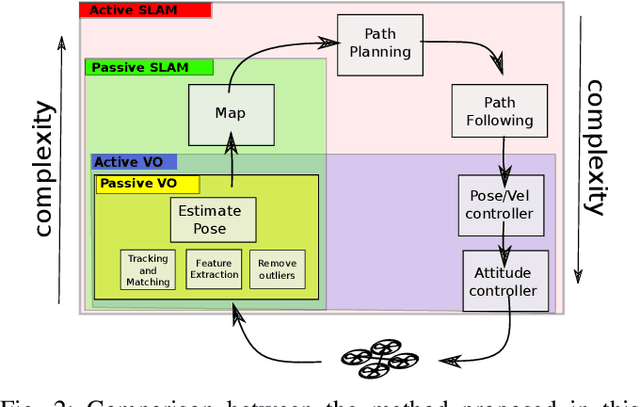
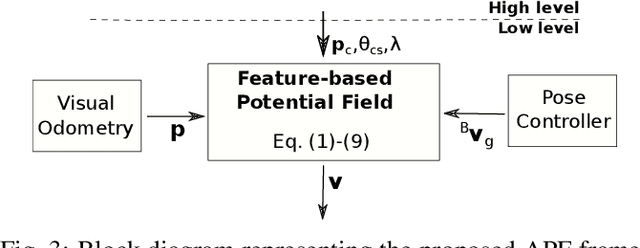
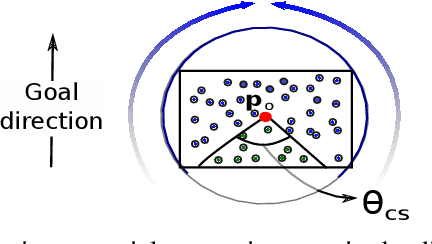
This paper proposes a low-level visual navigation algorithm to improve visual localization of a mobile robot. The algorithm, based on artificial potential fields, associates each feature in the current image frame with an attractive or neutral potential energy, with the objective of generating a control action that drives the vehicle towards the goal, while still favoring feature rich areas within a local scope, thus improving the localization performance. One key property of the proposed method is that it does not rely on mapping, and therefore it is a lightweight solution that can be deployed on miniaturized aerial robots, in which memory and computational power are major constraints. Simulations and real experimental results using a mini quadrotor equipped with a downward looking camera demonstrate that the proposed method can effectively drive the vehicle to a designated goal through a path that prevents localization failure.
Feature Based Potential Field for Low-level Active Visual Navigation
Sep 14, 2017
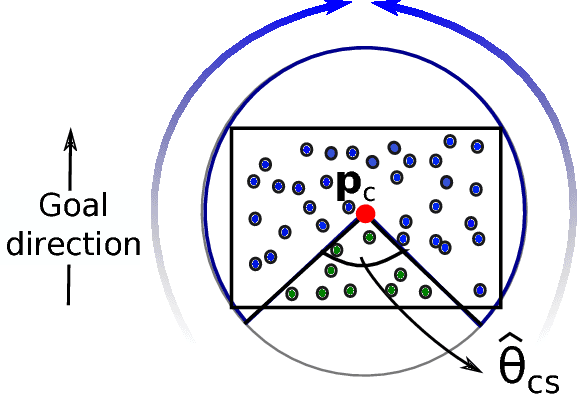
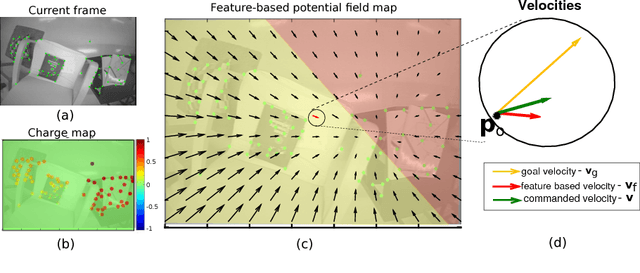
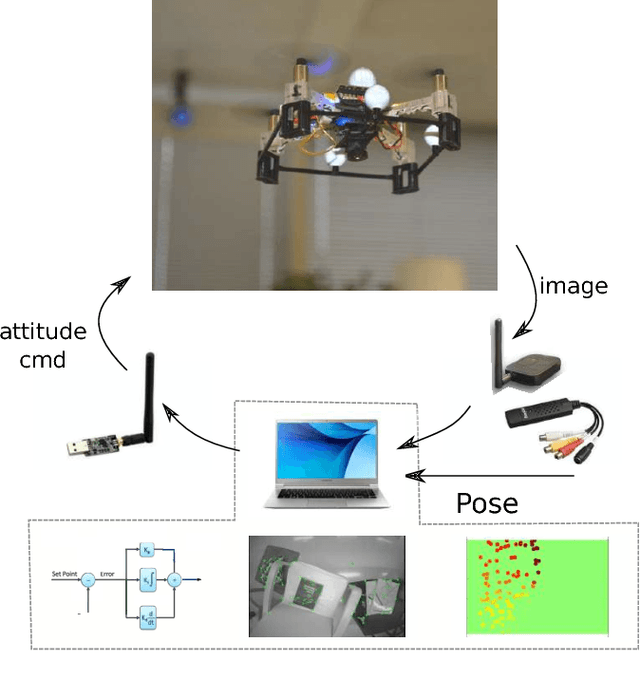
This paper proposes a novel solution for improving visual localization in an active fashion. The solution, based on artificial potential field, associates each feature in the current image frame with an attractive or neutral potential energy. The resultant action drives the vehicle towards the goal, while still favoring feature rich areas. Experimental results with a mini quadrotor equipped with a downward looking camera assess the performance of the proposed method.