 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePupil Tracking
Papers and Code
GAZELOAD A Multimodal Eye-Tracking Dataset for Mental Workload in Industrial Human-Robot Collaboration
Jan 29, 2026This article describes GAZELOAD, a multimodal dataset for mental workload estimation in industrial human-robot collaboration. The data were collected in a laboratory assembly testbed where 26 participants interacted with two collaborative robots (UR5 and Franka Emika Panda) while wearing Meta ARIA smart glasses. The dataset time-synchronizes eye-tracking signals (pupil diameter, fixations, saccades, eye gaze, gaze transition entropy, fixation dispersion index) with environmental real-time and continuous measurements (illuminance) and task and robot context (bench, task block, induced faults), under controlled manipulations of task difficulty and ambient conditions. For each participant and workload-graded task block, we provide CSV files with ocular metrics aggregated into 250 ms windows, environmental logs, and self-reported mental workload ratings on a 1-10 Likert scale, organized in participant-specific folders alongside documentation. These data can be used to develop and benchmark algorithms for mental workload estimation, feature extraction, and temporal modeling in realistic industrial HRC scenarios, and to investigate the influence of environmental factors such as lighting on eye-based workload markers.
Incorporating Eye-Tracking Signals Into Multimodal Deep Visual Models For Predicting User Aesthetic Experience In Residential Interiors
Jan 23, 2026Understanding how people perceive and evaluate interior spaces is essential for designing environments that promote well-being. However, predicting aesthetic experiences remains difficult due to the subjective nature of perception and the complexity of visual responses. This study introduces a dual-branch CNN-LSTM framework that fuses visual features with eye-tracking signals to predict aesthetic evaluations of residential interiors. We collected a dataset of 224 interior design videos paired with synchronized gaze data from 28 participants who rated 15 aesthetic dimensions. The proposed model attains 72.2% accuracy on objective dimensions (e.g., light) and 66.8% on subjective dimensions (e.g., relaxation), outperforming state-of-the-art video baselines and showing clear gains on subjective evaluation tasks. Notably, models trained with eye-tracking retain comparable performance when deployed with visual input alone. Ablation experiments further reveal that pupil responses contribute most to objective assessments, while the combination of gaze and visual cues enhances subjective evaluations. These findings highlight the value of incorporating eye-tracking as privileged information during training, enabling more practical tools for aesthetic assessment in interior design.
Gamma2Patterns: Deep Cognitive Attention Region Identification and Gamma-Alpha Pattern Analysis
Jan 09, 2026Deep cognitive attention is characterized by heightened gamma oscillations and coordinated visual behavior. Despite the physiological importance of these mechanisms, computational studies rarely synthesize these modalities or identify the neural regions most responsible for sustained focus. To address this gap, this work introduces Gamma2Patterns, a multimodal framework that characterizes deep cognitive attention by leveraging complementary Gamma and Alpha band EEG activity alongside Eye-tracking measurements. Using the SEED-IV dataset [1], we extract spectral power, burst-based temporal dynamics, and fixation-saccade-pupil signals across 62 channels or electrodes to analyze how neural activation differs between high-focus (Gamma-dominant) and low-focus (Alpha-dominant) states. Our findings reveal that frontopolar, temporal, anterior frontal, and parieto-occipital regions exhibit the strongest Gamma power and burst rates, indicating their dominant role in deep attentional engagement, while Eye-tracking signals confirm complementary contributions from frontal, frontopolar, and frontotemporal regions. Furthermore, we show that Gamma power and burst duration provide more discriminative markers of deep focus than Alpha power alone, demonstrating their value for attention decoding. Collectively, these results establish a multimodal, evidence-based map of cortical regions and oscillatory signatures underlying deep focus, providing a neurophysiological foundation for future brain-inspired attention mechanisms in AI systems.
Neuromorphic Eye Tracking for Low-Latency Pupil Detection
Dec 10, 2025



Eye tracking for wearable systems demands low latency and milliwatt-level power, but conventional frame-based pipelines struggle with motion blur, high compute cost, and limited temporal resolution. Such capabilities are vital for enabling seamless and responsive interaction in emerging technologies like augmented reality (AR) and virtual reality (VR), where understanding user gaze is key to immersion and interface design. Neuromorphic sensors and spiking neural networks (SNNs) offer a promising alternative, yet existing SNN approaches are either too specialized or fall short of the performance of modern ANN architectures. This paper presents a neuromorphic version of top-performing event-based eye-tracking models, replacing their recurrent and attention modules with lightweight LIF layers and exploiting depth-wise separable convolutions to reduce model complexity. Our models obtain 3.7-4.1px mean error, approaching the accuracy of the application-specific neuromorphic system, Retina (3.24px), while reducing model size by 20x and theoretical compute by 850x, compared to the closest ANN variant of the proposed model. These efficient variants are projected to operate at an estimated 3.9-4.9 mW with 3 ms latency at 1 kHz. The present results indicate that high-performing event-based eye-tracking architectures can be redesigned as SNNs with substantial efficiency gains, while retaining accuracy suitable for real-time wearable deployment.
SensHRPS: Sensing Comfortable Human-Robot Proxemics and Personal Space With Eye-Tracking
Dec 10, 2025Social robots must adjust to human proxemic norms to ensure user comfort and engagement. While prior research demonstrates that eye-tracking features reliably estimate comfort in human-human interactions, their applicability to interactions with humanoid robots remains unexplored. In this study, we investigate user comfort with the robot "Ameca" across four experimentally controlled distances (0.5 m to 2.0 m) using mobile eye-tracking and subjective reporting (N=19). We evaluate multiple machine learning and deep learning models to estimate comfort based on gaze features. Contrary to previous human-human studies where Transformer models excelled, a Decision Tree classifier achieved the highest performance (F1-score = 0.73), with minimum pupil diameter identified as the most critical predictor. These findings suggest that physiological comfort thresholds in human-robot interaction differ from human-human dynamics and can be effectively modeled using interpretable logic.
EETnet: a CNN for Gaze Detection and Tracking for Smart-Eyewear
Nov 06, 2025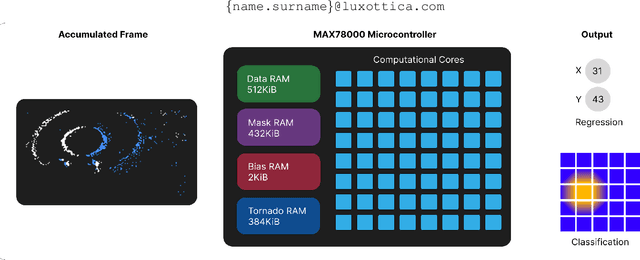
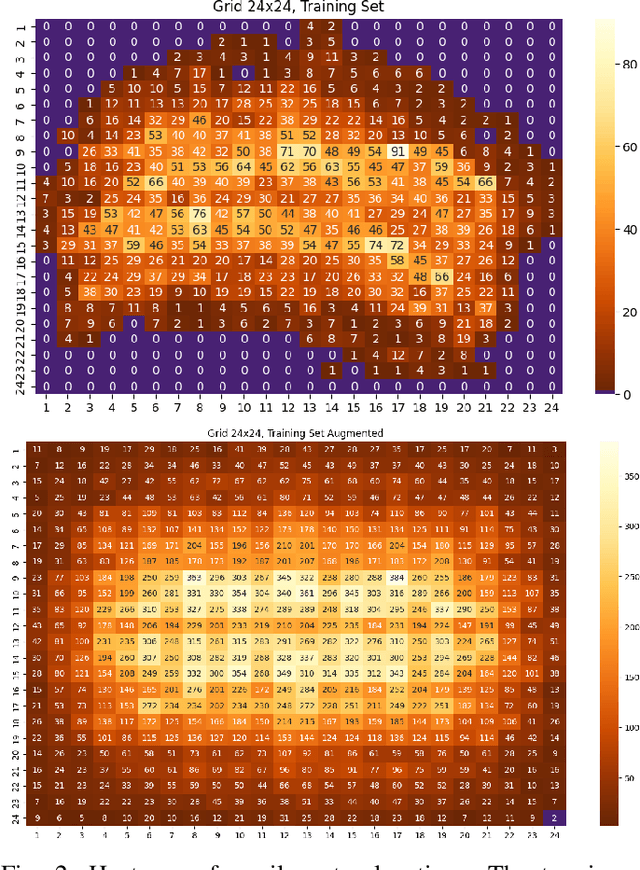

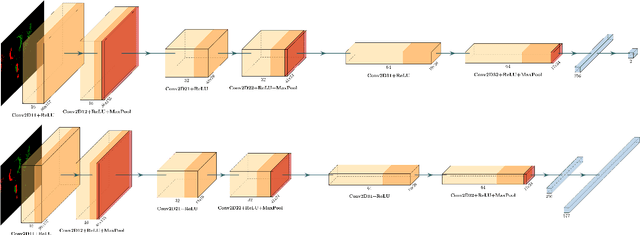
Event-based cameras are becoming a popular solution for efficient, low-power eye tracking. Due to the sparse and asynchronous nature of event data, they require less processing power and offer latencies in the microsecond range. However, many existing solutions are limited to validation on powerful GPUs, with no deployment on real embedded devices. In this paper, we present EETnet, a convolutional neural network designed for eye tracking using purely event-based data, capable of running on microcontrollers with limited resources. Additionally, we outline a methodology to train, evaluate, and quantize the network using a public dataset. Finally, we propose two versions of the architecture: a classification model that detects the pupil on a grid superimposed on the original image, and a regression model that operates at the pixel level.
Polarization-resolved imaging improves eye tracking
Nov 06, 2025Polarization-resolved near-infrared imaging adds a useful optical contrast mechanism to eye tracking by measuring the polarization state of light reflected by ocular tissues in addition to its intensity. In this paper we demonstrate how this contrast can be used to enable eye tracking. Specifically, we demonstrate that a polarization-enabled eye tracking (PET) system composed of a polarization--filter--array camera paired with a linearly polarized near-infrared illuminator can reveal trackable features across the sclera and gaze-informative patterns on the cornea, largely absent in intensity-only images. Across a cohort of 346 participants, convolutional neural network based machine learning models trained on data from PET reduced the median 95th-percentile absolute gaze error by 10--16\% relative to capacity-matched intensity baselines under nominal conditions and in the presence of eyelid occlusions, eye-relief changes, and pupil-size variation. These results link light--tissue polarization effects to practical gains in human--computer interaction and position PET as a simple, robust sensing modality for future wearable devices.
AI Meets Maritime Training: Precision Analytics for Enhanced Safety and Performance
Jul 02, 2025Traditional simulator-based training for maritime professionals is critical for ensuring safety at sea but often depends on subjective trainer assessments of technical skills, behavioral focus, communication, and body language, posing challenges such as subjectivity, difficulty in measuring key features, and cognitive limitations. Addressing these issues, this study develops an AI-driven framework to enhance maritime training by objectively assessing trainee performance through visual focus tracking, speech recognition, and stress detection, improving readiness for high-risk scenarios. The system integrates AI techniques, including visual focus determination using eye tracking, pupil dilation analysis, and computer vision; communication analysis through a maritime-specific speech-to-text model and natural language processing; communication correctness using large language models; and mental stress detection via vocal pitch. Models were evaluated on data from simulated maritime scenarios with seafarers exposed to controlled high-stress events. The AI algorithms achieved high accuracy, with ~92% for visual detection, ~91% for maritime speech recognition, and ~90% for stress detection, surpassing existing benchmarks. The system provides insights into visual attention, adherence to communication checklists, and stress levels under demanding conditions. This study demonstrates how AI can transform maritime training by delivering objective performance analytics, enabling personalized feedback, and improving preparedness for real-world operational challenges.
AI-guided digital intervention with physiological monitoring reduces intrusive memories after experimental trauma
Jul 01, 2025Trauma prevalence is vast globally. Evidence-based digital treatments can help, but most require human guidance. Human guides provide tailored instructions and responsiveness to internal cognitive states, but limit scalability. Can generative AI and neurotechnology provide a scalable alternative? Here we test ANTIDOTE, combining AI guidance and pupillometry to automatically deliver and monitor an evidence-based digital treatment, specifically the Imagery Competing Task Intervention (ICTI), to reduce intrusive memories after psychological trauma. One hundred healthy volunteers were exposed to videos of traumatic events and randomly assigned to an intervention or active control condition. As predicted, intervention participants reported significantly fewer intrusive memories over the following week. Post-hoc assessment against clinical rubrics confirmed the AI guide delivered the intervention successfully. Additionally, pupil size tracked intervention engagement and predicted symptom reduction, providing a candidate biomarker of intervention effectiveness. These findings open a path toward rigorous AI-guided digital interventions that can scale to trauma prevalence.
Vision Transformer attention alignment with human visual perception in aesthetic object evaluation
Jul 23, 2025Visual attention mechanisms play a crucial role in human perception and aesthetic evaluation. Recent advances in Vision Transformers (ViTs) have demonstrated remarkable capabilities in computer vision tasks, yet their alignment with human visual attention patterns remains underexplored, particularly in aesthetic contexts. This study investigates the correlation between human visual attention and ViT attention mechanisms when evaluating handcrafted objects. We conducted an eye-tracking experiment with 30 participants (9 female, 21 male, mean age 24.6 years) who viewed 20 artisanal objects comprising basketry bags and ginger jars. Using a Pupil Labs eye-tracker, we recorded gaze patterns and generated heat maps representing human visual attention. Simultaneously, we analyzed the same objects using a pre-trained ViT model with DINO (Self-DIstillation with NO Labels), extracting attention maps from each of the 12 attention heads. We compared human and ViT attention distributions using Kullback-Leibler divergence across varying Gaussian parameters (sigma=0.1 to 3.0). Statistical analysis revealed optimal correlation at sigma=2.4 +-0.03, with attention head #12 showing the strongest alignment with human visual patterns. Significant differences were found between attention heads, with heads #7 and #9 demonstrating the greatest divergence from human attention (p< 0.05, Tukey HSD test). Results indicate that while ViTs exhibit more global attention patterns compared to human focal attention, certain attention heads can approximate human visual behavior, particularly for specific object features like buckles in basketry items. These findings suggest potential applications of ViT attention mechanisms in product design and aesthetic evaluation, while highlighting fundamental differences in attention strategies between human perception and current AI models.