 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-and-Check: Using Large Language Models to Evaluate Communication Protocol Compliance in Simulation-Based Training
Aug 12, 2025Accurate evaluation of procedural communication compliance is essential in simulation-based training, particularly in safety-critical domains where adherence to compliance checklists reflects operational competence. This paper explores a lightweight, deployable approach using prompt-based inference with open-source large language models (LLMs) that can run efficiently on consumer-grade GPUs. We present Prompt-and-Check, a method that uses context-rich prompts to evaluate whether each checklist item in a protocol has been fulfilled, solely based on transcribed verbal exchanges. We perform a case study in the maritime domain with participants performing an identical simulation task, and experiment with models such as LLama 2 7B, LLaMA 3 8B and Mistral 7B, running locally on an RTX 4070 GPU. For each checklist item, a prompt incorporating relevant transcript excerpts is fed into the model, which outputs a compliance judgment. We assess model outputs against expert-annotated ground truth using classification accuracy and agreement scores. Our findings demonstrate that prompting enables effective context-aware reasoning without task-specific training. This study highlights the practical utility of LLMs in augmenting debriefing, performance feedback, and automated assessment in training environments.
Enhancing Egocentric Object Detection in Static Environments using Graph-based Spatial Anomaly Detection and Correction
Aug 11, 2025In many real-world applications involving static environments, the spatial layout of objects remains consistent across instances. However, state-of-the-art object detection models often fail to leverage this spatial prior, resulting in inconsistent predictions, missed detections, or misclassifications, particularly in cluttered or occluded scenes. In this work, we propose a graph-based post-processing pipeline that explicitly models the spatial relationships between objects to correct detection anomalies in egocentric frames. Using a graph neural network (GNN) trained on manually annotated data, our model identifies invalid object class labels and predicts corrected class labels based on their neighbourhood context. We evaluate our approach both as a standalone anomaly detection and correction framework and as a post-processing module for standard object detectors such as YOLOv7 and RT-DETR. Experiments demonstrate that incorporating this spatial reasoning significantly improves detection performance, with mAP@50 gains of up to 4%. This method highlights the potential of leveraging the environment's spatial structure to improve reliability in object detection systems.
AI Meets Maritime Training: Precision Analytics for Enhanced Safety and Performance
Jul 02, 2025Traditional simulator-based training for maritime professionals is critical for ensuring safety at sea but often depends on subjective trainer assessments of technical skills, behavioral focus, communication, and body language, posing challenges such as subjectivity, difficulty in measuring key features, and cognitive limitations. Addressing these issues, this study develops an AI-driven framework to enhance maritime training by objectively assessing trainee performance through visual focus tracking, speech recognition, and stress detection, improving readiness for high-risk scenarios. The system integrates AI techniques, including visual focus determination using eye tracking, pupil dilation analysis, and computer vision; communication analysis through a maritime-specific speech-to-text model and natural language processing; communication correctness using large language models; and mental stress detection via vocal pitch. Models were evaluated on data from simulated maritime scenarios with seafarers exposed to controlled high-stress events. The AI algorithms achieved high accuracy, with ~92% for visual detection, ~91% for maritime speech recognition, and ~90% for stress detection, surpassing existing benchmarks. The system provides insights into visual attention, adherence to communication checklists, and stress levels under demanding conditions. This study demonstrates how AI can transform maritime training by delivering objective performance analytics, enabling personalized feedback, and improving preparedness for real-world operational challenges.
Contextual Biasing to Improve Domain-specific Custom Vocabulary Audio Transcription without Explicit Fine-Tuning of Whisper Model
Oct 24, 2024
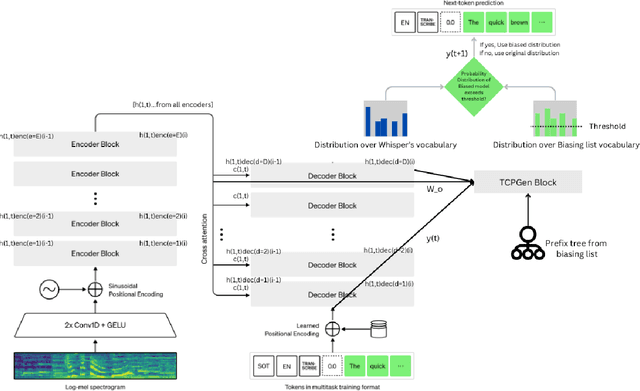
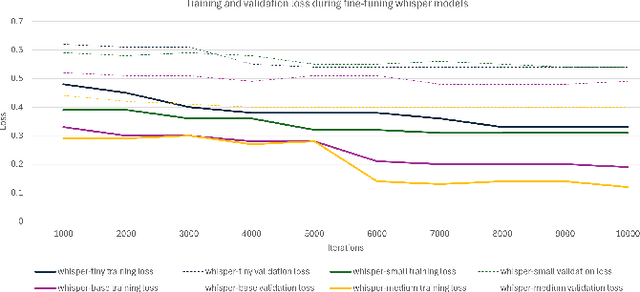
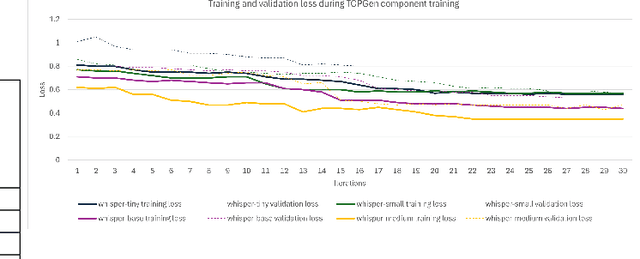
OpenAI's Whisper Automated Speech Recognition model excels in generalizing across diverse datasets and domains. However, this broad adaptability can lead to diminished performance in tasks requiring recognition of specific vocabularies. Addressing this challenge typically involves fine-tuning the model, which demands extensive labeled audio data that is often difficult to acquire and unavailable for specific domains. In this study, we propose a method to enhance transcription accuracy without explicit fine-tuning or altering model parameters, using a relatively small training dataset. Our method leverages contextual biasing, to direct Whisper model's output towards a specific vocabulary by integrating a neural-symbolic prefix tree structure to guide the model's transcription output. To validate our approach, we conducted experiments using a validation dataset comprising maritime data collected within a simulated training environment. A comparison between the original Whisper models of varying parameter sizes and our biased model revealed a notable reduction in transcription word error rate and enhanced performance of downstream applications. Our findings suggest that this methodology holds promise for improving speech-to-text translation performance in domains characterized by limited vocabularies.