 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Biasing to Improve Domain-specific Custom Vocabulary Audio Transcription without Explicit Fine-Tuning of Whisper Model
Paper and Code
Oct 24, 2024
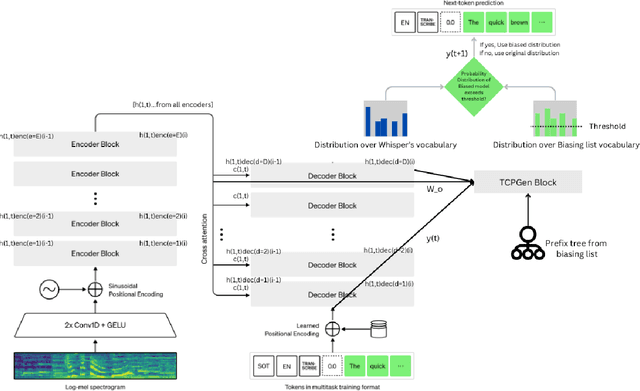
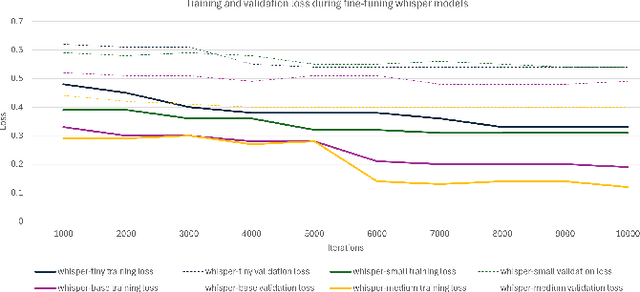
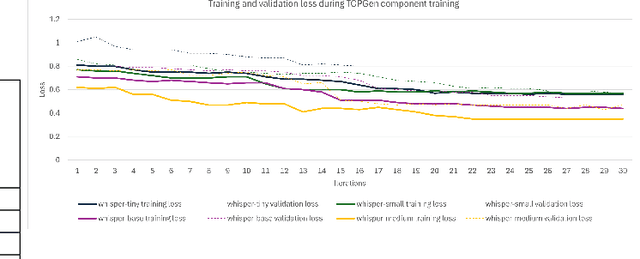
OpenAI's Whisper Automated Speech Recognition model excels in generalizing across diverse datasets and domains. However, this broad adaptability can lead to diminished performance in tasks requiring recognition of specific vocabularies. Addressing this challenge typically involves fine-tuning the model, which demands extensive labeled audio data that is often difficult to acquire and unavailable for specific domains. In this study, we propose a method to enhance transcription accuracy without explicit fine-tuning or altering model parameters, using a relatively small training dataset. Our method leverages contextual biasing, to direct Whisper model's output towards a specific vocabulary by integrating a neural-symbolic prefix tree structure to guide the model's transcription output. To validate our approach, we conducted experiments using a validation dataset comprising maritime data collected within a simulated training environment. A comparison between the original Whisper models of varying parameter sizes and our biased model revealed a notable reduction in transcription word error rate and enhanced performance of downstream applications. Our findings suggest that this methodology holds promise for improving speech-to-text translation performance in domains characterized by limited vocabularies.