 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Deep Metrics for Image Registration
Paper and Code
Apr 04, 2018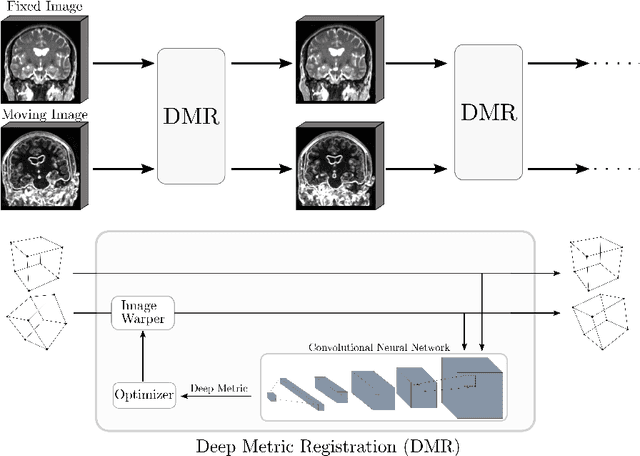
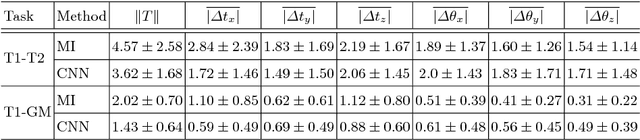
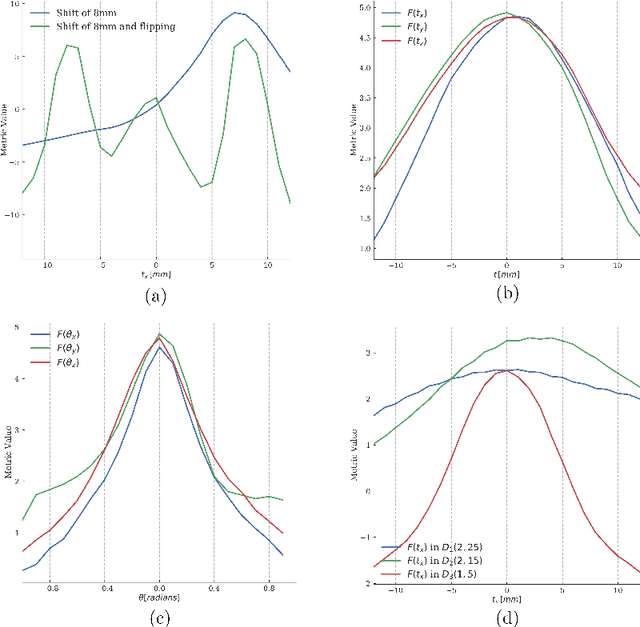
Deep metrics have been shown effective as similarity measures in multi-modal image registration; however, the metrics are currently constructed from aligned image pairs in the training data. In this paper, we propose a strategy for learning such metrics from roughly aligned training data. Symmetrizing the data corrects bias in the metric that results from misalignment in the data (at the expense of increased variance), while random perturbations to the data, i.e. dithering, ensures that the metric has a single mode, and is amenable to registration by optimization. Evaluation is performed on the task of registration on separate unseen test image pairs. The results demonstrate the feasibility of learning a useful deep metric from substantially misaligned training data, in some cases the results are significantly better than from Mutual Information. Data augmentation via dithering is, therefore, an effective strategy for discharging the need for well-aligned training data; this brings deep metric registration from the realm of supervised to semi-supervised machine learning.