 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Mask for Transformer based End-to-End Speech Recognition
Paper and Code

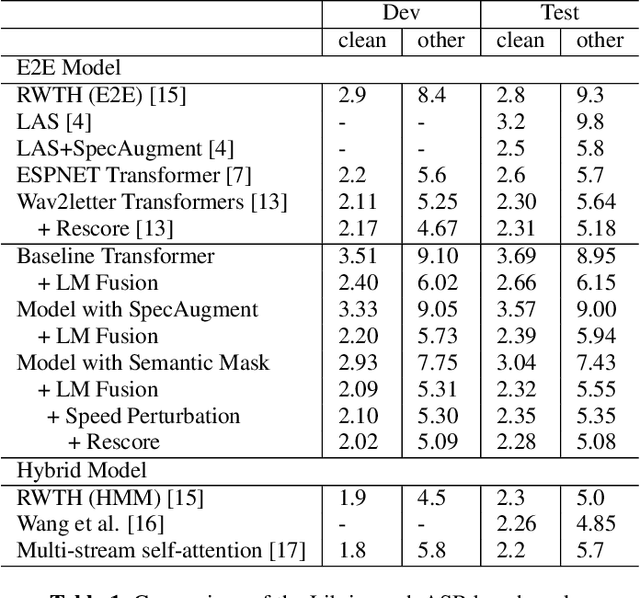
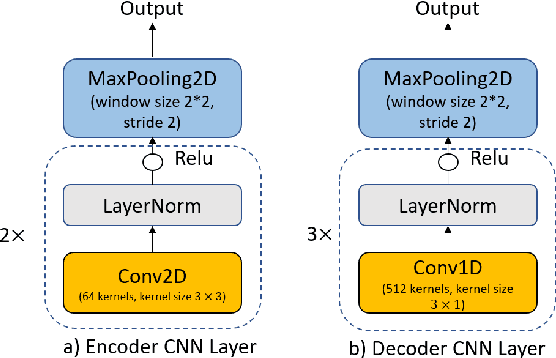
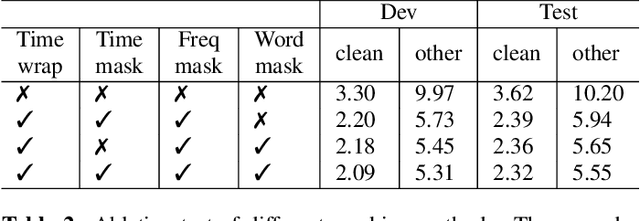
Attention-based encoder-decoder model has achieved impressive results for both automatic speech recognition (ASR) and text-to-speech (TTS) tasks. This approach takes advantage of the memorization capacity of neural networks to learn the mapping from the input sequence to the output sequence from scratch, without the assumption of prior knowledge such as the alignments. However, this model is prone to overfitting, especially when the amount of training data is limited. Inspired by SpecAugment and BERT, in this paper, we propose a semantic mask based regularization for training such kind of end-to-end (E2E) model. The idea is to mask the input features corresponding to a particular output token, e.g., a word or a word-piece, in order to encourage the model to fill the token based on the contextual information. While this approach is applicable to the encoder-decoder framework with any type of neural network architecture, we study the transformer-based model for ASR in this work. We perform experiments on Librispeech 960h and TedLium2 data sets, and achieve the state-of-the-art performance on the test set in the scope of E2E models.