 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePT-ResNet: Perspective Transformation-Based Residual Network for Semantic Road Image Segmentation
Paper and Code
Oct 29, 2019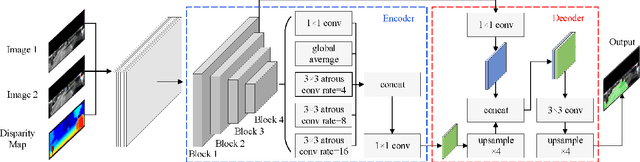
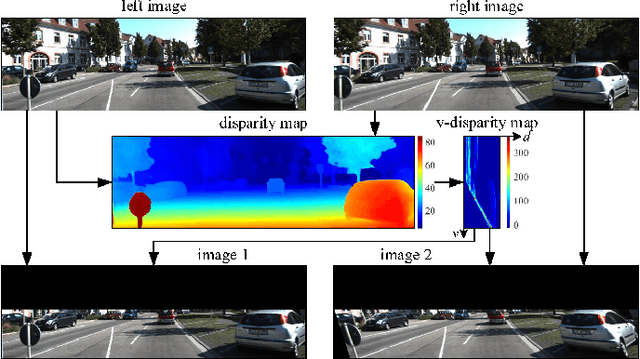
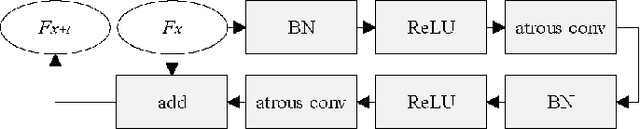
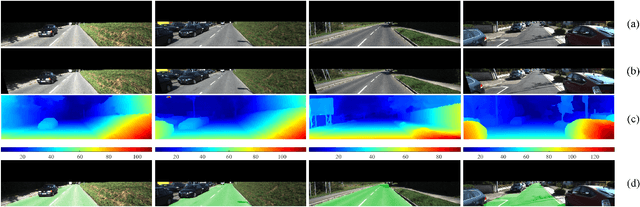
Semantic road region segmentation is a high-level task, which paves the way towards road scene understanding. This paper presents a residual network trained for semantic road segmentation. Firstly, we represent the projections of road disparities in the v-disparity map as a linear model, which can be estimated by optimizing the v-disparity map using dynamic programming. This linear model is then utilized to reduce the redundant information in the left and right road images. The right image is also transformed into the left perspective view, which greatly enhances the road surface similarity between the two images. Finally, the processed stereo images and their disparity maps are concatenated to create a set of 3D images, which are then utilized to train our neural network. The experimental results illustrate that our network achieves a maximum F1-measure of approximately 91.19% when analyzing the images from the KITTI road dataset.