 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Metric Learning with Content-based Regularization for Software Artifact Retrieval
Paper and Code
Sep 25, 2014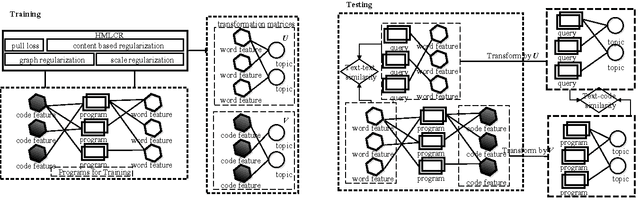
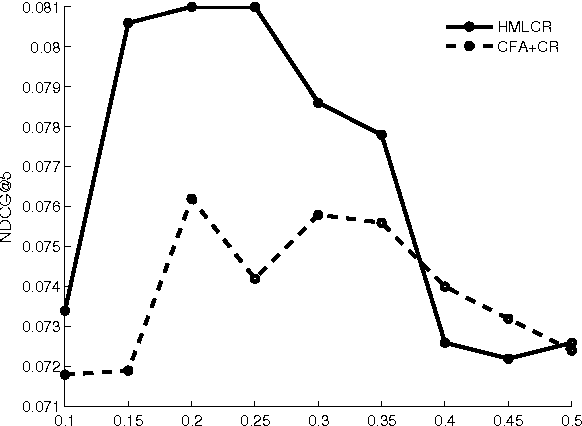

The problem of software artifact retrieval has the goal to effectively locate software artifacts, such as a piece of source code, in a large code repository. This problem has been traditionally addressed through the textual query. In other words, information retrieval techniques will be exploited based on the textual similarity between queries and textual representation of software artifacts, which is generated by collecting words from comments, identifiers, and descriptions of programs. However, in addition to these semantic information, there are rich information embedded in source codes themselves. These source codes, if analyzed properly, can be a rich source for enhancing the efforts of software artifact retrieval. To this end, in this paper, we develop a feature extraction method on source codes. Specifically, this method can capture both the inherent information in the source codes and the semantic information hidden in the comments, descriptions, and identifiers of the source codes. Moreover, we design a heterogeneous metric learning approach, which allows to integrate code features and text features into the same latent semantic space. This, in turn, can help to measure the artifact similarity by exploiting the joint power of both code and text features. Finally, extensive experiments on real-world data show that the proposed method can help to improve the performances of software artifact retrieval with a significant margin.