 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEST-1k: A Dataset for Spatial Transcriptomics and Histology Image Analysis
Paper and Code
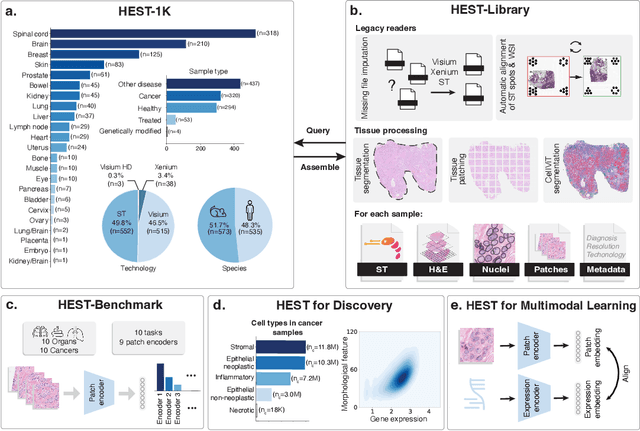
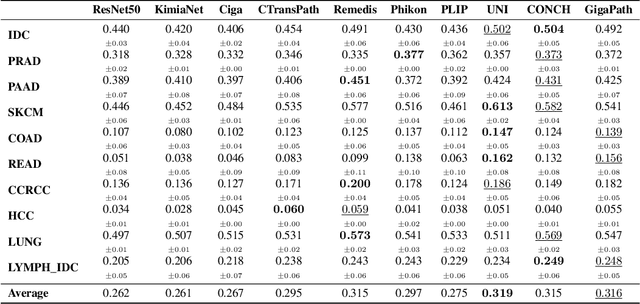
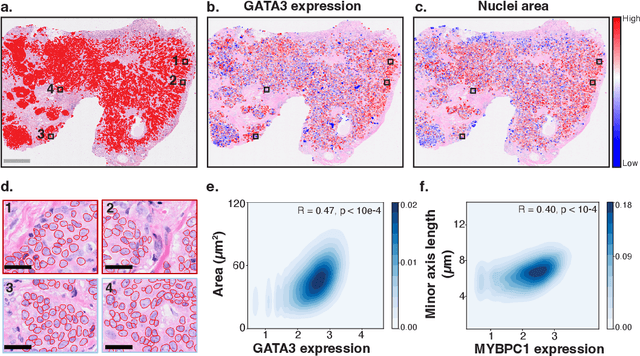

Spatial transcriptomics (ST) enables interrogating the molecular composition of tissue with ever-increasing resolution, depth, and sensitivity. However, costs, rapidly evolving technology, and lack of standards have constrained computational methods in ST to narrow tasks and small cohorts. In addition, the underlying tissue morphology as reflected by H&E-stained whole slide images (WSIs) encodes rich information often overlooked in ST studies. Here, we introduce HEST-1k, a collection of 1,108 spatial transcriptomic profiles, each linked to a WSI and metadata. HEST-1k was assembled using HEST-Library from 131 public and internal cohorts encompassing 25 organs, two species (Homo Sapiens and Mus Musculus), and 320 cancer samples from 25 cancer types. HEST-1k processing enabled the identification of 1.5 million expression--morphology pairs and 60 million nuclei. HEST-1k is tested on three use cases: (1) benchmarking foundation models for histopathology (HEST-Benchmark), (2) biomarker identification, and (3) multimodal representation learning. HEST-1k, HEST-Library, and HEST-Benchmark can be freely accessed via https://github.com/mahmoodlab/hest.