 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlancing Transformer for Non-Autoregressive Neural Machine Translation
Paper and Code
Aug 18, 2020


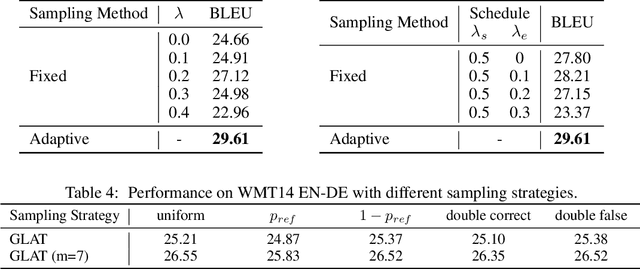
Non-autoregressive neural machine translation achieves remarkable inference acceleration compared to autoregressive models. However, current non-autoregressive models still fall behind their autoregressive counterparts in prediction accuracy. We attribute the accuracy gaps to two disadvantages of non-autoregressive models: a) learning simultaneous generation under the overly strong conditional independence assumption; b) lacking explicit target language modeling. In this paper, we propose Glancing Transformer (GLAT) to address the above disadvantages, which reduces the difficulty of learning simultaneous generation and introduces explicit target language modeling in the non-autoregressive setting at the same time. Experiments on several benchmarks demonstrate that our approach significantly improves the accuracy of non-autoregressive models without sacrificing any inference efficiency. In particular, GLAT achieves 30.91 BLEU on WMT 2014 German-English, which narrows the gap between autoregressive models and non-autoregressive models to less than 0.5 BLEU score.