 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Automated End-to-End Fake Audio Detection
Paper and Code
Aug 20, 2022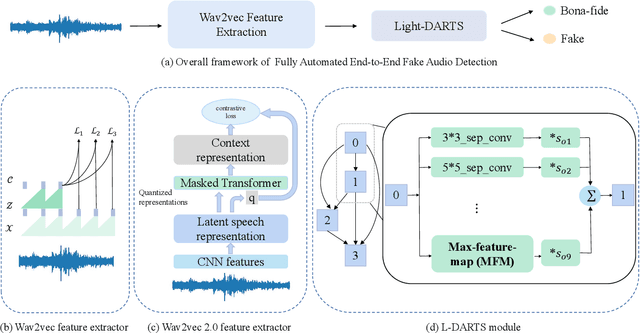
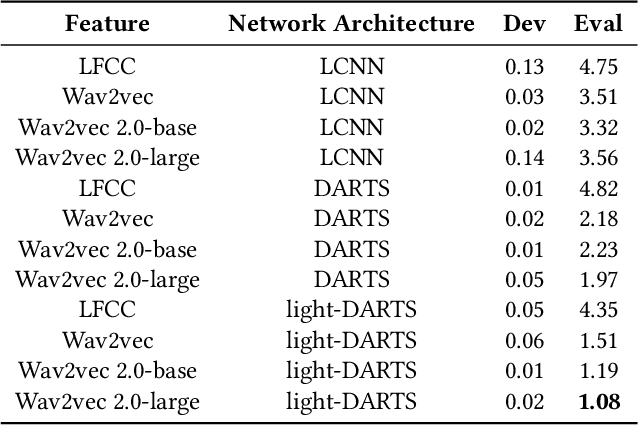

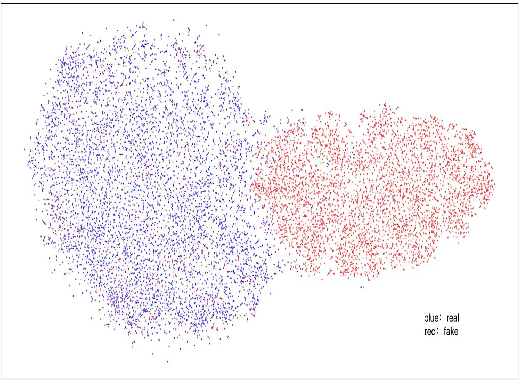
The existing fake audio detection systems often rely on expert experience to design the acoustic features or manually design the hyperparameters of the network structure. However, artificial adjustment of the parameters can have a relatively obvious influence on the results. It is almost impossible to manually set the best set of parameters. Therefore this paper proposes a fully automated end-toend fake audio detection method. We first use wav2vec pre-trained model to obtain a high-level representation of the speech. Furthermore, for the network structure, we use a modified version of the differentiable architecture search (DARTS) named light-DARTS. It learns deep speech representations while automatically learning and optimizing complex neural structures consisting of convolutional operations and residual blocks. The experimental results on the ASVspoof 2019 LA dataset show that our proposed system achieves an equal error rate (EER) of 1.08%, which outperforms the state-of-the-art single system.