 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedML Parrot: A Scalable Federated Learning System via Heterogeneity-aware Scheduling on Sequential and Hierarchical Training
Paper and Code

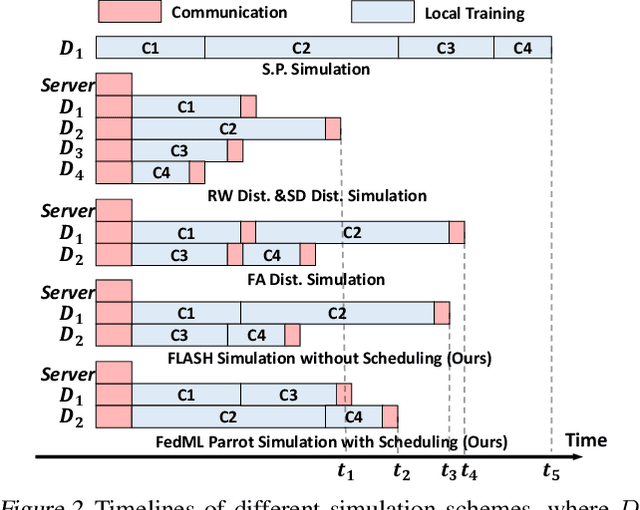


Federated Learning (FL) enables collaborations among clients for train machine learning models while protecting their data privacy. Existing FL simulation platforms that are designed from the perspectives of traditional distributed training, suffer from laborious code migration between simulation and production, low efficiency, low GPU utility, low scalability with high hardware requirements and difficulty of simulating stateful clients. In this work, we firstly demystify the challenges and bottlenecks of simulating FL, and design a new FL system named as FedML \texttt{Parrot}. It improves the training efficiency, remarkably relaxes the requirements on the hardware, and supports efficient large-scale FL experiments with stateful clients by: (1) sequential training clients on devices; (2) decomposing original aggregation into local and global aggregation on devices and server respectively; (3) scheduling tasks to mitigate straggler problems and enhance computing utility; (4) distributed client state manager to support various FL algorithms. Besides, built upon our generic APIs and communication interfaces, users can seamlessly transform the simulation into the real-world deployment without modifying codes. We evaluate \texttt{Parrot} through extensive experiments for training diverse models on various FL datasets to demonstrate that \texttt{Parrot} can achieve simulating over 1000 clients (stateful or stateless) with flexible GPU devices setting ($4 \sim 32$) and high GPU utility, 1.2 $\sim$ 4 times faster than FedScale, and 10 $\sim$ 100 times memory saving than FedML. And we verify that \texttt{Parrot} works well with homogeneous and heterogeneous devices in three different clusters. Two FL algorithms with stateful clients and four algorithms with stateless clients are simulated to verify the wide adaptability of \texttt{Parrot} to different algorithms.