 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQ-DETR: Dual Query Detection Transformer for Phrase Extraction and Grounding
Paper and Code


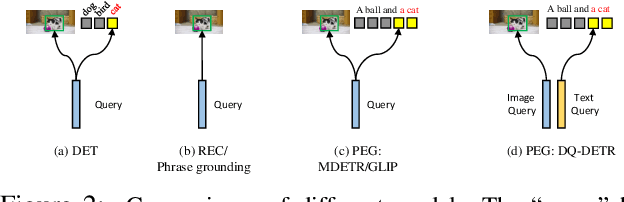

In this paper, we study the problem of visual grounding by considering both phrase extraction and grounding (PEG). In contrast to the previous phrase-known-at-test setting, PEG requires a model to extract phrases from text and locate objects from images simultaneously, which is a more practical setting in real applications. As phrase extraction can be regarded as a $1$D text segmentation problem, we formulate PEG as a dual detection problem and propose a novel DQ-DETR model, which introduces dual queries to probe different features from image and text for object prediction and phrase mask prediction. Each pair of dual queries is designed to have shared positional parts but different content parts. Such a design effectively alleviates the difficulty of modality alignment between image and text (in contrast to a single query design) and empowers Transformer decoder to leverage phrase mask-guided attention to improve performance. To evaluate the performance of PEG, we also propose a new metric CMAP (cross-modal average precision), analogous to the AP metric in object detection. The new metric overcomes the ambiguity of Recall@1 in many-box-to-one-phrase cases in phrase grounding. As a result, our PEG pre-trained DQ-DETR establishes new state-of-the-art results on all visual grounding benchmarks with a ResNet-101 backbone. For example, it achieves $91.04\%$ and $83.51\%$ in terms of recall rate on RefCOCO testA and testB with a ResNet-101 backbone. Code will be availabl at \url{https://github.com/IDEA-Research/DQ-DETR}.