 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDilated Context Integrated Network with Cross-Modal Consensus for Temporal Emotion Localization in Videos
Paper and Code

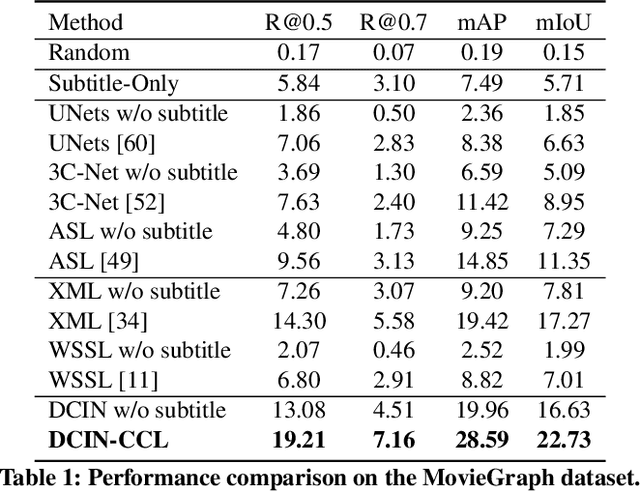
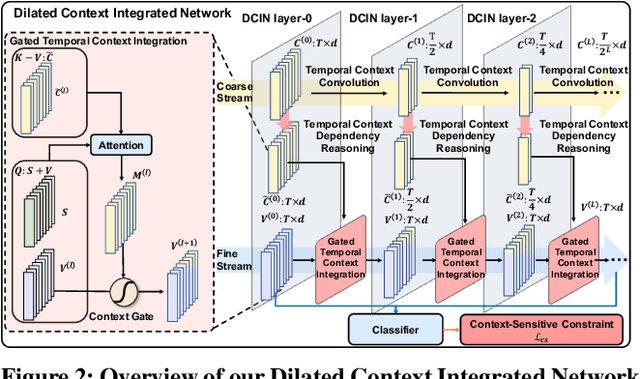
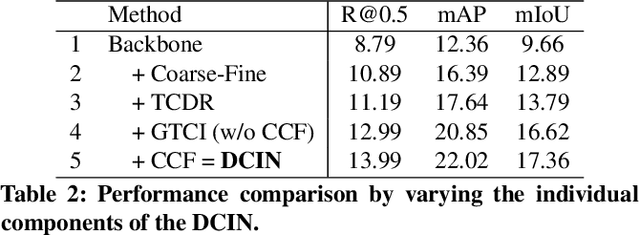
Understanding human emotions is a crucial ability for intelligent robots to provide better human-robot interactions. The existing works are limited to trimmed video-level emotion classification, failing to locate the temporal window corresponding to the emotion. In this paper, we introduce a new task, named Temporal Emotion Localization in videos~(TEL), which aims to detect human emotions and localize their corresponding temporal boundaries in untrimmed videos with aligned subtitles. TEL presents three unique challenges compared to temporal action localization: 1) The emotions have extremely varied temporal dynamics; 2) The emotion cues are embedded in both appearances and complex plots; 3) The fine-grained temporal annotations are complicated and labor-intensive. To address the first two challenges, we propose a novel dilated context integrated network with a coarse-fine two-stream architecture. The coarse stream captures varied temporal dynamics by modeling multi-granularity temporal contexts. The fine stream achieves complex plots understanding by reasoning the dependency between the multi-granularity temporal contexts from the coarse stream and adaptively integrates them into fine-grained video segment features. To address the third challenge, we introduce a cross-modal consensus learning paradigm, which leverages the inherent semantic consensus between the aligned video and subtitle to achieve weakly-supervised learning. We contribute a new testing set with 3,000 manually-annotated temporal boundaries so that future research on the TEL problem can be quantitatively evaluated. Extensive experiments show the effectiveness of our approach on temporal emotion localization. The repository of this work is at https://github.com/YYJMJC/Temporal-Emotion-Localization-in-Videos.