 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCirCNN: Accelerating and Compressing Deep Neural Networks Using Block-CirculantWeight Matrices
Paper and Code
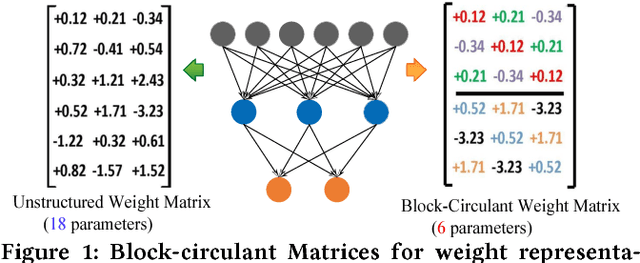
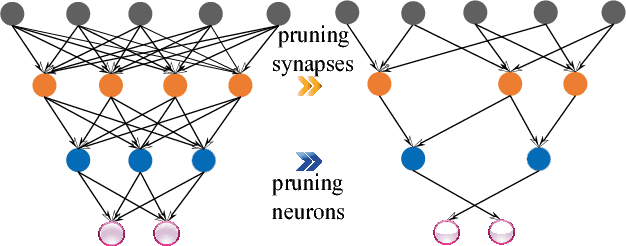
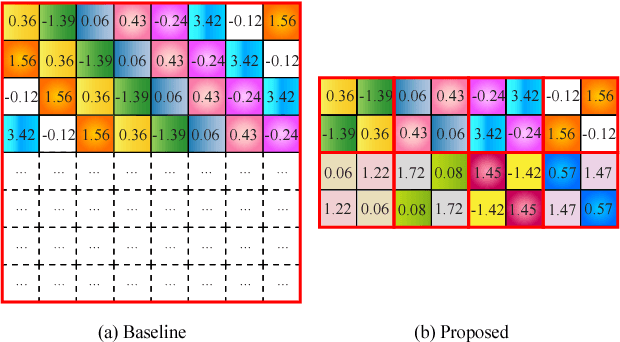
Large-scale deep neural networks (DNNs) are both compute and memory intensive. As the size of DNNs continues to grow, it is critical to improve the energy efficiency and performance while maintaining accuracy. For DNNs, the model size is an important factor affecting performance, scalability and energy efficiency. Weight pruning achieves good compression ratios but suffers from three drawbacks: 1) the irregular network structure after pruning; 2) the increased training complexity; and 3) the lack of rigorous guarantee of compression ratio and inference accuracy. To overcome these limitations, this paper proposes CirCNN, a principled approach to represent weights and process neural networks using block-circulant matrices. CirCNN utilizes the Fast Fourier Transform (FFT)-based fast multiplication, simultaneously reducing the computational complexity (both in inference and training) from O(n2) to O(nlogn) and the storage complexity from O(n2) to O(n), with negligible accuracy loss. Compared to other approaches, CirCNN is distinct due to its mathematical rigor: it can converge to the same effectiveness as DNNs without compression. The CirCNN architecture, a universal DNN inference engine that can be implemented on various hardware/software platforms with configurable network architecture. To demonstrate the performance and energy efficiency, we test CirCNN in FPGA, ASIC and embedded processors. Our results show that CirCNN architecture achieves very high energy efficiency and performance with a small hardware footprint. Based on the FPGA implementation and ASIC synthesis results, CirCNN achieves 6-102X energy efficiency improvements compared with the best state-of-the-art results.