 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Deep Clustering: Taxonomy, Challenges, and Future Directions
Paper and Code
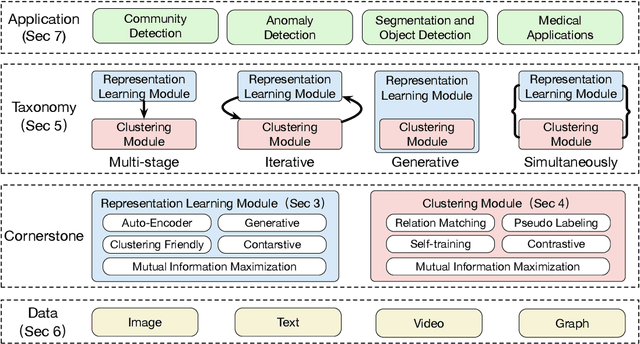
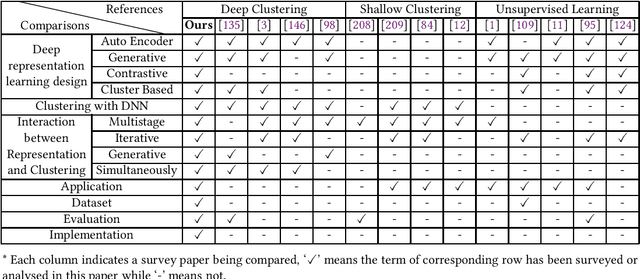
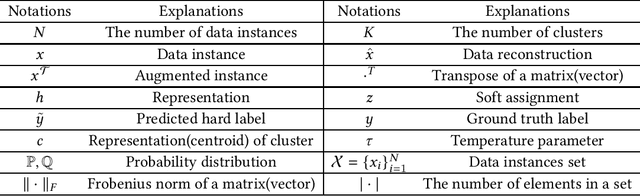
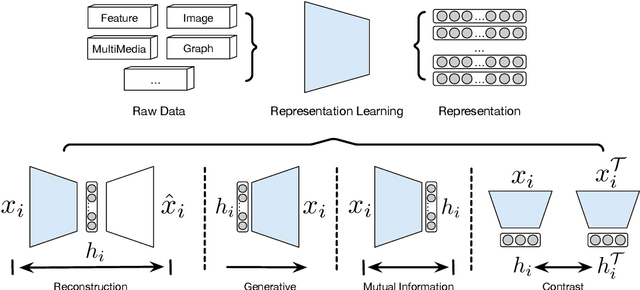
Clustering is a fundamental machine learning task which has been widely studied in the literature. Classic clustering methods follow the assumption that data are represented as features in a vectorized form through various representation learning techniques. As the data become increasingly complicated and complex, the shallow (traditional) clustering methods can no longer handle the high-dimensional data type. With the huge success of deep learning, especially the deep unsupervised learning, many representation learning techniques with deep architectures have been proposed in the past decade. Recently, the concept of Deep Clustering, i.e., jointly optimizing the representation learning and clustering, has been proposed and hence attracted growing attention in the community. Motivated by the tremendous success of deep learning in clustering, one of the most fundamental machine learning tasks, and the large number of recent advances in this direction, in this paper we conduct a comprehensive survey on deep clustering by proposing a new taxonomy of different state-of-the-art approaches. We summarize the essential components of deep clustering and categorize existing methods by the ways they design interactions between deep representation learning and clustering. Moreover, this survey also provides the popular benchmark datasets, evaluation metrics and open-source implementations to clearly illustrate various experimental settings. Last but not least, we discuss the practical applications of deep clustering and suggest challenging topics deserving further investigations as future directions.