 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Extensions of Basis Pursuit: Guarantees on Adversarial Robustness
May 05, 2022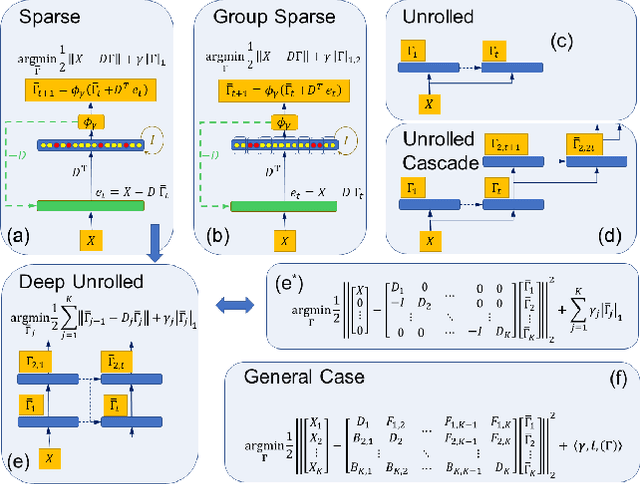
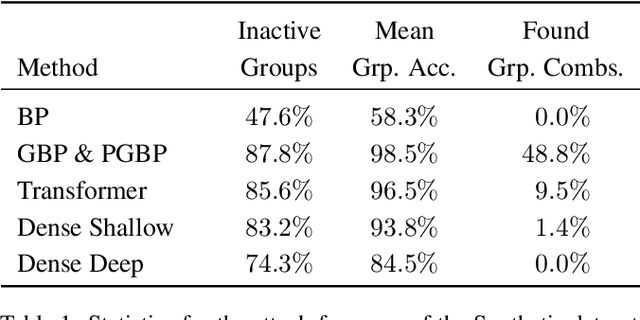
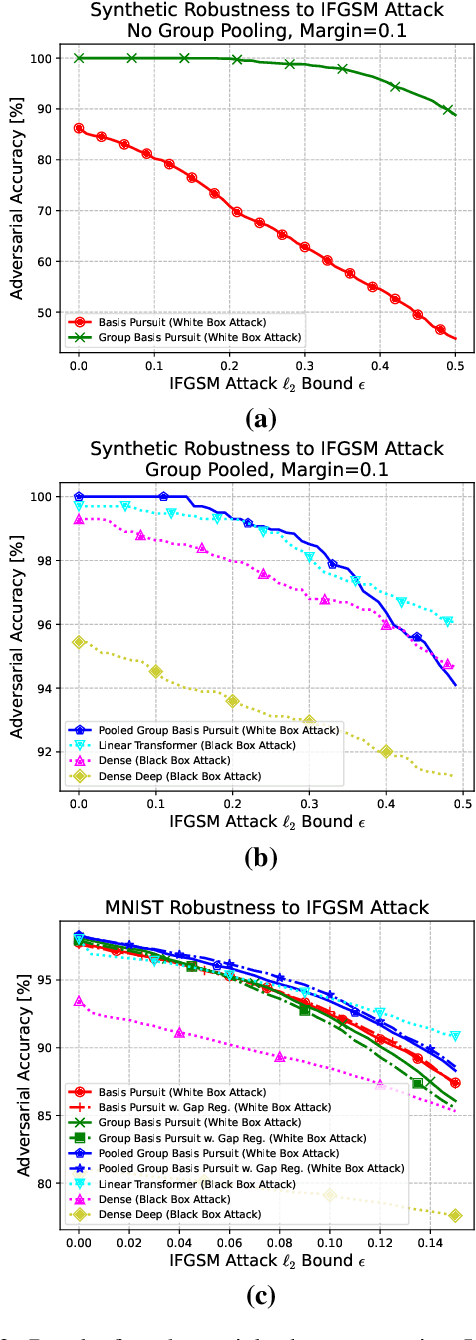
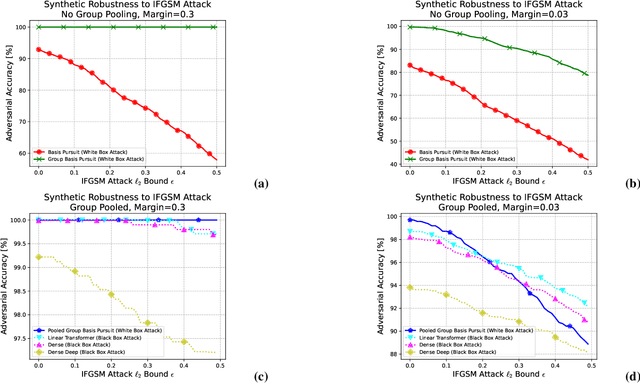
While deep neural networks are sensitive to adversarial noise, sparse coding using the Basis Pursuit (BP) method is robust against such attacks, including its multi-layer extensions. We prove that the stability theorem of BP holds upon the following generalizations: (i) the regularization procedure can be separated into disjoint groups with different weights, (ii) neurons or full layers may form groups, and (iii) the regularizer takes various generalized forms of the $\ell_1$ norm. This result provides the proof for the architectural generalizations of Cazenavette et al. (2021), including (iv) an approximation of the complete architecture as a shallow sparse coding network. Due to this approximation, we settled to experimenting with shallow networks and studied their robustness against the Iterative Fast Gradient Sign Method on a synthetic dataset and MNIST. We introduce classification based on the $\ell_2$ norms of the groups and show numerically that it can be accurate and offers considerable speedups. In this family, linear transformer shows the best performance. Based on the theoretical results and the numerical simulations, we highlight numerical matters that may improve performance further.
GAN-based Multiple Adjacent Brain MRI Slice Reconstruction for Unsupervised Alzheimer's Disease Diagnosis
Jul 08, 2019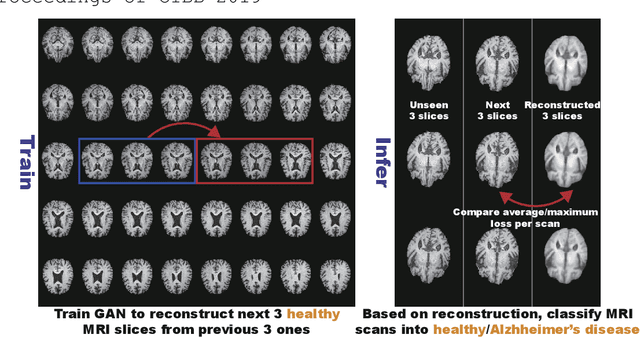
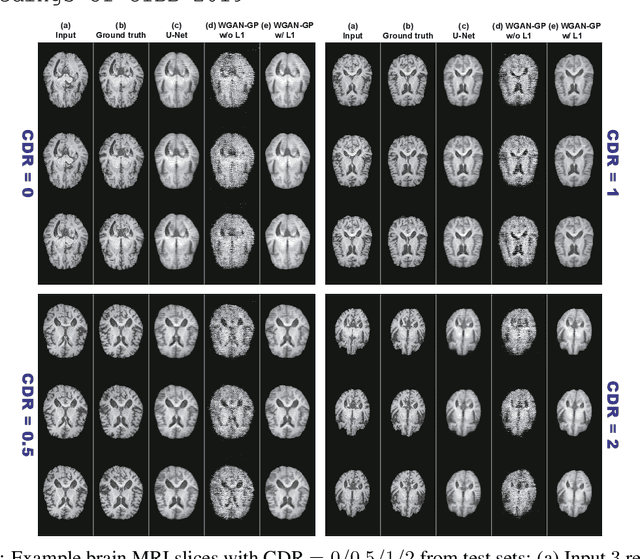
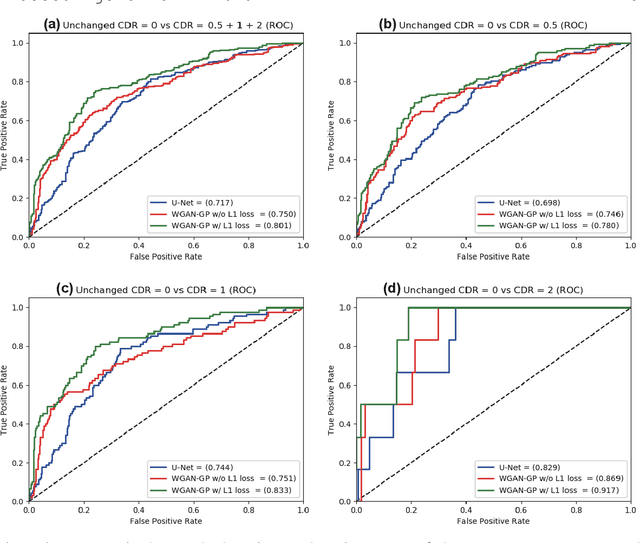
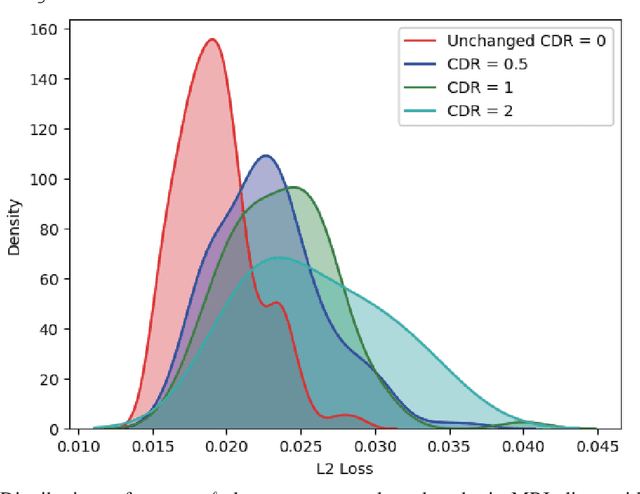
Unsupervised learning can discover various unseen diseases, relying on large-scale unannotated medical images of healthy subjects. Towards this, unsupervised methods reconstruct a single medical image to detect outliers either in the learned feature space or from high reconstruction loss. However, without considering continuity between multiple adjacent images, they cannot directly discriminate diseases composed of the accumulation of subtle anatomical anomalies, such as Alzheimer's Disease (AD). Moreover, no study shows how unsupervised anomaly detection is associated with disease stages. Therefore, we propose a two-step method using Generative Adversarial Network-based multiple adjacent brain MRI slice reconstruction to detect AD at various stages: (Reconstruction) Wasserstein loss with Gradient Penalty + L1 loss---trained on 3 healthy slices to reconstruct the next 3 ones---reconstructs unseen healthy/AD cases; (Diagnosis) Average/Maximum loss (e.g., L2 loss) per scan discriminates them, comparing the reconstructed/ground truth images. The results show that we can reliably detect AD at a very early stage with Area Under the Curve (AUC) 0.780 while also detecting AD at a late stage much more accurately with AUC 0.917; since our method is unsupervised, it should also discover and alert any anomalies including rare disease.
Cognitive Deep Machine Can Train Itself
Dec 02, 2016


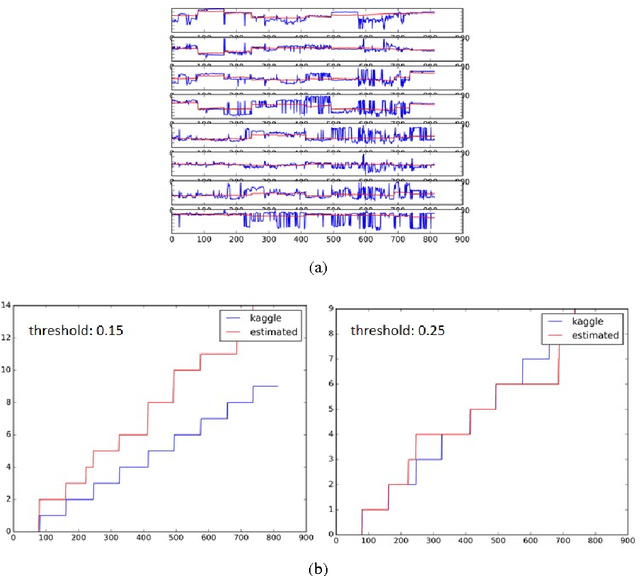
Machine learning is making substantial progress in diverse applications. The success is mostly due to advances in deep learning. However, deep learning can make mistakes and its generalization abilities to new tasks are questionable. We ask when and how one can combine network outputs, when (i) details of the observations are evaluated by learned deep components and (ii) facts and confirmation rules are available in knowledge based systems. We show that in limited contexts the required number of training samples can be low and self-improvement of pre-trained networks in more general context is possible. We argue that the combination of sparse outlier detection with deep components that can support each other diminish the fragility of deep methods, an important requirement for engineering applications. We argue that supervised learning of labels may be fully eliminated under certain conditions: a component based architecture together with a knowledge based system can train itself and provide high quality answers. We demonstrate these concepts on the State Farm Distracted Driver Detection benchmark. We argue that the view of the Study Panel (2016) may overestimate the requirements on `years of focused research' and `careful, unique construction' for `AI systems'.