 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Supervised Method for Body Part Segmentation and Keypoint Detection of Rat Images
May 07, 2024

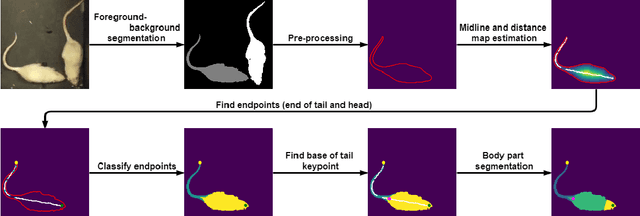
Recognition of individual components and keypoint detection supported by instance segmentation is crucial to analyze the behavior of agents on the scene. Such systems could be used for surveillance, self-driving cars, and also for medical research, where behavior analysis of laboratory animals is used to confirm the aftereffects of a given medicine. A method capable of solving the aforementioned tasks usually requires a large amount of high-quality hand-annotated data, which takes time and money to produce. In this paper, we propose a method that alleviates the need for manual labeling of laboratory rats. To do so, first, we generate initial annotations with a computer vision-based approach, then through extensive augmentation, we train a deep neural network on the generated data. The final system is capable of instance segmentation, keypoint detection, and body part segmentation even when the objects are heavily occluded.
Structural Extensions of Basis Pursuit: Guarantees on Adversarial Robustness
May 05, 2022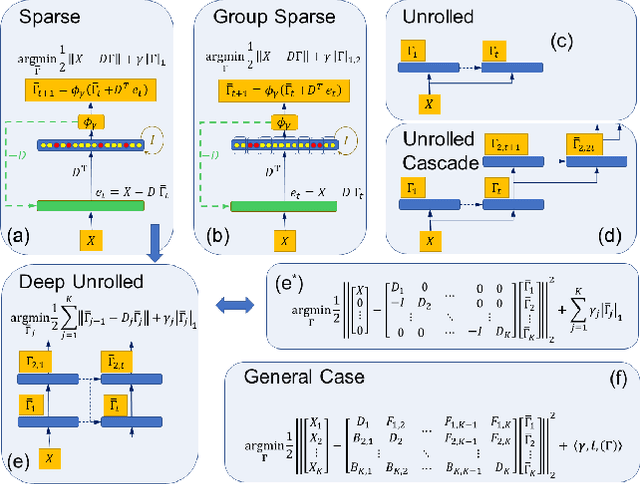
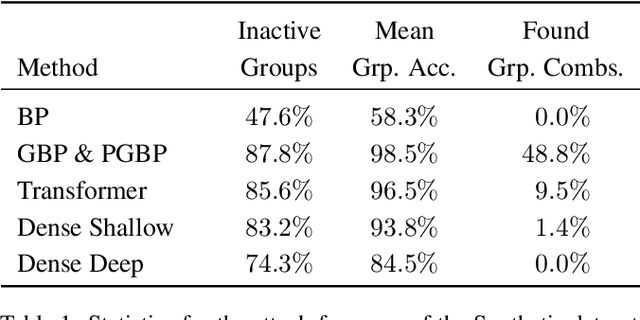
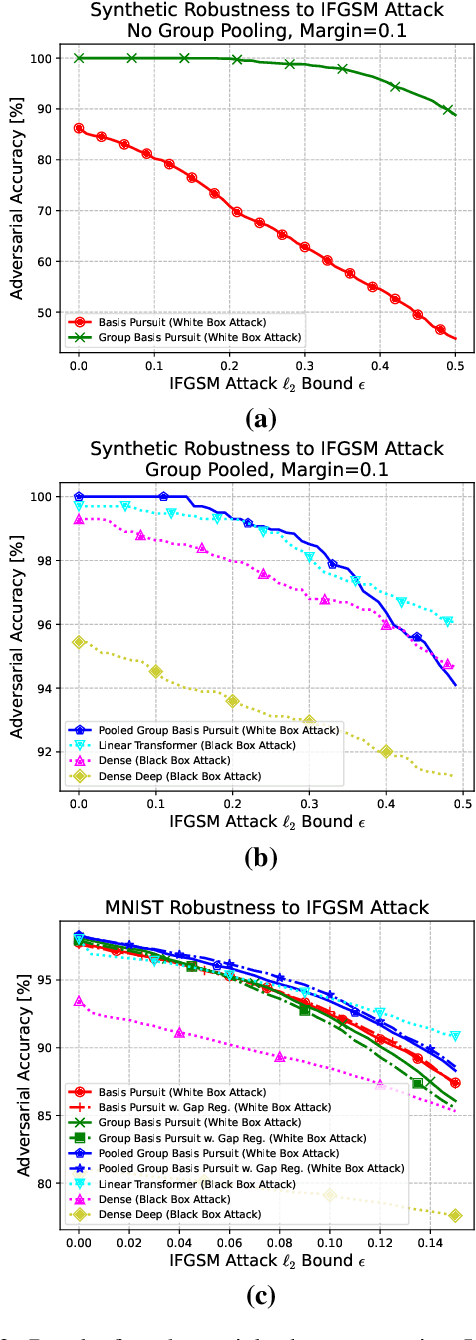
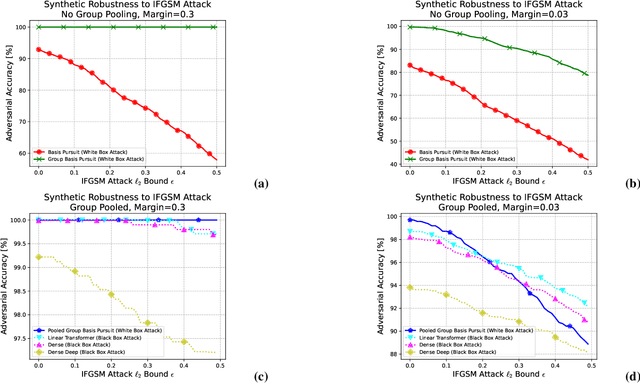
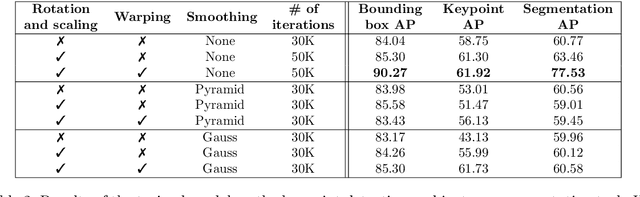
While deep neural networks are sensitive to adversarial noise, sparse coding using the Basis Pursuit (BP) method is robust against such attacks, including its multi-layer extensions. We prove that the stability theorem of BP holds upon the following generalizations: (i) the regularization procedure can be separated into disjoint groups with different weights, (ii) neurons or full layers may form groups, and (iii) the regularizer takes various generalized forms of the $\ell_1$ norm. This result provides the proof for the architectural generalizations of Cazenavette et al. (2021), including (iv) an approximation of the complete architecture as a shallow sparse coding network. Due to this approximation, we settled to experimenting with shallow networks and studied their robustness against the Iterative Fast Gradient Sign Method on a synthetic dataset and MNIST. We introduce classification based on the $\ell_2$ norms of the groups and show numerically that it can be accurate and offers considerable speedups. In this family, linear transformer shows the best performance. Based on the theoretical results and the numerical simulations, we highlight numerical matters that may improve performance further.
Fine-tuning deep CNN models on specific MS COCO categories
Sep 05, 2017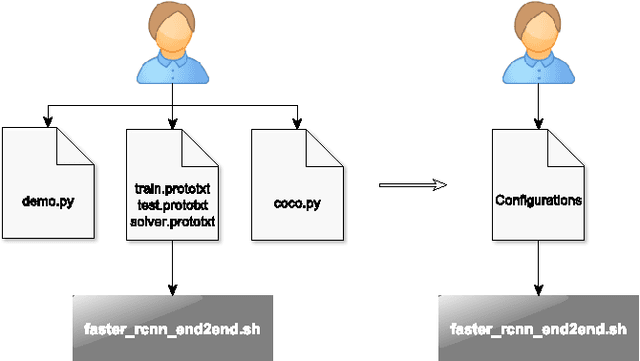
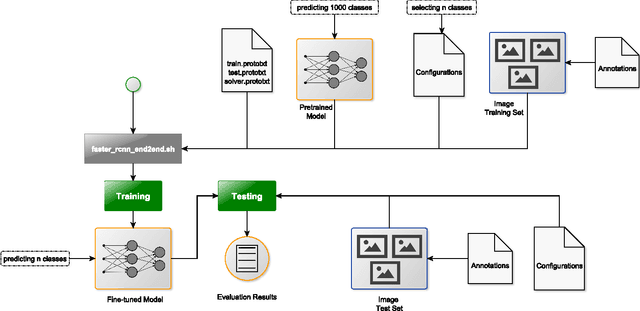

Fine-tuning of a deep convolutional neural network (CNN) is often desired. This paper provides an overview of our publicly available py-faster-rcnn-ft software library that can be used to fine-tune the VGG_CNN_M_1024 model on custom subsets of the Microsoft Common Objects in Context (MS COCO) dataset. For example, we improved the procedure so that the user does not have to look for suitable image files in the dataset by hand which can then be used in the demo program. Our implementation randomly selects images that contain at least one object of the categories on which the model is fine-tuned.
Cognitive Deep Machine Can Train Itself
Dec 02, 2016


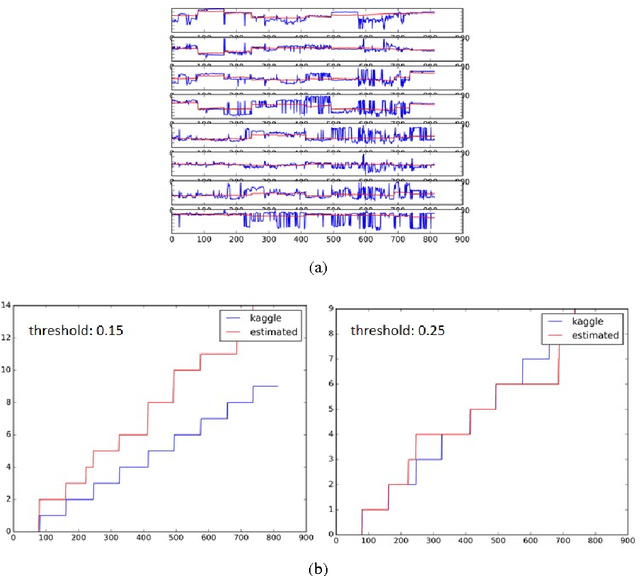
Machine learning is making substantial progress in diverse applications. The success is mostly due to advances in deep learning. However, deep learning can make mistakes and its generalization abilities to new tasks are questionable. We ask when and how one can combine network outputs, when (i) details of the observations are evaluated by learned deep components and (ii) facts and confirmation rules are available in knowledge based systems. We show that in limited contexts the required number of training samples can be low and self-improvement of pre-trained networks in more general context is possible. We argue that the combination of sparse outlier detection with deep components that can support each other diminish the fragility of deep methods, an important requirement for engineering applications. We argue that supervised learning of labels may be fully eliminated under certain conditions: a component based architecture together with a knowledge based system can train itself and provide high quality answers. We demonstrate these concepts on the State Farm Distracted Driver Detection benchmark. We argue that the view of the Study Panel (2016) may overestimate the requirements on `years of focused research' and `careful, unique construction' for `AI systems'.