 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Who's Afraid of Adversarial Transferability?
May 05, 2021



Adversarial transferability, namely the ability of adversarial perturbations to simultaneously fool multiple learning models, has long been the "big bad wolf" of adversarial machine learning. Successful transferability-based attacks requiring no prior knowledge of the attacked model's parameters or training data have been demonstrated numerous times in the past, implying that machine learning models pose an inherent security threat to real-life systems. However, all of the research performed in this area regarded transferability as a probabilistic property and attempted to estimate the percentage of adversarial examples that are likely to mislead a target model given some predefined evaluation set. As a result, those studies ignored the fact that real-life adversaries are often highly sensitive to the cost of a failed attack. We argue that overlooking this sensitivity has led to an exaggerated perception of the transferability threat, when in fact real-life transferability-based attacks are quite unlikely. By combining theoretical reasoning with a series of empirical results, we show that it is practically impossible to predict whether a given adversarial example is transferable to a specific target model in a black-box setting, hence questioning the validity of adversarial transferability as a real-life attack tool for adversaries that are sensitive to the cost of a failed attack.
Not All Datasets Are Born Equal: On Heterogeneous Data and Adversarial Examples
Oct 07, 2020



Recent work on adversarial learning has focused mainly on neural networks and domains where they excel, such as computer vision. The data in these domains is homogeneous, whereas heterogeneous tabular data domains remain underexplored despite their prevalence. Constructing an attack on models with heterogeneous input spaces is challenging, as they are governed by complex domain-specific validity rules and comprised of nominal, ordinal, and numerical features. We argue that machine learning models trained on heterogeneous tabular data are as susceptible to adversarial manipulations as those trained on continuous or homogeneous data such as images. In this paper, we introduce an optimization framework for identifying adversarial perturbations in heterogeneous input spaces. We define distribution-aware constraints for preserving the consistency of the adversarial examples and incorporate them by embedding the heterogeneous input into a continuous latent space. Our approach focuses on an adversary who aims to craft valid perturbations of minimal l_0-norms and apply them in real life. We propose a neural network-based implementation of our approach and demonstrate its effectiveness using three datasets from different content domains. Our results suggest that despite the several constraints heterogeneity imposes on the input space of a machine learning model, the susceptibility to adversarial examples remains unimpaired.
Adversarial robustness via stochastic regularization of neural activation sensitivity
Sep 23, 2020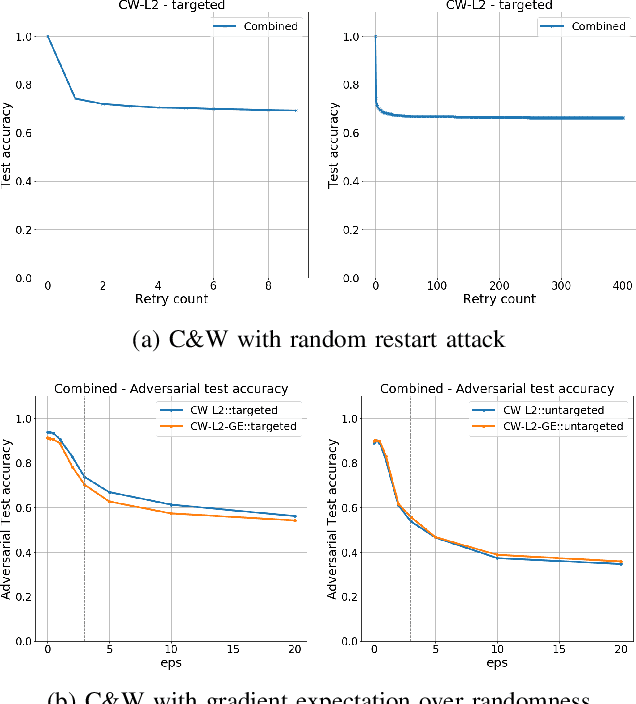
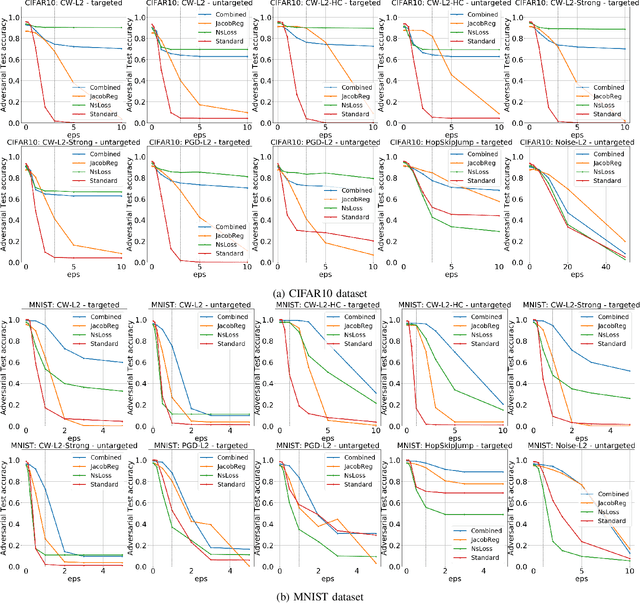
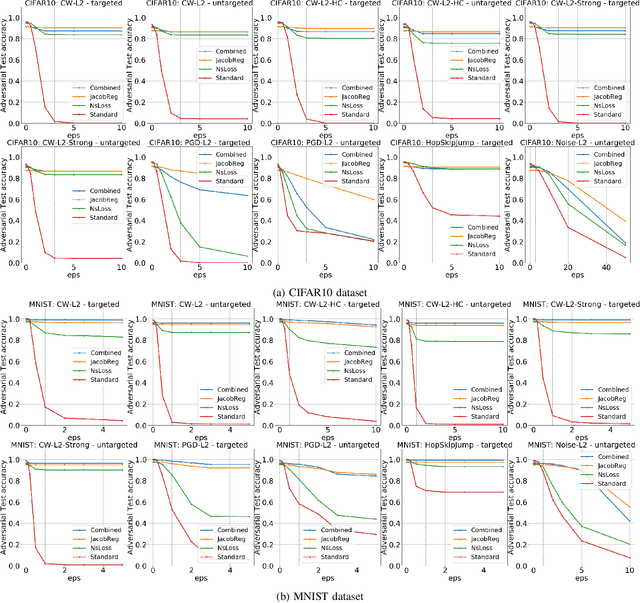
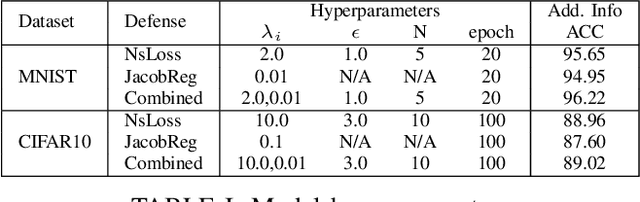
Recent works have shown that the input domain of any machine learning classifier is bound to contain adversarial examples. Thus we can no longer hope to immune classifiers against adversarial examples and instead can only aim to achieve the following two defense goals: 1) making adversarial examples harder to find, or 2) weakening their adversarial nature by pushing them further away from correctly classified data points. Most if not all the previously suggested defense mechanisms attend to just one of those two goals, and as such, could be bypassed by adaptive attacks that take the defense mechanism into consideration. In this work we suggest a novel defense mechanism that simultaneously addresses both defense goals: We flatten the gradients of the loss surface, making adversarial examples harder to find, using a novel stochastic regularization term that explicitly decreases the sensitivity of individual neurons to small input perturbations. In addition, we push the decision boundary away from correctly classified inputs by leveraging Jacobian regularization. We present a solid theoretical basis and an empirical testing of our suggested approach, demonstrate its superiority over previously suggested defense mechanisms, and show that it is effective against a wide range of adaptive attacks.
Why Blocking Targeted Adversarial Perturbations Impairs the Ability to Learn
Jul 11, 2019



Despite their accuracy, neural network-based classifiers are still prone to manipulation through adversarial perturbations. Those perturbations are designed to be misclassified by the neural network, while being perceptually identical to some valid input. The vast majority of attack methods rely on white-box conditions, where the attacker has full knowledge of the attacked network's parameters. This allows the attacker to calculate the network's loss gradient with respect to some valid input and use this gradient in order to create an adversarial example. The task of blocking white-box attacks has proven difficult to solve. While a large number of defense methods have been suggested, they have had limited success. In this work we examine this difficulty and try to understand it. We systematically explore the abilities and limitations of defensive distillation, one of the most promising defense mechanisms against adversarial perturbations suggested so far in order to understand the defense challenge. We show that contrary to commonly held belief, the ability to bypass defensive distillation is not dependent on an attack's level of sophistication. In fact, simple approaches, such as the Targeted Gradient Sign Method, are capable of effectively bypassing defensive distillation. We prove that defensive distillation is highly effective against non-targeted attacks but is unsuitable for targeted attacks. This discovery leads us to realize that targeted attacks leverage the same input gradient that allows a network to be trained. This implies that blocking them will require losing the network's ability to learn, presenting an impossible tradeoff to the research community.
Detecting Adversarial Perturbations Through Spatial Behavior in Activation Spaces
Dec 04, 2018



Neural network based classifiers are still prone to manipulation through adversarial perturbations. State of the art attacks can overcome most of the defense or detection mechanisms suggested so far, and adversaries have the upper hand in this arms race. Adversarial examples are designed to resemble the normal input from which they were constructed, while triggering an incorrect classification. This basic design goal leads to a characteristic spatial behavior within the context of Activation Spaces, a term coined by the authors to refer to the hyperspaces formed by the activation values of the network's layers. Within the output of the first layers of the network, an adversarial example is likely to resemble normal instances of the source class, while in the final layers such examples will diverge towards the adversary's target class. The steps below enable us to leverage this inherent shift from one class to another in order to form a novel adversarial example detector. We construct Euclidian spaces out of the activation values of each of the deep neural network layers. Then, we induce a set of k-nearest neighbor classifiers (k-NN), one per activation space of each neural network layer, using the non-adversarial examples. We leverage those classifiers to produce a sequence of class labels for each nonperturbed input sample and estimate the a priori probability for a class label change between one activation space and another. During the detection phase we compute a sequence of classification labels for each input using the trained classifiers. We then estimate the likelihood of those classification sequences and show that adversarial sequences are far less likely than normal ones. We evaluated our detection method against the state of the art C&W attack method, using two image classification datasets (MNIST, CIFAR-10) reaching an AUC 0f 0.95 for the CIFAR-10 dataset.