 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Interpretability via Regularization of Neural Activation Sensitivity
Nov 16, 2022



State-of-the-art deep neural networks (DNNs) are highly effective at tackling many real-world tasks. However, their wide adoption in mission-critical contexts is hampered by two major weaknesses - their susceptibility to adversarial attacks and their opaqueness. The former raises concerns about the security and generalization of DNNs in real-world conditions, whereas the latter impedes users' trust in their output. In this research, we (1) examine the effect of adversarial robustness on interpretability and (2) present a novel approach for improving the interpretability of DNNs that is based on regularization of neural activation sensitivity. We evaluate the interpretability of models trained using our method to that of standard models and models trained using state-of-the-art adversarial robustness techniques. Our results show that adversarially robust models are superior to standard models and that models trained using our proposed method are even better than adversarially robust models in terms of interpretability.
Adversarial robustness via stochastic regularization of neural activation sensitivity
Sep 23, 2020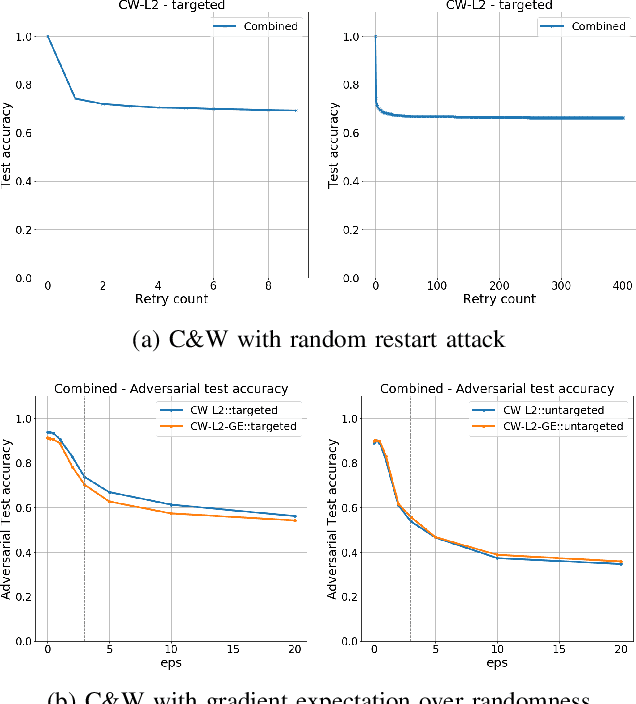
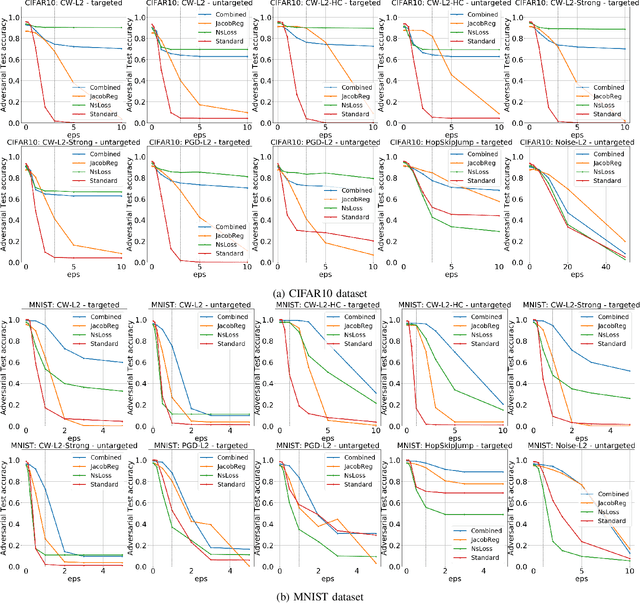
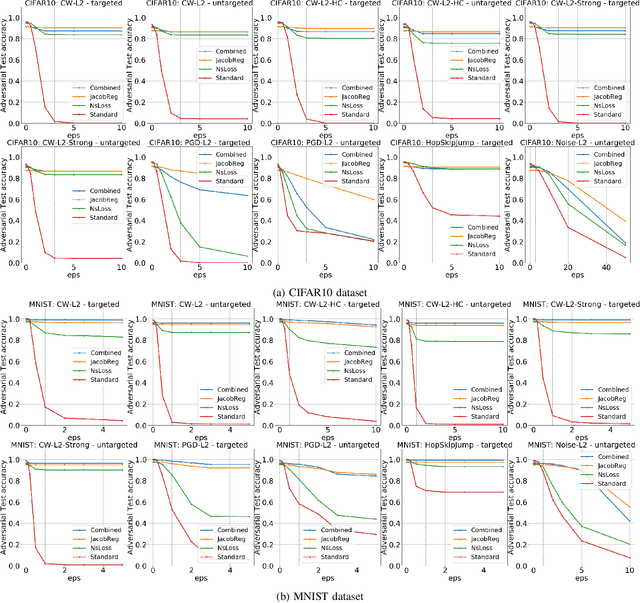
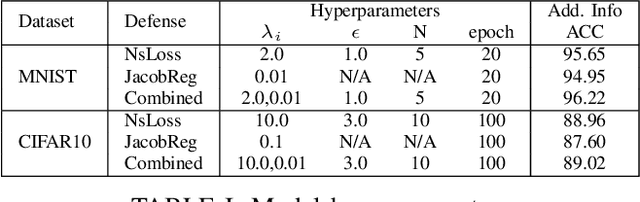
Recent works have shown that the input domain of any machine learning classifier is bound to contain adversarial examples. Thus we can no longer hope to immune classifiers against adversarial examples and instead can only aim to achieve the following two defense goals: 1) making adversarial examples harder to find, or 2) weakening their adversarial nature by pushing them further away from correctly classified data points. Most if not all the previously suggested defense mechanisms attend to just one of those two goals, and as such, could be bypassed by adaptive attacks that take the defense mechanism into consideration. In this work we suggest a novel defense mechanism that simultaneously addresses both defense goals: We flatten the gradients of the loss surface, making adversarial examples harder to find, using a novel stochastic regularization term that explicitly decreases the sensitivity of individual neurons to small input perturbations. In addition, we push the decision boundary away from correctly classified inputs by leveraging Jacobian regularization. We present a solid theoretical basis and an empirical testing of our suggested approach, demonstrate its superiority over previously suggested defense mechanisms, and show that it is effective against a wide range of adaptive attacks.
When Explainability Meets Adversarial Learning: Detecting Adversarial Examples using SHAP Signatures
Sep 08, 2019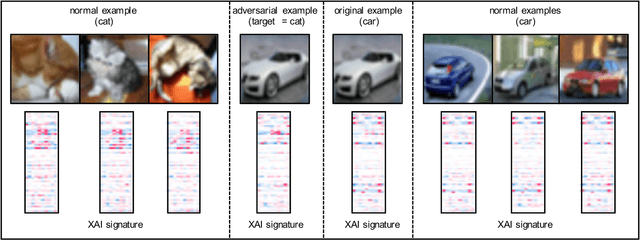
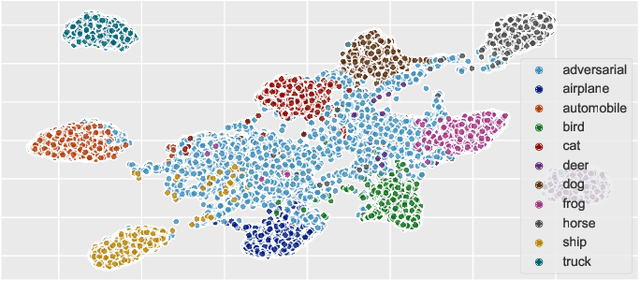

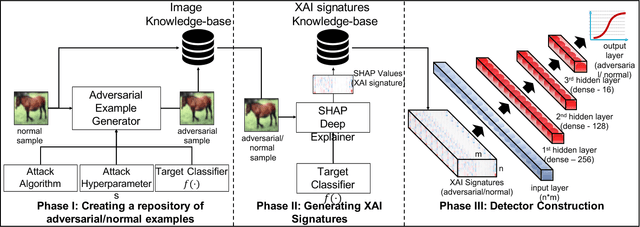
State-of-the-art deep neural networks (DNNs) are highly effective in solving many complex real-world problems. However, these models are vulnerable to adversarial perturbation attacks, and despite the plethora of research in this domain, to this day, adversaries still have the upper hand in the cat and mouse game of adversarial example generation methods vs. detection and prevention methods. In this research, we present a novel detection method that uses Shapley Additive Explanations (SHAP) values computed for the internal layers of a DNN classifier to discriminate between normal and adversarial inputs. We evaluate our method by building an extensive dataset of adversarial examples over the popular CIFAR-10 and MNIST datasets, and training a neural network-based detector to distinguish between normal and adversarial inputs. We evaluate our detector against adversarial examples generated by diverse state-of-the-art attacks and demonstrate its high detection accuracy and strong generalization ability to adversarial inputs generated with different attack methods.