 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Explainability Meets Adversarial Learning: Detecting Adversarial Examples using SHAP Signatures
Paper and Code
Sep 08, 2019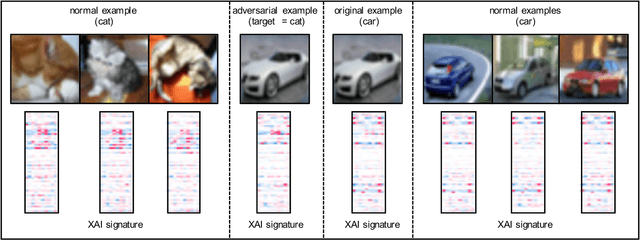
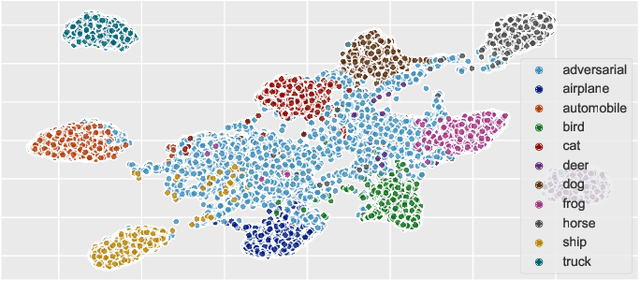

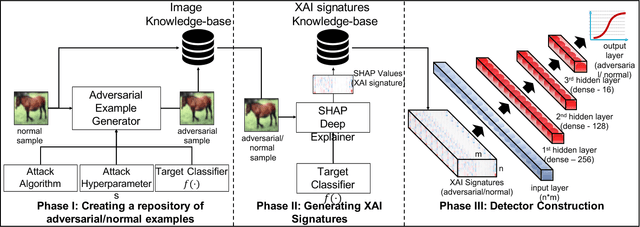
State-of-the-art deep neural networks (DNNs) are highly effective in solving many complex real-world problems. However, these models are vulnerable to adversarial perturbation attacks, and despite the plethora of research in this domain, to this day, adversaries still have the upper hand in the cat and mouse game of adversarial example generation methods vs. detection and prevention methods. In this research, we present a novel detection method that uses Shapley Additive Explanations (SHAP) values computed for the internal layers of a DNN classifier to discriminate between normal and adversarial inputs. We evaluate our method by building an extensive dataset of adversarial examples over the popular CIFAR-10 and MNIST datasets, and training a neural network-based detector to distinguish between normal and adversarial inputs. We evaluate our detector against adversarial examples generated by diverse state-of-the-art attacks and demonstrate its high detection accuracy and strong generalization ability to adversarial inputs generated with different attack methods.