 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Motion Video Super-Resolution with Dual Subnet and Multi-Stage Communicated Upsampling
Mar 22, 2021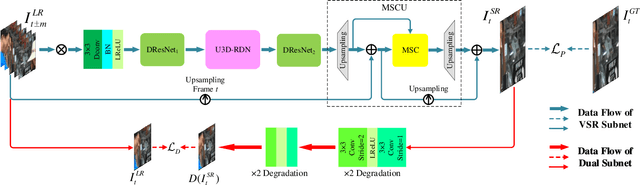


Video super-resolution (VSR) aims at restoring a video in low-resolution (LR) and improving it to higher-resolution (HR). Due to the characteristics of video tasks, it is very important that motion information among frames should be well concerned, summarized and utilized for guidance in a VSR algorithm. Especially, when a video contains large motion, conventional methods easily bring incoherent results or artifacts. In this paper, we propose a novel deep neural network with Dual Subnet and Multi-stage Communicated Upsampling (DSMC) for super-resolution of videos with large motion. We design a new module named U-shaped residual dense network with 3D convolution (U3D-RDN) for fine implicit motion estimation and motion compensation (MEMC) as well as coarse spatial feature extraction. And we present a new Multi-Stage Communicated Upsampling (MSCU) module to make full use of the intermediate results of upsampling for guiding the VSR. Moreover, a novel dual subnet is devised to aid the training of our DSMC, whose dual loss helps to reduce the solution space as well as enhance the generalization ability. Our experimental results confirm that our method achieves superior performance on videos with large motion compared to state-of-the-art methods.
A Single Frame and Multi-Frame Joint Network for 360-degree Panorama Video Super-Resolution
Aug 24, 2020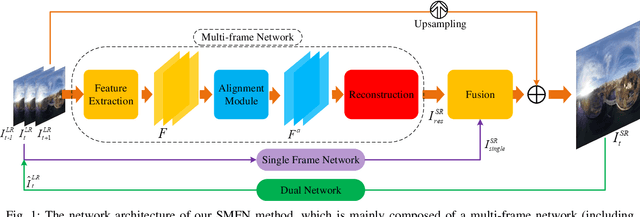
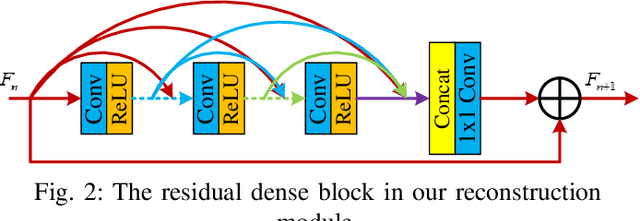
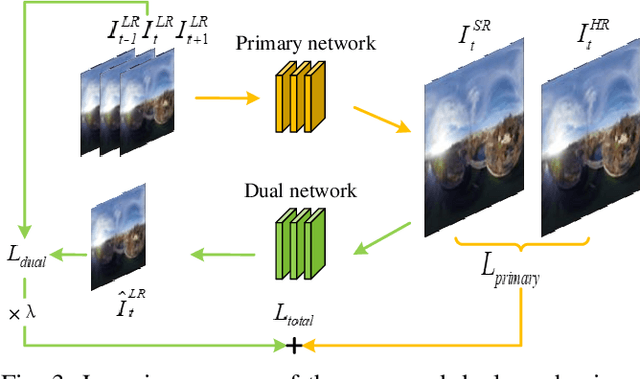

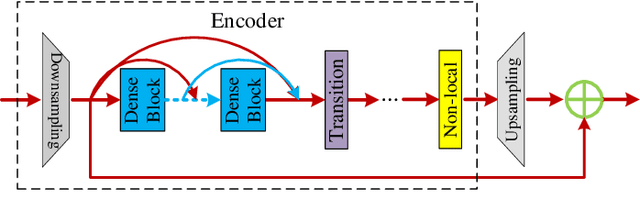
Spherical videos, also known as \ang{360} (panorama) videos, can be viewed with various virtual reality devices such as computers and head-mounted displays. They attract large amount of interest since awesome immersion can be experienced when watching spherical videos. However, capturing, storing and transmitting high-resolution spherical videos are extremely expensive. In this paper, we propose a novel single frame and multi-frame joint network (SMFN) for recovering high-resolution spherical videos from low-resolution inputs. To take advantage of pixel-level inter-frame consistency, deformable convolutions are used to eliminate the motion difference between feature maps of the target frame and its neighboring frames. A mixed attention mechanism is devised to enhance the feature representation capability. The dual learning strategy is exerted to constrain the space of solution so that a better solution can be found. A novel loss function based on the weighted mean square error is proposed to emphasize on the super-resolution of the equatorial regions. This is the first attempt to settle the super-resolution of spherical videos, and we collect a novel dataset from the Internet, MiG Panorama Video, which includes 204 videos. Experimental results on 4 representative video clips demonstrate the efficacy of the proposed method. The dataset and code are available at https://github.com/lovepiano/SMFN_For_360VSR.
Video Super Resolution Based on Deep Learning: A comprehensive survey
Jul 25, 2020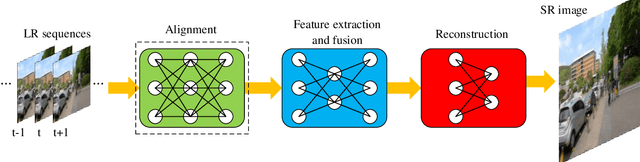
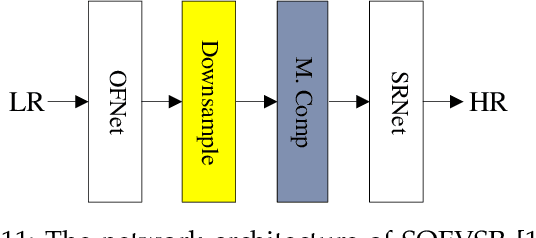
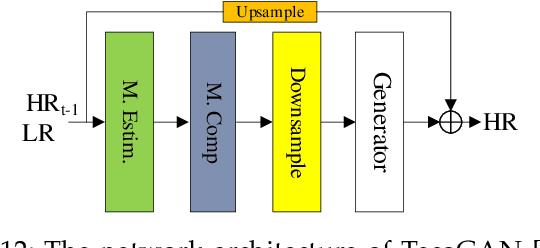
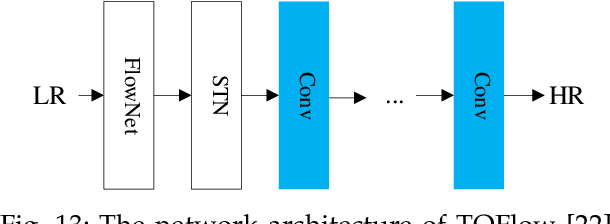
In recent years, deep learning has made great progress in the fields of image recognition, video analysis, natural language processing and speech recognition, including video super-resolution tasks. In this survey, we comprehensively investigate 28 state-of-the-art video super-resolution methods based on deep learning. It is well known that the leverage of information within video frames is important for video super-resolution. Hence we propose a taxonomy and classify the methods into six sub-categories according to the ways of utilizing inter-frame information. Moreover, the architectures and implementation details (including input and output, loss function and learning rate) of all the methods are depicted in details. Finally, we summarize and compare their performance on some benchmark datasets under different magnification factors. We also discuss some challenges, which need to be further addressed by researchers in the community of video super-resolution. Therefore, this work is expected to make a contribution to the future development of research in video super-resolution, and alleviate understandability and transferability of existing and future techniques into practice.