 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Sparse Autoencoders Identify Reasoning Features in Language Models?
Jan 09, 2026We investigate whether sparse autoencoders (SAEs) identify genuine reasoning features in large language models (LLMs). Starting from features selected using standard contrastive activation methods, we introduce a falsification-oriented framework that combines causal token injection experiments and LLM-guided falsification to test whether feature activation reflects reasoning processes or superficial linguistic correlates. Across 20 configurations spanning multiple model families, layers, and reasoning datasets, we find that identified reasoning features are highly sensitive to token-level interventions. Injecting a small number of feature-associated tokens into non-reasoning text is sufficient to elicit strong activation for 59% to 94% of features, indicating reliance on lexical artifacts. For the remaining features that are not explained by simple token triggers, LLM-guided falsification consistently produces non-reasoning inputs that activate the feature and reasoning inputs that do not, with no analyzed feature satisfying our criteria for genuine reasoning behavior. Steering these features yields minimal changes or slight degradations in benchmark performance. Together, these results suggest that SAE features identified by contrastive approaches primarily capture linguistic correlates of reasoning rather than the underlying reasoning computations themselves.
Hybrid Meta-learners for Estimating Heterogeneous Treatment Effects
Jun 16, 2025Estimating conditional average treatment effects (CATE) from observational data involves modeling decisions that differ from supervised learning, particularly concerning how to regularize model complexity. Previous approaches can be grouped into two primary "meta-learner" paradigms that impose distinct inductive biases. Indirect meta-learners first fit and regularize separate potential outcome (PO) models and then estimate CATE by taking their difference, whereas direct meta-learners construct and directly regularize estimators for the CATE function itself. Neither approach consistently outperforms the other across all scenarios: indirect learners perform well when the PO functions are simple, while direct learners outperform when the CATE is simpler than individual PO functions. In this paper, we introduce the Hybrid Learner (H-learner), a novel regularization strategy that interpolates between the direct and indirect regularizations depending on the dataset at hand. The H-learner achieves this by learning intermediate functions whose difference closely approximates the CATE without necessarily requiring accurate individual approximations of the POs themselves. We demonstrate empirically that intentionally allowing suboptimal fits to the POs improves the bias-variance tradeoff in estimating CATE. Experiments conducted on semi-synthetic and real-world benchmark datasets illustrate that the H-learner consistently operates at the Pareto frontier, effectively combining the strengths of both direct and indirect meta-learners.
Local MDI+: Local Feature Importances for Tree-Based Models
Jun 10, 2025Tree-based ensembles such as random forests remain the go-to for tabular data over deep learning models due to their prediction performance and computational efficiency. These advantages have led to their widespread deployment in high-stakes domains, where interpretability is essential for ensuring trustworthy predictions. This has motivated the development of popular local (i.e. sample-specific) feature importance (LFI) methods such as LIME and TreeSHAP. However, these approaches rely on approximations that ignore the model's internal structure and instead depend on potentially unstable perturbations. These issues are addressed in the global setting by MDI+, a feature importance method which exploits an equivalence between decision trees and linear models on a transformed node basis. However, the global MDI+ scores are not able to explain predictions when faced with heterogeneous individual characteristics. To address this gap, we propose Local MDI+ (LMDI+), a novel extension of the MDI+ framework to the sample specific setting. LMDI+ outperforms existing baselines LIME and TreeSHAP in identifying instance-specific signal features, averaging a 10% improvement in downstream task performance across twelve real-world benchmark datasets. It further demonstrates greater stability by consistently producing similar instance-level feature importance rankings across multiple random forest fits. Finally, LMDI+ enables local interpretability use cases, including the identification of closer counterfactuals and the discovery of homogeneous subgroups.
Treatment Non-Adherence Bias in Clinical Machine Learning: A Real-World Study on Hypertension Medication
Feb 26, 2025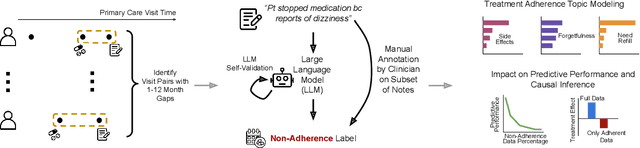
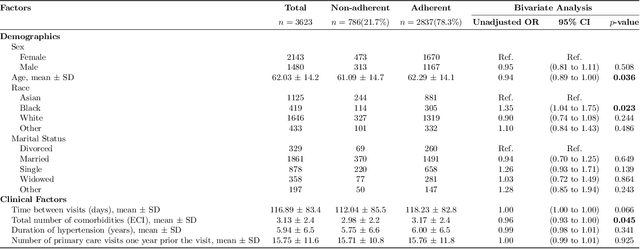
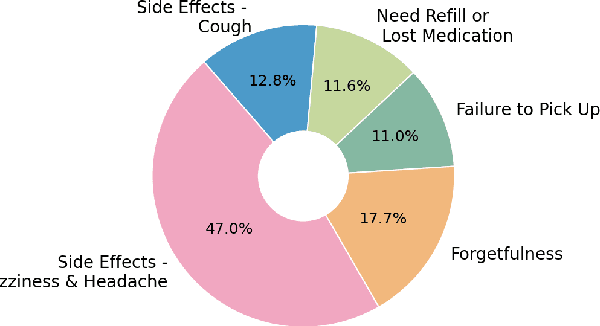
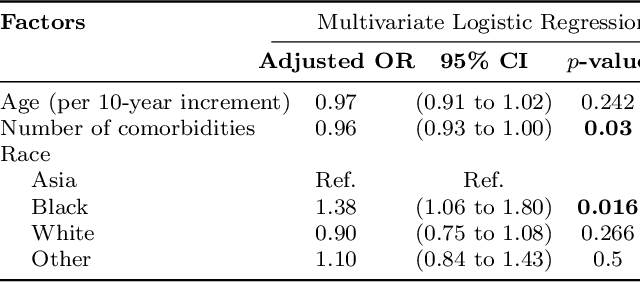
Machine learning systems trained on electronic health records (EHRs) increasingly guide treatment decisions, but their reliability depends on the critical assumption that patients follow the prescribed treatments recorded in EHRs. Using EHR data from 3,623 hypertension patients, we investigate how treatment non-adherence introduces implicit bias that can fundamentally distort both causal inference and predictive modeling. By extracting patient adherence information from clinical notes using a large language model, we identify 786 patients (21.7%) with medication non-adherence. We further uncover key demographic and clinical factors associated with non-adherence, as well as patient-reported reasons including side effects and difficulties obtaining refills. Our findings demonstrate that this implicit bias can not only reverse estimated treatment effects, but also degrade model performance by up to 5% while disproportionately affecting vulnerable populations by exacerbating disparities in decision outcomes and model error rates. This highlights the importance of accounting for treatment non-adherence in developing responsible and equitable clinical machine learning systems.
A Learning Based Hypothesis Test for Harmful Covariate Shift
Dec 07, 2022The ability to quickly and accurately identify covariate shift at test time is a critical and often overlooked component of safe machine learning systems deployed in high-risk domains. While methods exist for detecting when predictions should not be made on out-of-distribution test examples, identifying distributional level differences between training and test time can help determine when a model should be removed from the deployment setting and retrained. In this work, we define harmful covariate shift (HCS) as a change in distribution that may weaken the generalization of a predictive model. To detect HCS, we use the discordance between an ensemble of classifiers trained to agree on training data and disagree on test data. We derive a loss function for training this ensemble and show that the disagreement rate and entropy represent powerful discriminative statistics for HCS. Empirically, we demonstrate the ability of our method to detect harmful covariate shift with statistical certainty on a variety of high-dimensional datasets. Across numerous domains and modalities, we show state-of-the-art performance compared to existing methods, particularly when the number of observed test samples is small.