 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte-Carlo Tree Search for Behavior Planning in Autonomous Driving
Oct 18, 2023The integration of autonomous vehicles into urban and highway environments necessitates the development of robust and adaptable behavior planning systems. This study presents an innovative approach to address this challenge by utilizing a Monte-Carlo Tree Search (MCTS) based algorithm for autonomous driving behavior planning. The core objective is to leverage the balance between exploration and exploitation inherent in MCTS to facilitate intelligent driving decisions in complex scenarios. We introduce an MCTS-based algorithm tailored to the specific demands of autonomous driving. This involves the integration of carefully crafted cost functions, encompassing safety, comfort, and passability metrics, into the MCTS framework. The effectiveness of our approach is demonstrated by enabling autonomous vehicles to navigate intricate scenarios, such as intersections, unprotected left turns, cut-ins, and ramps, even under traffic congestion, in real-time. Qualitative instances illustrate the integration of diverse driving decisions, such as lane changes, acceleration, and deceleration, into the MCTS framework. Moreover, quantitative results, derived from examining the impact of iteration time and look-ahead steps on decision quality and real-time applicability, substantiate the robustness of our approach. This robustness is further underscored by the high success rate of the MCTS algorithm across various scenarios.
Multi-Agent Reinforcement Learning for Persistent Monitoring
Nov 02, 2020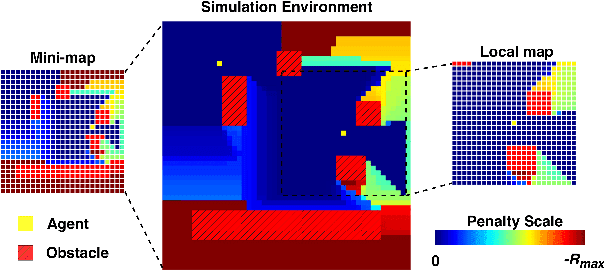
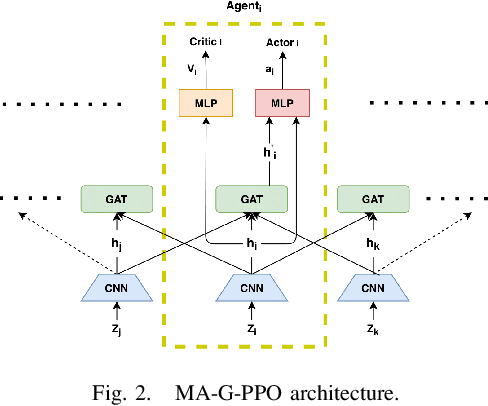

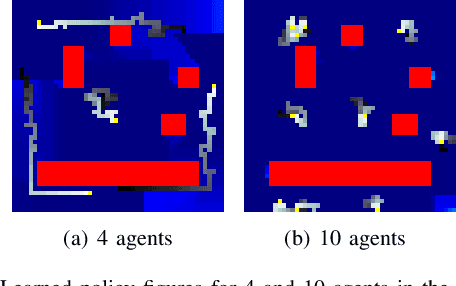
The Persistent Monitoring (PM) problem seeks to find a set of trajectories (or controllers) for robots to persistently monitor a changing environment. Each robot has a limited field-of-view and may need to coordinate with others to ensure no point in the environment is left unmonitored for long periods of time. We model the problem such that there is a penalty that accrues every time step if a point is left unmonitored. However, the dynamics of the penalty are unknown to us. We present a Multi-Agent Reinforcement Learning (MARL) algorithm for the persistent monitoring problem. Specifically, we present a Multi-Agent Graph Attention Proximal Policy Optimization (MA-G-PPO) algorithm that takes as input the local observations of all agents combined with a low resolution global map to learn a policy for each agent. The graph attention allows agents to share their information with others leading to an effective joint policy. Our main focus is to understand how effective MARL is for the PM problem. We investigate five research questions with this broader goal. We find that MA-G-PPO is able to learn a better policy than the non-RL baseline in most cases, the effectiveness depends on agents sharing information with each other, and the policy learnt shows emergent behavior for the agents.
Tree Search Techniques for Minimizing Detectability and Maximizing Visibility
Feb 22, 2019
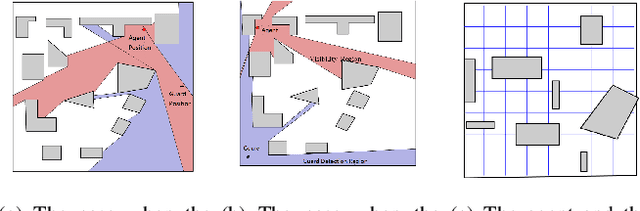
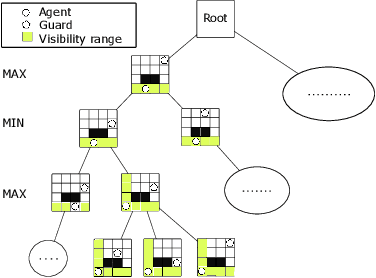
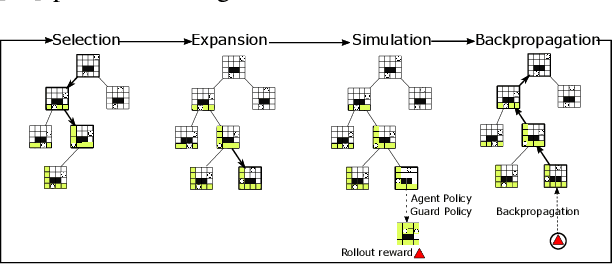
We introduce and study the problem of planning a trajectory for an agent to carry out a scouting mission while avoiding being detected by an adversarial guard. This introduces an adversarial version of classical visibility-based planning problems such as the Watchman Route Problem. The agent receives a positive reward for increasing its visibility and a negative penalty when it is detected by the guard. The objective is to find a finite-horizon path for the agent that balances the trade-off maximizing visibility and minimizing detectability. We model this problem as a sequential two-player zero-sum discrete game. A minimax tree search can give the optimal policy for the agent but requires an exponential-time computation and space. We propose several pruning techniques to reduce the computational cost while still preserving optimality guarantees. Simulation results show that the proposed strategy prunes approximately three orders of magnitude nodes as compared to the brute-force strategy.