 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning for Persistent Monitoring
Nov 02, 2020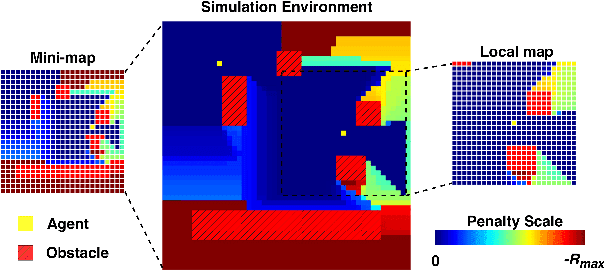
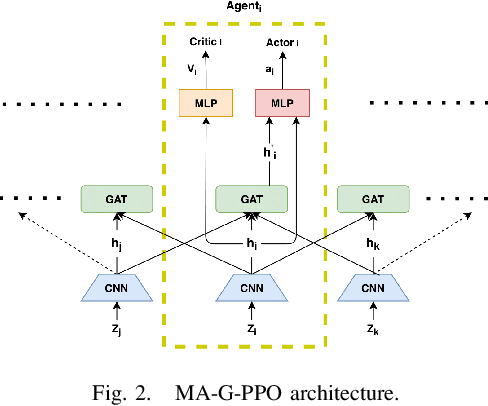

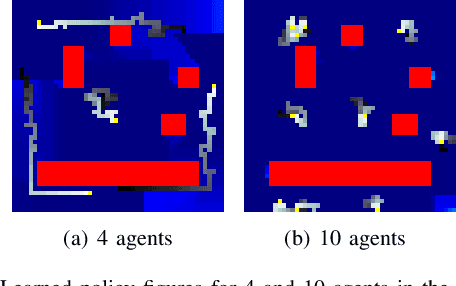
The Persistent Monitoring (PM) problem seeks to find a set of trajectories (or controllers) for robots to persistently monitor a changing environment. Each robot has a limited field-of-view and may need to coordinate with others to ensure no point in the environment is left unmonitored for long periods of time. We model the problem such that there is a penalty that accrues every time step if a point is left unmonitored. However, the dynamics of the penalty are unknown to us. We present a Multi-Agent Reinforcement Learning (MARL) algorithm for the persistent monitoring problem. Specifically, we present a Multi-Agent Graph Attention Proximal Policy Optimization (MA-G-PPO) algorithm that takes as input the local observations of all agents combined with a low resolution global map to learn a policy for each agent. The graph attention allows agents to share their information with others leading to an effective joint policy. Our main focus is to understand how effective MARL is for the PM problem. We investigate five research questions with this broader goal. We find that MA-G-PPO is able to learn a better policy than the non-RL baseline in most cases, the effectiveness depends on agents sharing information with each other, and the policy learnt shows emergent behavior for the agents.