 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARFlow: Spatial Temporal Feature Re-embedding with Attentive Learning for Real-world Scene Flow
Mar 11, 2024Scene flow prediction is a crucial underlying task in understanding dynamic scenes as it offers fundamental motion information. However, contemporary scene flow methods encounter three major challenges. Firstly, flow estimation solely based on local receptive fields lacks long-dependency matching of point pairs. To address this issue, we propose global attentive flow embedding to match all-to-all point pairs in both feature space and Euclidean space, providing global initialization before local refinement. Secondly, there are deformations existing in non-rigid objects after warping, which leads to variations in the spatiotemporal relation between the consecutive frames. For a more precise estimation of residual flow, a spatial temporal feature re-embedding module is devised to acquire the sequence features after deformation. Furthermore, previous methods perform poor generalization due to the significant domain gap between the synthesized and LiDAR-scanned datasets. We leverage novel domain adaptive losses to effectively bridge the gap of motion inference from synthetic to real-world. Experiments demonstrate that our approach achieves state-of-the-art performance across various datasets, with particularly outstanding results on real-world LiDAR-scanned datasets. Our code is available at https://github.com/O-VIGIA/StarFlow.
GMA3D: Local-Global Attention Learning to Estimate Occluded Motions of Scene Flow
Oct 07, 2022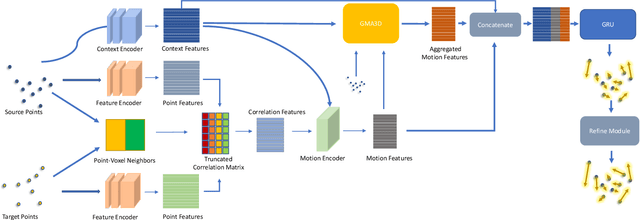
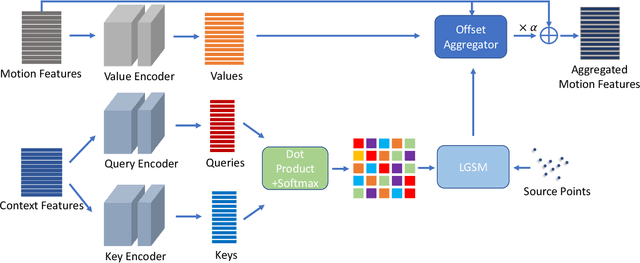

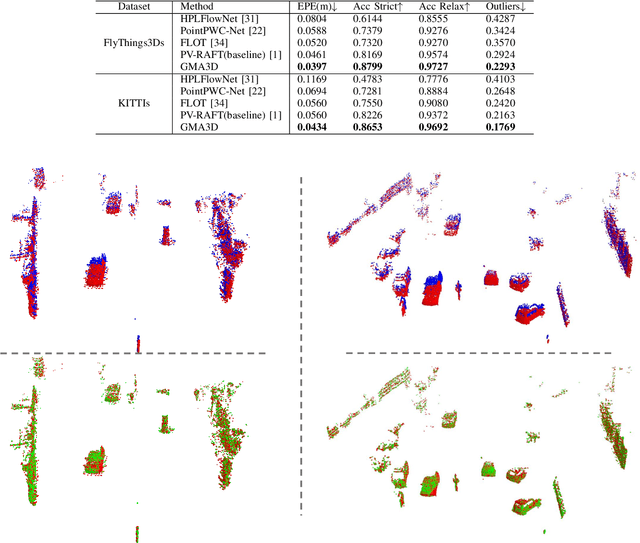
Scene flow is the collection of each point motion information in the 3D point clouds. It is a vital tool applied to many tasks, such as autonomous driving and augmented reality. However, there are always occlusion points between two consecutive point clouds, whether from the sparsity data sampling or real-world occlusion. In this paper, we focus on addressing occlusion issues in scene flow by self-similarity and local consistency of moving objects. We propose a GMA3D module based on the transformer framework, which utilizes local and global similarity to infer the motion information of occluded points from the motion information of local and global non-occluded points respectively, and then uses an offset generator to aggregate them. Our module is the first to apply the transformer-based architecture to gauge the scene flow occlusion problem on point clouds. Experiments show that our GMA3D can solve the occlusion problem in the scene flow, especially in the real scene. We evaluate the proposed method on the occluded version datasets and get state-of-the-art results on the real scene KITTI. To testify that GMA3D is still beneficial for non-occluded scene flow, we also conducted experiments on non-occluded version datasets and achieved state-of-the-art results on FlyThings3D and KITTI. The code is available at https://github.com/O-VIGIA/GMA3D.
A channel attention based MLP-Mixer network for motor imagery decoding with EEG
Oct 21, 2021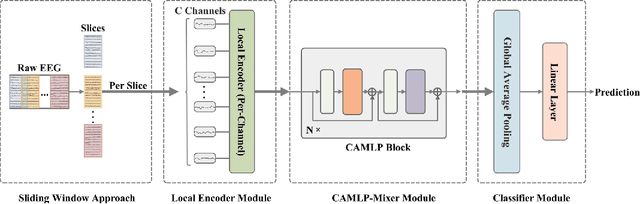
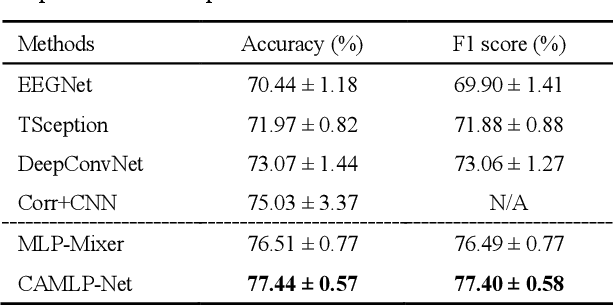
Convolutional neural networks (CNNs) and their variants have been successfully applied to the electroencephalogram (EEG) based motor imagery (MI) decoding task. However, these CNN-based algorithms generally have limitations in perceiving global temporal dependencies of EEG signals. Besides, they also ignore the diverse contributions of different EEG channels to the classification task. To address such issues, a novel channel attention based MLP-Mixer network (CAMLP-Net) is proposed for EEG-based MI decoding. Specifically, the MLP-based architecture is applied in this network to capture the temporal and spatial information. The attention mechanism is further embedded into MLP-Mixer to adaptively exploit the importance of different EEG channels. Therefore, the proposed CAMLP-Net can effectively learn more global temporal and spatial information. The experimental results on the newly built MI-2 dataset indicate that our proposed CAMLP-Net achieves superior classification performance over all the compared algorithms.
Two-Stage Self-Supervised Cycle-Consistency Network for Reconstruction of Thin-Slice MR Images
Jun 29, 2021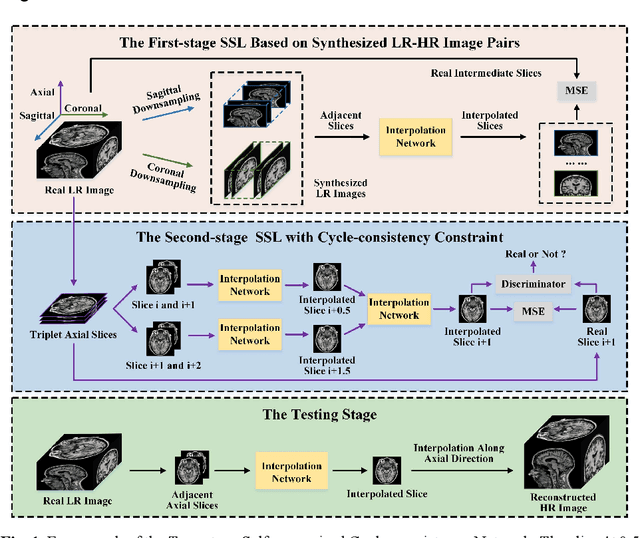
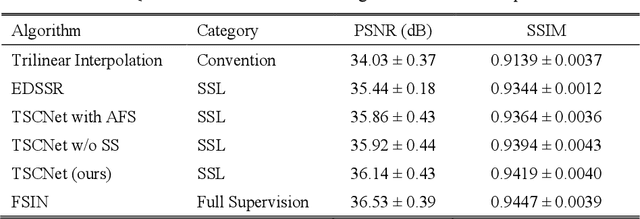
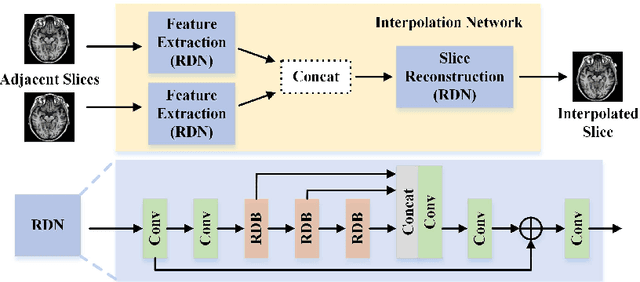

The thick-slice magnetic resonance (MR) images are often structurally blurred in coronal and sagittal views, which causes harm to diagnosis and image post-processing. Deep learning (DL) has shown great potential to re-construct the high-resolution (HR) thin-slice MR images from those low-resolution (LR) cases, which we refer to as the slice interpolation task in this work. However, since it is generally difficult to sample abundant paired LR-HR MR images, the classical fully supervised DL-based models cannot be effectively trained to get robust performance. To this end, we propose a novel Two-stage Self-supervised Cycle-consistency Network (TSCNet) for MR slice interpolation, in which a two-stage self-supervised learning (SSL) strategy is developed for unsupervised DL network training. The paired LR-HR images are synthesized along the sagittal and coronal directions of input LR images for network pretraining in the first-stage SSL, and then a cyclic in-terpolation procedure based on triplet axial slices is designed in the second-stage SSL for further refinement. More training samples with rich contexts along all directions are exploited as guidance to guarantee the improved in-terpolation performance. Moreover, a new cycle-consistency constraint is proposed to supervise this cyclic procedure, which encourages the network to reconstruct more realistic HR images. The experimental results on a real MRI dataset indicate that TSCNet achieves superior performance over the conventional and other SSL-based algorithms, and obtains competitive quali-tative and quantitative results compared with the fully supervised algorithm.
Task-driven Self-supervised Bi-channel Networks Learning for Diagnosis of Breast Cancers with Mammography
Jan 15, 2021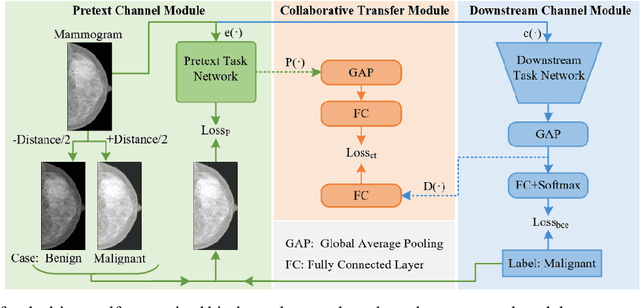

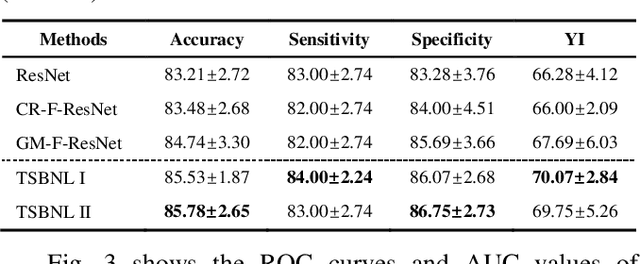

Deep learning can promote the mammography-based computer-aided diagnosis (CAD) for breast cancers, but it generally suffers from the small size sample problem. In this work, a task-driven self-supervised bi-channel networks (TSBNL) framework is proposed to improve the performance of classification network with limited mammograms. In particular, a new gray-scale image mapping (GSIM) task for image restoration is designed as the pretext task to improve discriminate feature representation with label information of mammograms. The TSBNL then innovatively integrates this image restoration network and the downstream classification network into a unified SSL framework, and transfers the knowledge from the pretext network to the classification network with improved diagnostic accuracy. The proposed algorithm is evaluated on a public INbreast mammogram dataset. The experimental results indicate that it outperforms the conventional SSL algorithms for diagnosis of breast cancers with limited samples.
Reconstruction of Quantitative Susceptibility Maps from Phase of Susceptibility Weighted Imaging with Cross-Connected Ψ-Net
Oct 14, 2020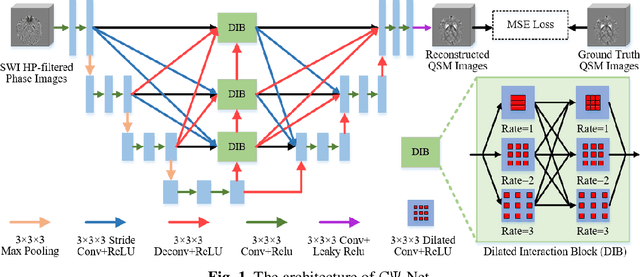

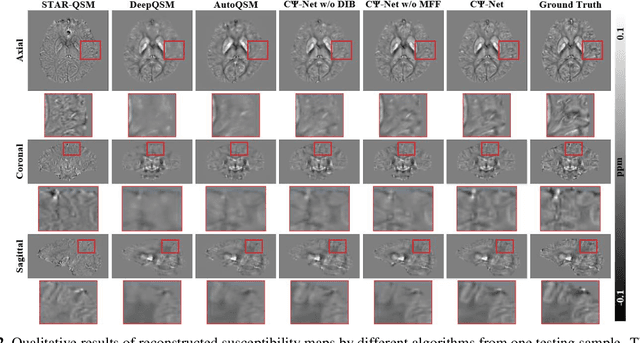
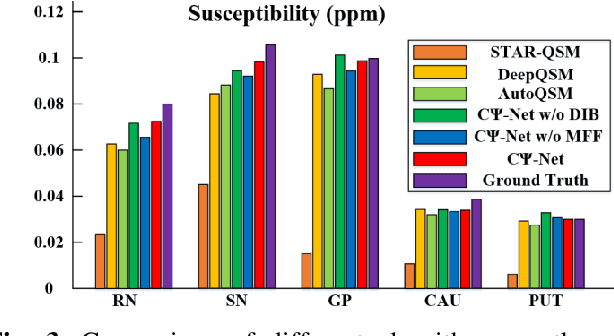
Quantitative Susceptibility Mapping (QSM) is a new phase-based technique for quantifying magnetic susceptibility. The existing QSM reconstruction methods generally require complicated pre-processing on high-quality phase data. In this work, we propose to explore a new value of the high-pass filtered phase data generated in susceptibility weighted imaging (SWI), and develop an end-to-end Cross-connected {\Psi}-Net (C{\Psi}-Net) to reconstruct QSM directly from these phase data in SWI without additional pre-processing. C{\Psi}-Net adds an intermediate branch in the classical U-Net to form a {\Psi}-like structure. The specially designed dilated interaction block is embedded in each level of this branch to enlarge the receptive fields for capturing more susceptibility information from a wider spatial range of phase images. Moreover, the crossed connections are utilized between branches to implement a multi-resolution feature fusion scheme, which helps C{\Psi}-Net capture rich contextual information for accurate reconstruction. The experimental results on a human dataset show that C{\Psi}-Net achieves superior performance in our task over other QSM reconstruction algorithms.