 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGMA3D: Local-Global Attention Learning to Estimate Occluded Motions of Scene Flow
Paper and Code
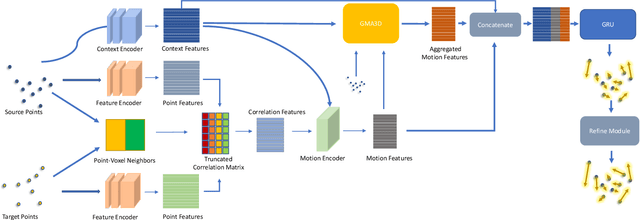
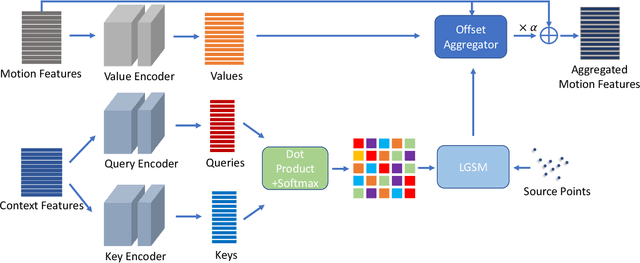

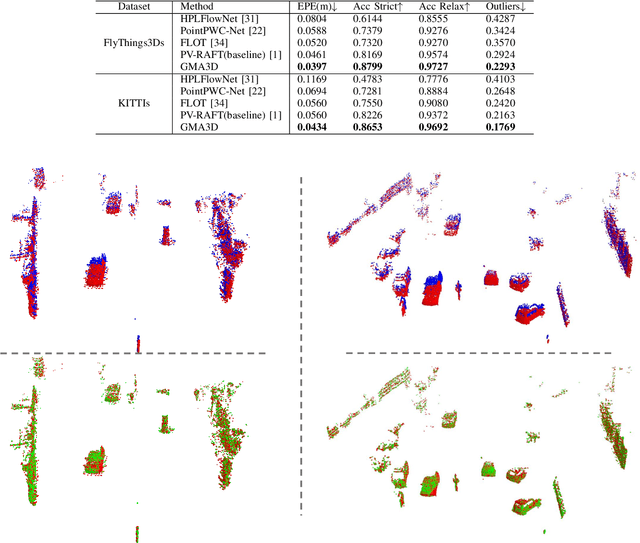
Scene flow is the collection of each point motion information in the 3D point clouds. It is a vital tool applied to many tasks, such as autonomous driving and augmented reality. However, there are always occlusion points between two consecutive point clouds, whether from the sparsity data sampling or real-world occlusion. In this paper, we focus on addressing occlusion issues in scene flow by self-similarity and local consistency of moving objects. We propose a GMA3D module based on the transformer framework, which utilizes local and global similarity to infer the motion information of occluded points from the motion information of local and global non-occluded points respectively, and then uses an offset generator to aggregate them. Our module is the first to apply the transformer-based architecture to gauge the scene flow occlusion problem on point clouds. Experiments show that our GMA3D can solve the occlusion problem in the scene flow, especially in the real scene. We evaluate the proposed method on the occluded version datasets and get state-of-the-art results on the real scene KITTI. To testify that GMA3D is still beneficial for non-occluded scene flow, we also conducted experiments on non-occluded version datasets and achieved state-of-the-art results on FlyThings3D and KITTI. The code is available at https://github.com/O-VIGIA/GMA3D.