 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Adaptive Deep Networks for Image Classification via Uncertainty-aware Decision Fusion
Aug 25, 2024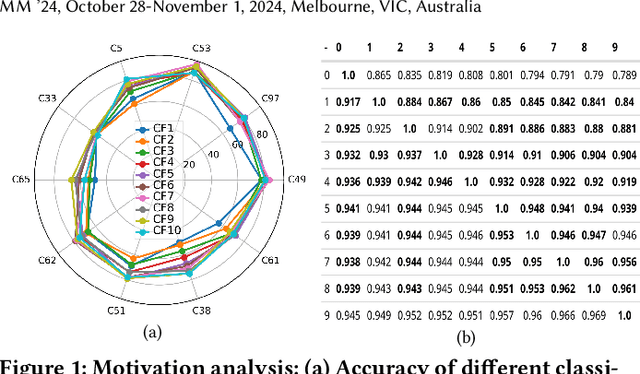



Handling varying computational resources is a critical issue in modern AI applications. Adaptive deep networks, featuring the dynamic employment of multiple classifier heads among different layers, have been proposed to address classification tasks under varying computing resources. Existing approaches typically utilize the last classifier supported by the available resources for inference, as they believe that the last classifier always performs better across all classes. However, our findings indicate that earlier classifier heads can outperform the last head for certain classes. Based on this observation, we introduce the Collaborative Decision Making (CDM) module, which fuses the multiple classifier heads to enhance the inference performance of adaptive deep networks. CDM incorporates an uncertainty-aware fusion method based on evidential deep learning (EDL), that utilizes the reliability (uncertainty values) from the first c-1 classifiers to improve the c-th classifier' accuracy. We also design a balance term that reduces fusion saturation and unfairness issues caused by EDL constraints to improve the fusion quality of CDM. Finally, a regularized training strategy that uses the last classifier to guide the learning process of early classifiers is proposed to further enhance the CDM module's effect, called the Guided Collaborative Decision Making (GCDM) framework. The experimental evaluation demonstrates the effectiveness of our approaches. Results on ImageNet datasets show CDM and GCDM obtain 0.4% to 2.8% accuracy improvement (under varying computing resources) on popular adaptive networks. The code is available at the link https://github.com/Meteor-Stars/GCDM_AdaptiveNet.
Discriminative Language Model as Semantic Consistency Scorer for Prompt-based Few-Shot Text Classification
Oct 23, 2022This paper proposes a novel prompt-based finetuning method (called DLM-SCS) for few-shot text classification by utilizing the discriminative language model ELECTRA that is pretrained to distinguish whether a token is original or generated. The underlying idea is that the prompt instantiated with the true label should have higher semantic consistency score than other prompts with false labels. Since a prompt usually consists of several components (or parts), its semantic consistency can be decomposed accordingly. The semantic consistency of each component is then computed by making use of the pretrained ELECTRA model, without introducing extra parameters. Extensive experiments have shown that our model outperforms several state-of-the-art prompt-based few-shot methods.
Max-Cosine Matching Based Neural Models for Recognizing Textual Entailment
May 25, 2017
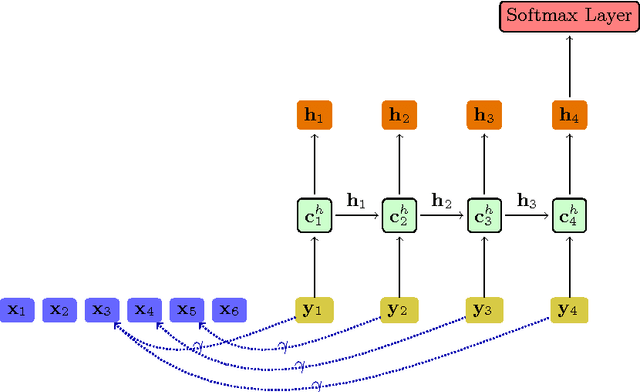
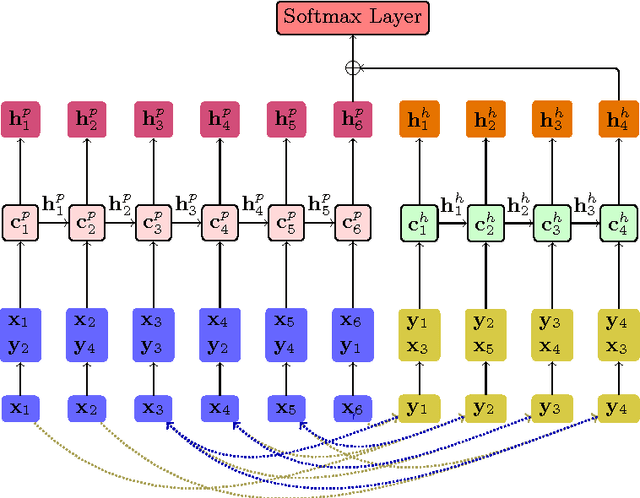

Recognizing textual entailment is a fundamental task in a variety of text mining or natural language processing applications. This paper proposes a simple neural model for RTE problem. It first matches each word in the hypothesis with its most-similar word in the premise, producing an augmented representation of the hypothesis conditioned on the premise as a sequence of word pairs. The LSTM model is then used to model this augmented sequence, and the final output from the LSTM is fed into a softmax layer to make the prediction. Besides the base model, in order to enhance its performance, we also proposed three techniques: the integration of multiple word-embedding library, bi-way integration, and ensemble based on model averaging. Experimental results on the SNLI dataset have shown that the three techniques are effective in boosting the predicative accuracy and that our method outperforms several state-of-the-state ones.