 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMax-Cosine Matching Based Neural Models for Recognizing Textual Entailment
Paper and Code
May 25, 2017
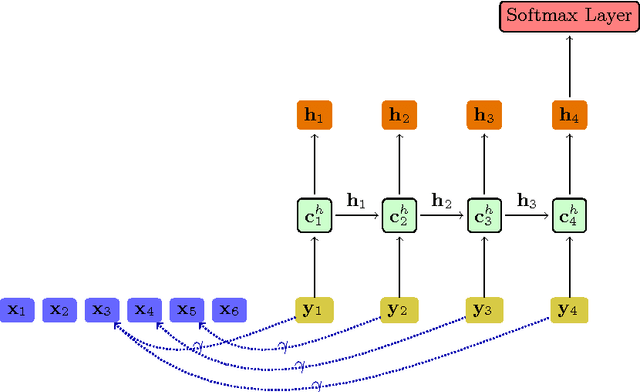
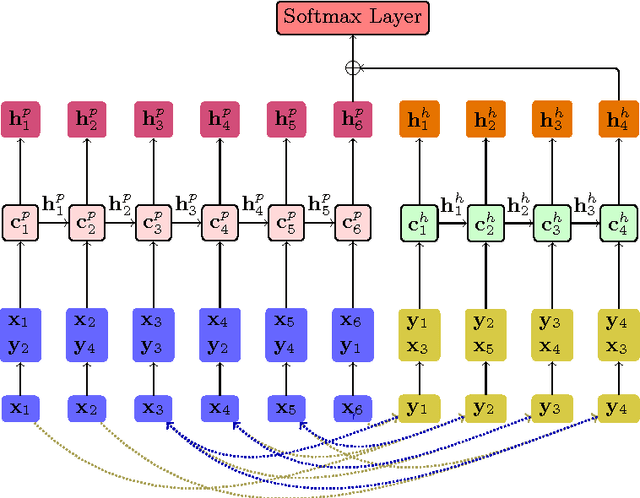

Recognizing textual entailment is a fundamental task in a variety of text mining or natural language processing applications. This paper proposes a simple neural model for RTE problem. It first matches each word in the hypothesis with its most-similar word in the premise, producing an augmented representation of the hypothesis conditioned on the premise as a sequence of word pairs. The LSTM model is then used to model this augmented sequence, and the final output from the LSTM is fed into a softmax layer to make the prediction. Besides the base model, in order to enhance its performance, we also proposed three techniques: the integration of multiple word-embedding library, bi-way integration, and ensemble based on model averaging. Experimental results on the SNLI dataset have shown that the three techniques are effective in boosting the predicative accuracy and that our method outperforms several state-of-the-state ones.