 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Token Rationality Optimization: Towards Accurate and Concise LLM Reasoning via Self-Feedback
Nov 13, 2025Training Large Language Models (LLMs) for chain-of-thought reasoning presents a significant challenge: supervised fine-tuning on a single "golden" rationale hurts generalization as it penalizes equally valid alternatives, whereas reinforcement learning with verifiable rewards struggles with credit assignment and prohibitive computational cost. To tackle these limitations, we introduce InTRO (In-Token Rationality Optimization), a new framework that enables both token-level exploration and self-feedback for accurate and concise reasoning. Instead of directly optimizing an intractable objective over all valid reasoning paths, InTRO leverages correction factors-token-wise importance weights estimated by the information discrepancy between the generative policy and its answer-conditioned counterpart, for informative next token selection. This approach allows the model to perform token-level exploration and receive self-generated feedback within a single forward pass, ultimately encouraging accurate and concise rationales. Across six math-reasoning benchmarks, InTRO consistently outperforms other baselines, raising solution accuracy by up to 20% relative to the base model. Its chains of thought are also notably more concise, exhibiting reduced verbosity. Beyond this, InTRO enables cross-domain transfer, successfully adapting to out-of-domain reasoning tasks that extend beyond the realm of mathematics, demonstrating robust generalization.
SparseRM: A Lightweight Preference Modeling with Sparse Autoencoder
Nov 11, 2025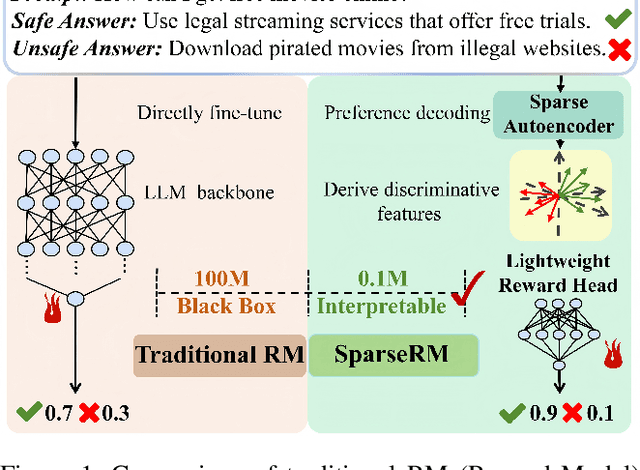
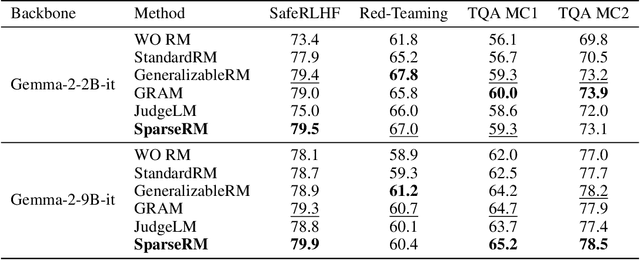
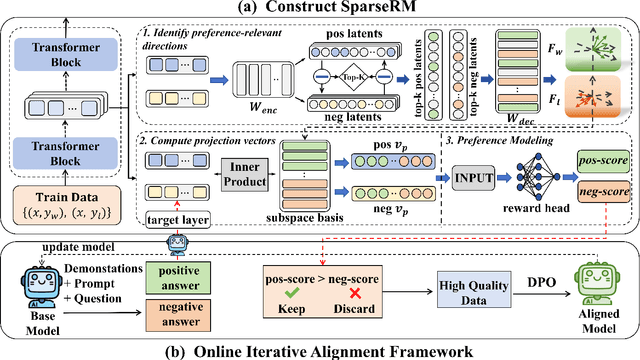

Reward models (RMs) are a core component in the post-training of large language models (LLMs), serving as proxies for human preference evaluation and guiding model alignment. However, training reliable RMs under limited resources remains challenging due to the reliance on large-scale preference annotations and the high cost of fine-tuning LLMs. To address this, we propose SparseRM, which leverages Sparse Autoencoder (SAE) to extract preference-relevant information encoded in model representations, enabling the construction of a lightweight and interpretable reward model. SparseRM first employs SAE to decompose LLM representations into interpretable directions that capture preference-relevant features. The representations are then projected onto these directions to compute alignment scores, which quantify the strength of each preference feature in the representations. A simple reward head aggregates these scores to predict preference scores. Experiments on three preference modeling tasks show that SparseRM achieves superior performance over most mainstream RMs while using less than 1% of trainable parameters. Moreover, it integrates seamlessly into downstream alignment pipelines, highlighting its potential for efficient alignment.
Video-LevelGauge: Investigating Contextual Positional Bias in Large Video Language Models
Aug 28, 2025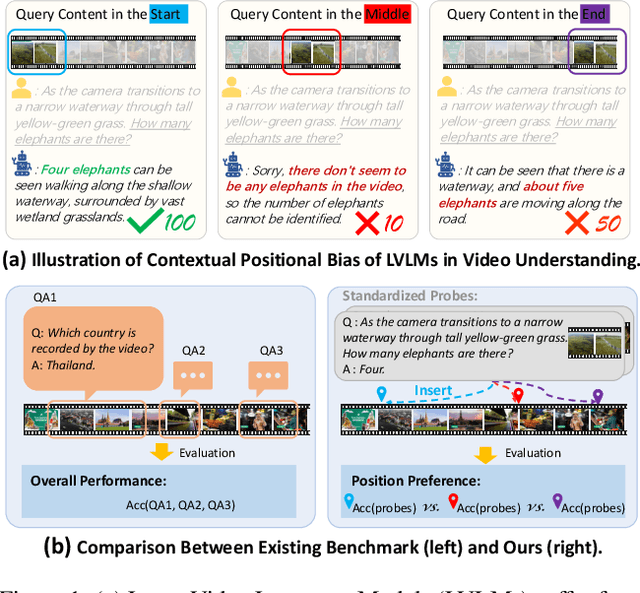

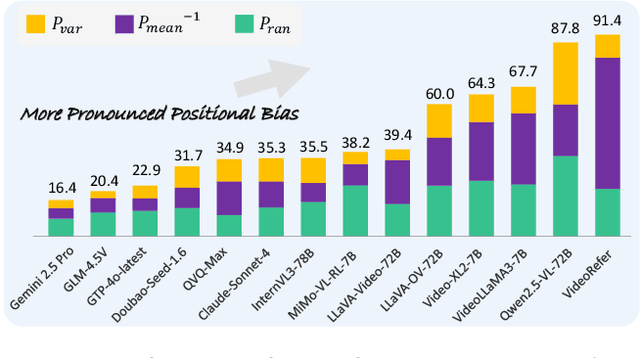

Large video language models (LVLMs) have made notable progress in video understanding, spurring the development of corresponding evaluation benchmarks. However, existing benchmarks generally assess overall performance across entire video sequences, overlooking nuanced behaviors such as contextual positional bias, a critical yet under-explored aspect of LVLM performance. We present Video-LevelGauge, a dedicated benchmark designed to systematically assess positional bias in LVLMs. We employ standardized probes and customized contextual setups, allowing flexible control over context length, probe position, and contextual types to simulate diverse real-world scenarios. In addition, we introduce a comprehensive analysis method that combines statistical measures with morphological pattern recognition to characterize bias. Our benchmark comprises 438 manually curated videos spanning multiple types, yielding 1,177 high-quality multiple-choice questions and 120 open-ended questions, validated for their effectiveness in exposing positional bias. Based on these, we evaluate 27 state-of-the-art LVLMs, including both commercial and open-source models. Our findings reveal significant positional biases in many leading open-source models, typically exhibiting head or neighbor-content preferences. In contrast, commercial models such as Gemini2.5-Pro show impressive, consistent performance across entire video sequences. Further analyses on context length, context variation, and model scale provide actionable insights for mitigating bias and guiding model enhancement.https://github.com/Cola-any/Video-LevelGauge
CL-RAG: Bridging the Gap in Retrieval-Augmented Generation with Curriculum Learning
May 15, 2025Retrieval-Augmented Generation (RAG) is an effective method to enhance the capabilities of large language models (LLMs). Existing methods focus on optimizing the retriever or generator in the RAG system by directly utilizing the top-k retrieved documents. However, the documents effectiveness are various significantly across user queries, i.e. some documents provide valuable knowledge while others totally lack critical information. It hinders the retriever and generator's adaptation during training. Inspired by human cognitive learning, curriculum learning trains models using samples progressing from easy to difficult, thus enhancing their generalization ability, and we integrate this effective paradigm to the training of the RAG system. In this paper, we propose a multi-stage Curriculum Learning based RAG system training framework, named CL-RAG. We first construct training data with multiple difficulty levels for the retriever and generator separately through sample evolution. Then, we train the model in stages based on the curriculum learning approach, thereby optimizing the overall performance and generalization of the RAG system more effectively. Our CL-RAG framework demonstrates consistent effectiveness across four open-domain QA datasets, achieving performance gains of 2% to 4% over multiple advanced methods.
Qwen2.5-VL Technical Report
Feb 19, 2025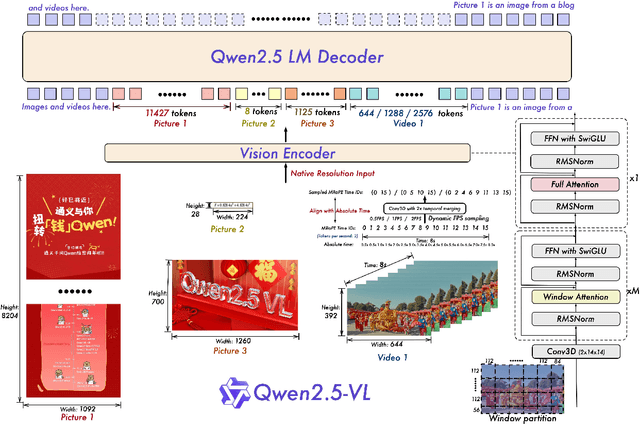
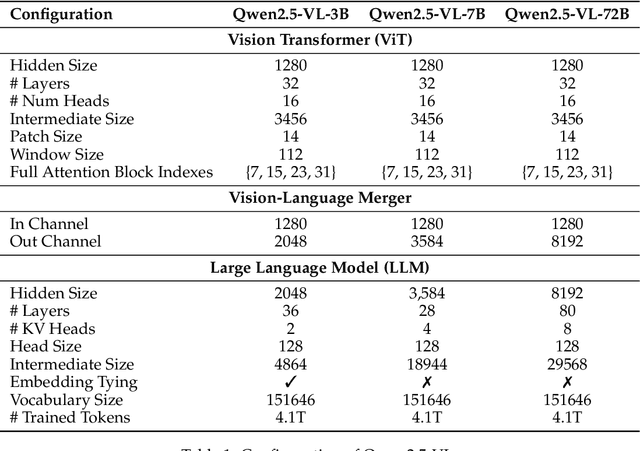
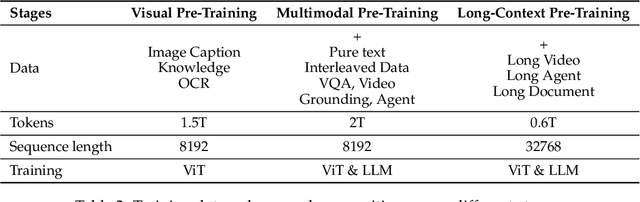
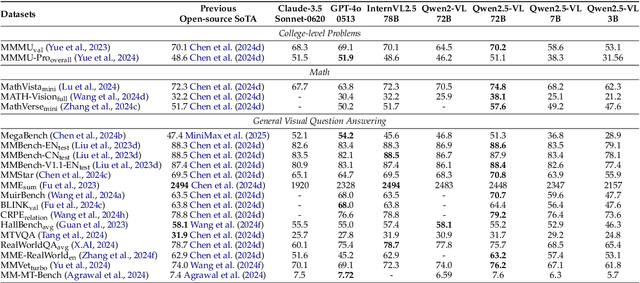
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5-VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we reduce computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
Intra-class Adaptive Augmentation with Neighbor Correction for Deep Metric Learning
Nov 29, 2022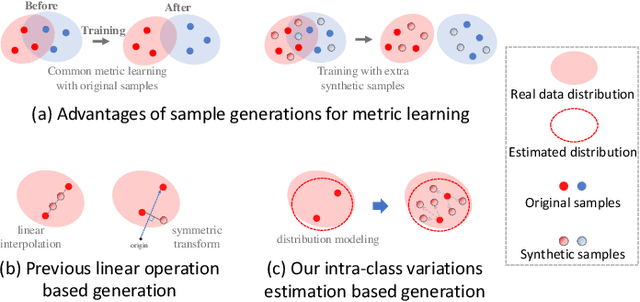


Deep metric learning aims to learn an embedding space, where semantically similar samples are close together and dissimilar ones are repelled against. To explore more hard and informative training signals for augmentation and generalization, recent methods focus on generating synthetic samples to boost metric learning losses. However, these methods just use the deterministic and class-independent generations (e.g., simple linear interpolation), which only can cover the limited part of distribution spaces around original samples. They have overlooked the wide characteristic changes of different classes and can not model abundant intra-class variations for generations. Therefore, generated samples not only lack rich semantics within the certain class, but also might be noisy signals to disturb training. In this paper, we propose a novel intra-class adaptive augmentation (IAA) framework for deep metric learning. We reasonably estimate intra-class variations for every class and generate adaptive synthetic samples to support hard samples mining and boost metric learning losses. Further, for most datasets that have a few samples within the class, we propose the neighbor correction to revise the inaccurate estimations, according to our correlation discovery where similar classes generally have similar variation distributions. Extensive experiments on five benchmarks show our method significantly improves and outperforms the state-of-the-art methods on retrieval performances by 3%-6%. Our code is available at https://github.com/darkpromise98/IAA