 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Applications of Artificial Intelligence in Fighting Against COVID-19
Jul 04, 2020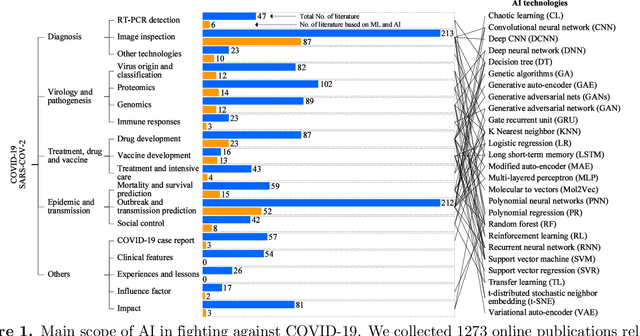
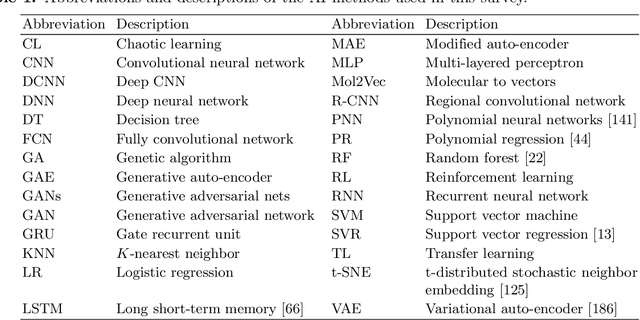
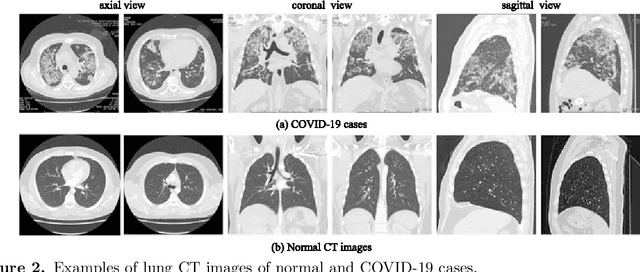
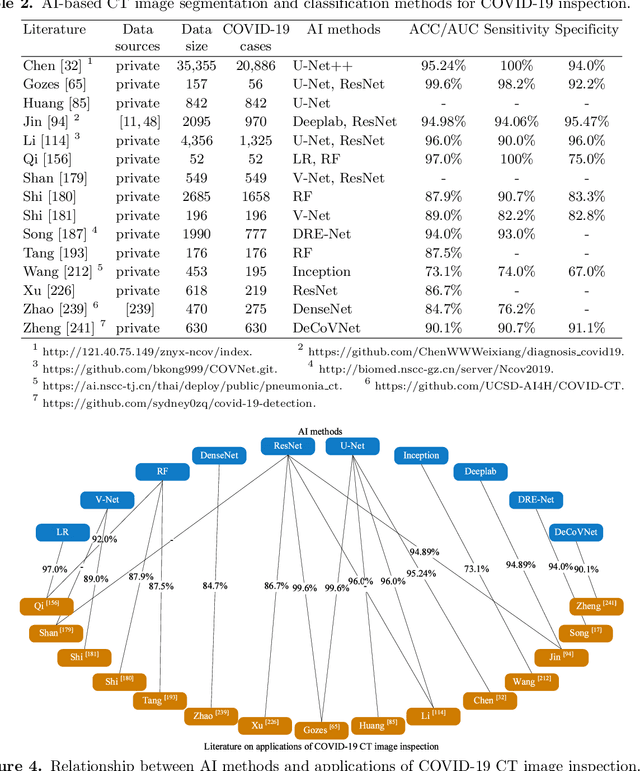
The COVID-19 pandemic caused by the SARS-CoV-2 virus has spread rapidly worldwide, leading to a global outbreak. Most governments, enterprises, and scientific research institutions are participating in the COVID-19 struggle to curb the spread of the pandemic. As a powerful tool against COVID-19, artificial intelligence (AI) technologies are widely used in combating this pandemic. In this survey, we investigate the main scope and contributions of AI in combating COVID-19 from the aspects of disease detection and diagnosis, virology and pathogenesis, drug and vaccine development, and epidemic and transmission prediction. In addition, we summarize the available data and resources that can be used for AI-based COVID-19 research. Finally, the main challenges and potential directions of AI in fighting against COVID-19 are discussed. Currently, AI mainly focuses on medical image inspection, genomics, drug development, and transmission prediction, and thus AI still has great potential in this field. This survey presents medical and AI researchers with a comprehensive view of the existing and potential applications of AI technology in combating COVID-19 with the goal of inspiring researches to continue to maximize the advantages of AI and big data to fight COVID-19.
Unsupervised Learning in Genome Informatics
Aug 03, 2015


With different genomes available, unsupervised learning algorithms are essential in learning genome-wide biological insights. Especially, the functional characterization of different genomes is essential for us to understand lives. In this book chapter, we review the state-of-the-art unsupervised learning algorithms for genome informatics from DNA to MicroRNA. DNA (DeoxyriboNucleic Acid) is the basic component of genomes. A significant fraction of DNA regions (transcription factor binding sites) are bound by proteins (transcription factors) to regulate gene expression at different development stages in different tissues. To fully understand genetics, it is necessary of us to apply unsupervised learning algorithms to learn and infer those DNA regions. Here we review several unsupervised learning methods for deciphering the genome-wide patterns of those DNA regions. MicroRNA (miRNA), a class of small endogenous non-coding RNA (RiboNucleic acid) species, regulate gene expression post-transcriptionally by forming imperfect base-pair with the target sites primarily at the 3$'$ untranslated regions of the messenger RNAs. Since the 1993 discovery of the first miRNA \emph{let-7} in worms, a vast amount of studies have been dedicated to functionally characterizing the functional impacts of miRNA in a network context to understand complex diseases such as cancer. Here we review several representative unsupervised learning frameworks on inferring miRNA regulatory network by exploiting the static sequence-based information pertinent to the prior knowledge of miRNA targeting and the dynamic information of miRNA activities implicated by the recently available large data compendia, which interrogate genome-wide expression profiles of miRNAs and/or mRNAs across various cell conditions.
Deep Autoencoders for Dimensionality Reduction of High-Content Screening Data
Jan 07, 2015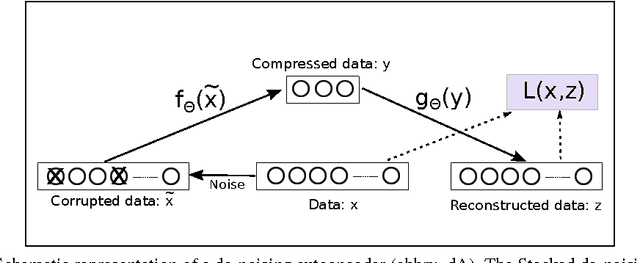
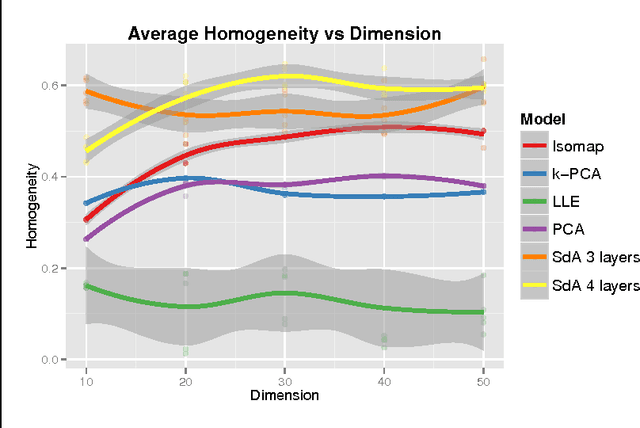

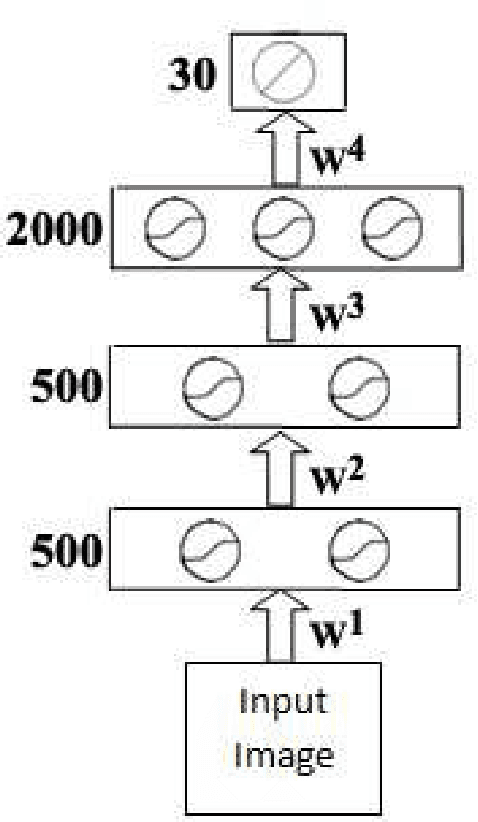
High-content screening uses large collections of unlabeled cell image data to reason about genetics or cell biology. Two important tasks are to identify those cells which bear interesting phenotypes, and to identify sub-populations enriched for these phenotypes. This exploratory data analysis usually involves dimensionality reduction followed by clustering, in the hope that clusters represent a phenotype. We propose the use of stacked de-noising auto-encoders to perform dimensionality reduction for high-content screening. We demonstrate the superior performance of our approach over PCA, Local Linear Embedding, Kernel PCA and Isomap.
Large-Margin kNN Classification Using a Deep Encoder Network
Jun 09, 2009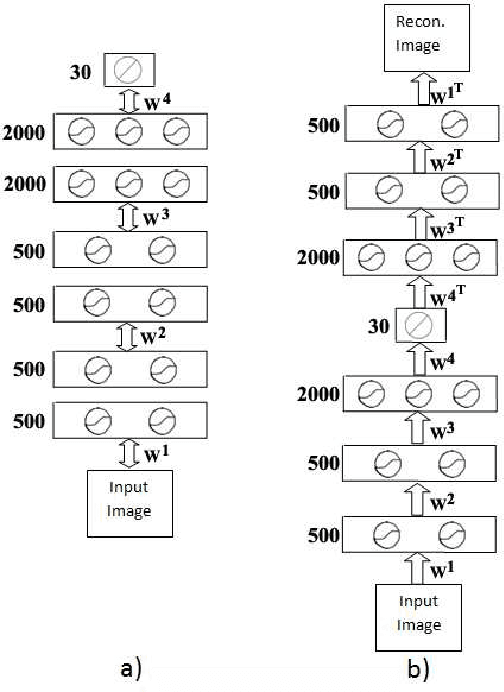
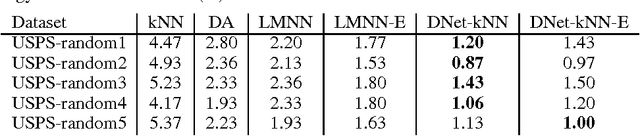
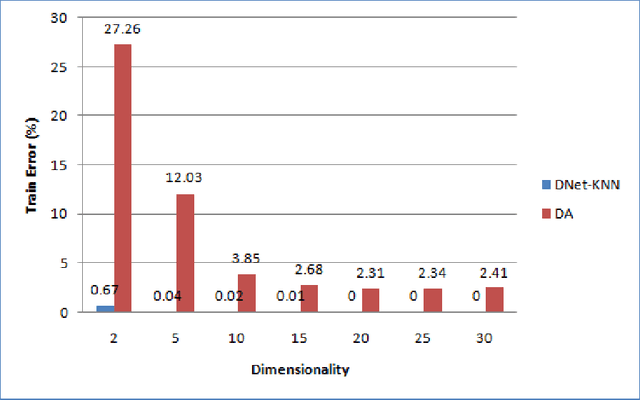
KNN is one of the most popular classification methods, but it often fails to work well with inappropriate choice of distance metric or due to the presence of numerous class-irrelevant features. Linear feature transformation methods have been widely applied to extract class-relevant information to improve kNN classification, which is very limited in many applications. Kernels have been used to learn powerful non-linear feature transformations, but these methods fail to scale to large datasets. In this paper, we present a scalable non-linear feature mapping method based on a deep neural network pretrained with restricted boltzmann machines for improving kNN classification in a large-margin framework, which we call DNet-kNN. DNet-kNN can be used for both classification and for supervised dimensionality reduction. The experimental results on two benchmark handwritten digit datasets show that DNet-kNN has much better performance than large-margin kNN using a linear mapping and kNN based on a deep autoencoder pretrained with retricted boltzmann machines.