 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Hierarchical Structure of Leaf Venations in Plant Science via Label-Efficient Segmentation: Dataset and Method
May 16, 2024Hierarchical leaf vein segmentation is a crucial but under-explored task in agricultural sciences, where analysis of the hierarchical structure of plant leaf venation can contribute to plant breeding. While current segmentation techniques rely on data-driven models, there is no publicly available dataset specifically designed for hierarchical leaf vein segmentation. To address this gap, we introduce the HierArchical Leaf Vein Segmentation (HALVS) dataset, the first public hierarchical leaf vein segmentation dataset. HALVS comprises 5,057 real-scanned high-resolution leaf images collected from three plant species: soybean, sweet cherry, and London planetree. It also includes human-annotated ground truth for three orders of leaf veins, with a total labeling effort of 83.8 person-days. Based on HALVS, we further develop a label-efficient learning paradigm that leverages partial label information, i.e. missing annotations for tertiary veins. Empirical studies are performed on HALVS, revealing new observations, challenges, and research directions on leaf vein segmentation.
Tracking Objects as Pixel-wise Distributions
Jul 15, 2022
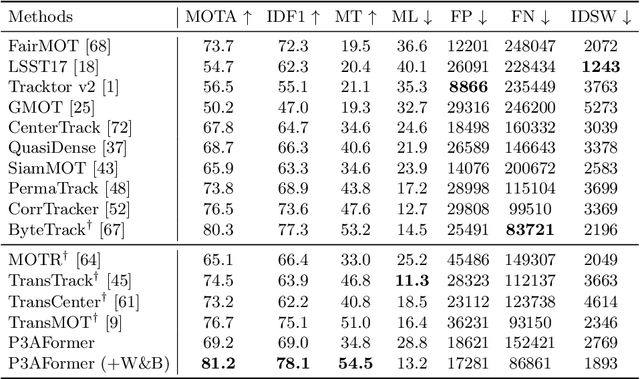
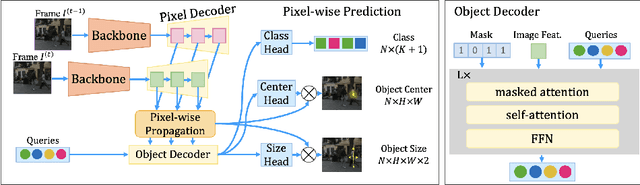
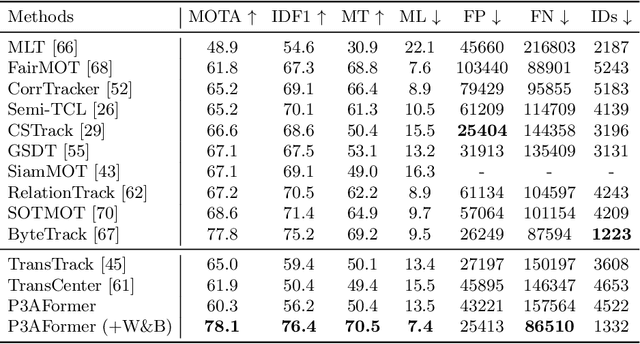
Multi-object tracking (MOT) requires detecting and associating objects through frames. Unlike tracking via detected bounding boxes or tracking objects as points, we propose tracking objects as pixel-wise distributions. We instantiate this idea on a transformer-based architecture, P3AFormer, with pixel-wise propagation, prediction, and association. P3AFormer propagates pixel-wise features guided by flow information to pass messages between frames. Furthermore, P3AFormer adopts a meta-architecture to produce multi-scale object feature maps. During inference, a pixel-wise association procedure is proposed to recover object connections through frames based on the pixel-wise prediction. P3AFormer yields 81.2\% in terms of MOTA on the MOT17 benchmark -- the first among all transformer networks to reach 80\% MOTA in literature. P3AFormer also outperforms state-of-the-arts on the MOT20 and KITTI benchmarks.