 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Objects as Pixel-wise Distributions
Paper and Code

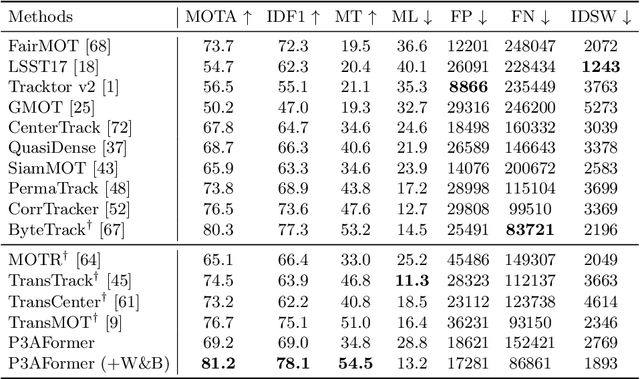
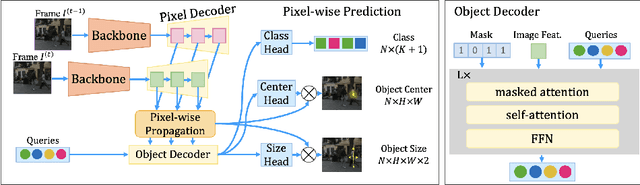
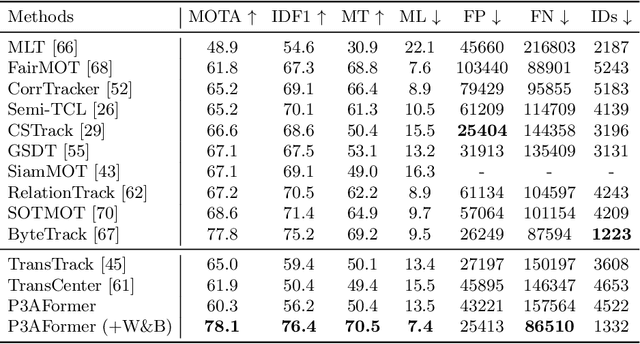
Multi-object tracking (MOT) requires detecting and associating objects through frames. Unlike tracking via detected bounding boxes or tracking objects as points, we propose tracking objects as pixel-wise distributions. We instantiate this idea on a transformer-based architecture, P3AFormer, with pixel-wise propagation, prediction, and association. P3AFormer propagates pixel-wise features guided by flow information to pass messages between frames. Furthermore, P3AFormer adopts a meta-architecture to produce multi-scale object feature maps. During inference, a pixel-wise association procedure is proposed to recover object connections through frames based on the pixel-wise prediction. P3AFormer yields 81.2\% in terms of MOTA on the MOT17 benchmark -- the first among all transformer networks to reach 80\% MOTA in literature. P3AFormer also outperforms state-of-the-arts on the MOT20 and KITTI benchmarks.