 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic-Net Multiple Kernel Learning: Combining Multiple Data Sources for Prediction
Dec 12, 2025Multiple Kernel Learning (MKL) models combine several kernels in supervised and unsupervised settings to integrate multiple data representations or sources, each represented by a different kernel. MKL seeks an optimal linear combination of base kernels that maximizes a generalized performance measure under a regularization constraint. Various norms have been used to regularize the kernel weights, including $l1$, $l2$ and $lp$, as well as the "elastic-net" penalty, which combines $l1$- and $l2$-norm to promote both sparsity and the selection of correlated kernels. This property makes elastic-net regularized MKL (ENMKL) especially valuable when model interpretability is critical and kernels capture correlated information, such as in neuroimaging. Previous ENMKL methods have followed a two-stage procedure: fix kernel weights, train a support vector machine (SVM) with the weighted kernel, and then update the weights via gradient descent, cutting-plane methods, or surrogate functions. Here, we introduce an alternative ENMKL formulation that yields a simple analytical update for the kernel weights. We derive explicit algorithms for both SVM and kernel ridge regression (KRR) under this framework, and implement them in the open-source Pattern Recognition for Neuroimaging Toolbox (PRoNTo). We evaluate these ENMKL algorithms against $l1$-norm MKL and against SVM (or KRR) trained on the unweighted sum of kernels across three neuroimaging applications. Our results show that ENMKL matches or outperforms $l1$-norm MKL in all tasks and only underperforms standard SVM in one scenario. Crucially, ENMKL produces sparser, more interpretable models by selectively weighting correlated kernels.
PinView: Implicit Feedback in Content-Based Image Retrieval
Oct 02, 2014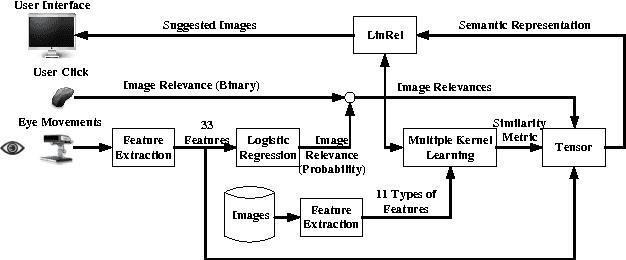
This paper describes PinView, a content-based image retrieval system that exploits implicit relevance feedback collected during a search session. PinView contains several novel methods to infer the intent of the user. From relevance feedback, such as eye movements or pointer clicks, and visual features of images, PinView learns a similarity metric between images which depends on the current interests of the user. It then retrieves images with a specialized online learning algorithm that balances the tradeoff between exploring new images and exploiting the already inferred interests of the user. We have integrated PinView to the content-based image retrieval system PicSOM, which enables applying PinView to real-world image databases. With the new algorithms PinView outperforms the original PicSOM, and in online experiments with real users the combination of implicit and explicit feedback gives the best results.
A Note on Improved Loss Bounds for Multiple Kernel Learning
May 12, 2014In this paper, we correct an upper bound, presented in~\cite{hs-11}, on the generalisation error of classifiers learned through multiple kernel learning. The bound in~\cite{hs-11} uses Rademacher complexity and has an\emph{additive} dependence on the logarithm of the number of kernels and the margin achieved by the classifier. However, there are some errors in parts of the proof which are corrected in this paper. Unfortunately, the final result turns out to be a risk bound which has a \emph{multiplicative} dependence on the logarithm of the number of kernels and the margin achieved by the classifier.
A Nonconformity Approach to Model Selection for SVMs
Sep 12, 2009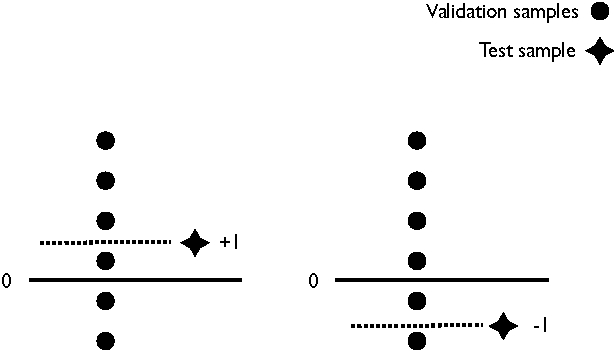
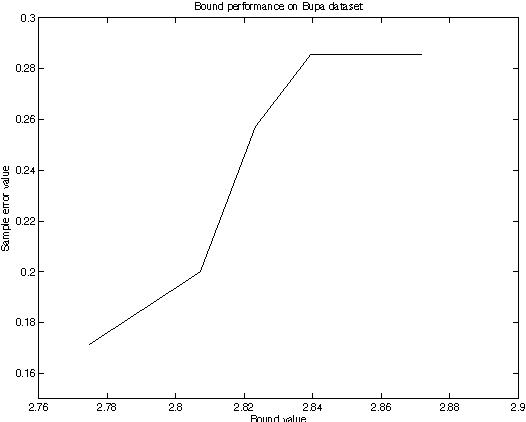
We investigate the issue of model selection and the use of the nonconformity (strangeness) measure in batch learning. Using the nonconformity measure we propose a new training algorithm that helps avoid the need for Cross-Validation or Leave-One-Out model selection strategies. We provide a new generalisation error bound using the notion of nonconformity to upper bound the loss of each test example and show that our proposed approach is comparable to standard model selection methods, but with theoretical guarantees of success and faster convergence. We demonstrate our novel model selection technique using the Support Vector Machine.