 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3Retrieve: Benchmarking Multimodal Retrieval for Medicine
Oct 08, 2025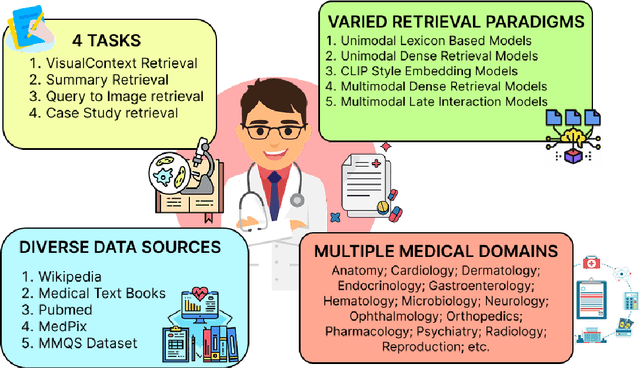
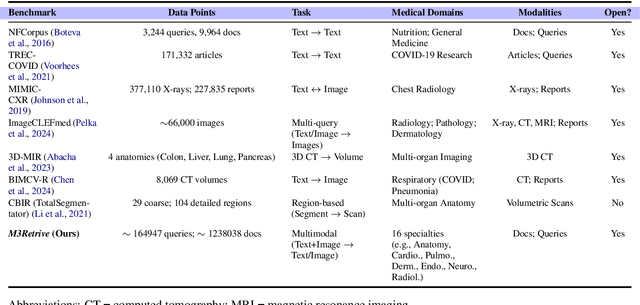

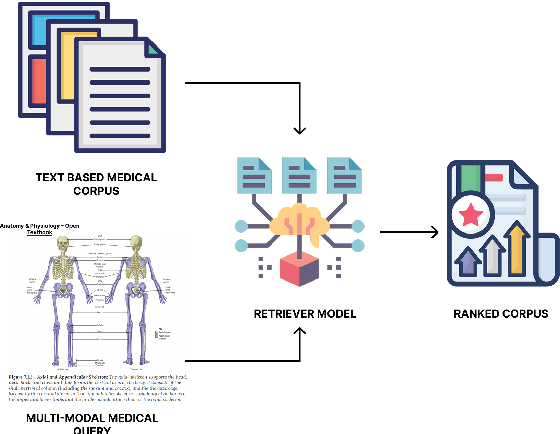
With the increasing use of RetrievalAugmented Generation (RAG), strong retrieval models have become more important than ever. In healthcare, multimodal retrieval models that combine information from both text and images offer major advantages for many downstream tasks such as question answering, cross-modal retrieval, and multimodal summarization, since medical data often includes both formats. However, there is currently no standard benchmark to evaluate how well these models perform in medical settings. To address this gap, we introduce M3Retrieve, a Multimodal Medical Retrieval Benchmark. M3Retrieve, spans 5 domains,16 medical fields, and 4 distinct tasks, with over 1.2 Million text documents and 164K multimodal queries, all collected under approved licenses. We evaluate leading multimodal retrieval models on this benchmark to explore the challenges specific to different medical specialities and to understand their impact on retrieval performance. By releasing M3Retrieve, we aim to enable systematic evaluation, foster model innovation, and accelerate research toward building more capable and reliable multimodal retrieval systems for medical applications. The dataset and the baselines code are available in this github page https://github.com/AkashGhosh/M3Retrieve.
SELM: Siamese Extreme Learning Machine with Application to Face Biometrics
Aug 06, 2021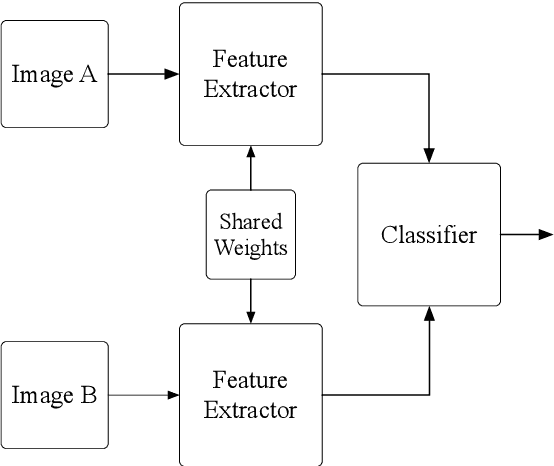
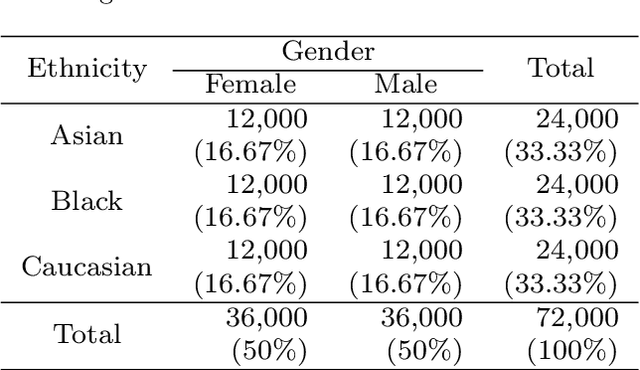
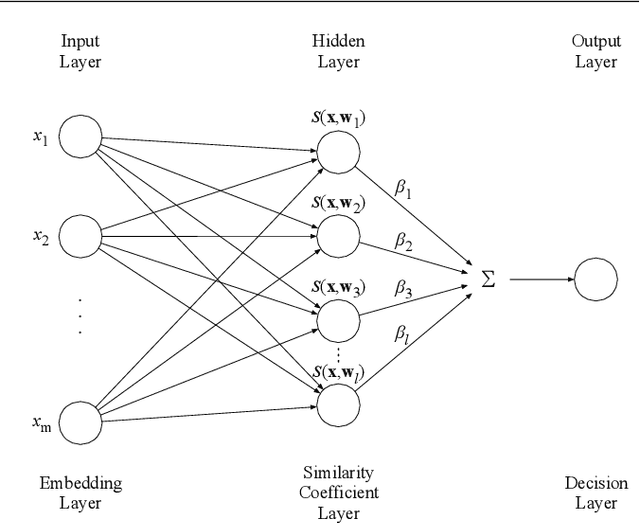

Extreme Learning Machine is a powerful classification method very competitive existing classification methods. It is extremely fast at training. Nevertheless, it cannot perform face verification tasks properly because face verification tasks require comparison of facial images of two individuals at the same time and decide whether the two faces identify the same person. The structure of Extreme Leaning Machine was not designed to feed two input data streams simultaneously, thus, in 2-input scenarios Extreme Learning Machine methods are normally applied using concatenated inputs. However, this setup consumes two times more computational resources and it is not optimized for recognition tasks where learning a separable distance metric is critical. For these reasons, we propose and develop a Siamese Extreme Learning Machine (SELM). SELM was designed to be fed with two data streams in parallel simultaneously. It utilizes a dual-stream Siamese condition in the extra Siamese layer to transform the data before passing it along to the hidden layer. Moreover, we propose a Gender-Ethnicity-Dependent triplet feature exclusively trained on a variety of specific demographic groups. This feature enables learning and extracting of useful facial features of each group. Experiments were conducted to evaluate and compare the performances of SELM, Extreme Learning Machine, and DCNN. The experimental results showed that the proposed feature was able to perform correct classification at 97.87% accuracy and 99.45% AUC. They also showed that using SELM in conjunction with the proposed feature provided 98.31% accuracy and 99.72% AUC. They outperformed the well-known DCNN and Extreme Leaning Machine methods by a wide margin.
Convolutional Neural Networks based Focal Loss for Class Imbalance Problem: A Case Study of Canine Red Blood Cells Morphology Classification
Jan 10, 2020
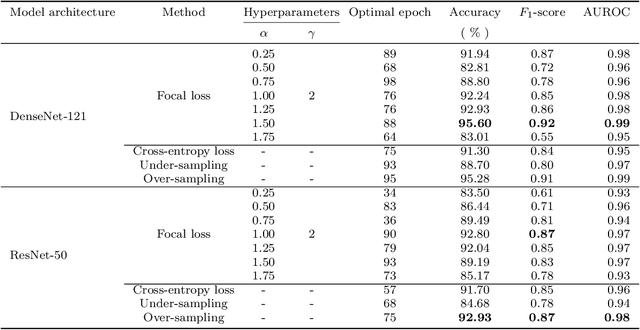
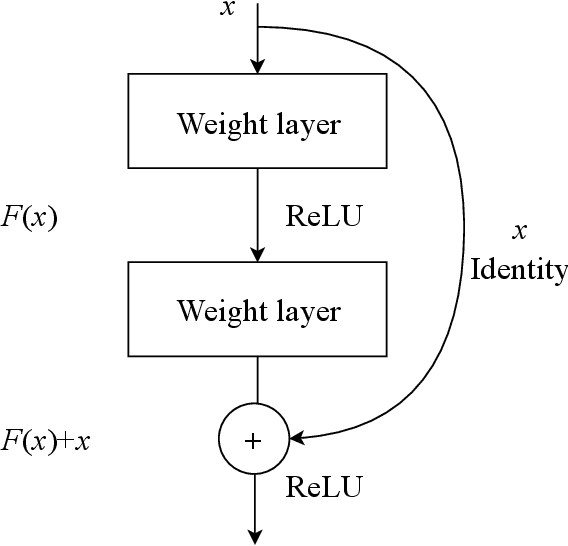
Morphologies of red blood cells are normally interpreted by a pathologist. It is time-consuming and laborious. Furthermore, a misclassified red blood cell morphology will lead to false disease diagnosis and improper treatment. Thus, a decent pathologist must truly be an expert in classifying red blood cell morphology. In the past decade, many approaches have been proposed for classifying human red blood cell morphology. However, those approaches have not addressed the class imbalance problem in classification. A class imbalance problem---a problem where the numbers of samples in classes are very different---is one of the problems that can lead to a biased model towards the majority class. Due to the rarity of every type of abnormal blood cell morphology, the data from the collection process are usually imbalanced. In this study, we aimed to solve this problem specifically for classification of dog red blood cell morphology by using a Convolutional Neural Network (CNN)---a well-known deep learning technique---in conjunction with a focal loss function, adept at handling class imbalance problem. The proposed technique was conducted on a well-designed framework: two different CNNs were used to verify the effectiveness of the focal loss function and the optimal hyper-parameters were determined by 5-fold cross-validation. The experimental results show that both CNNs models augmented with the focal loss function achieved higher $F_{1}$-scores, compared to the models augmented with a conventional cross-entropy loss function that does not address class imbalance problem. In other words, the focal loss function truly enabled the CNNs models to be less biased towards the majority class than the cross-entropy did in the classification task of imbalanced dog red blood cell data.
PinView: Implicit Feedback in Content-Based Image Retrieval
Oct 02, 2014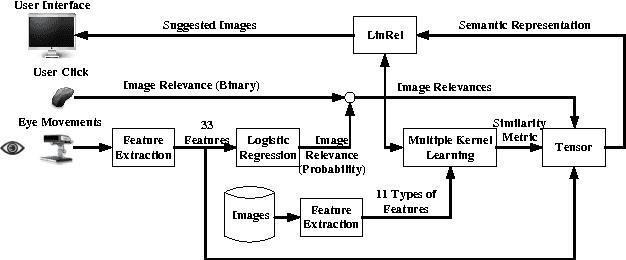
This paper describes PinView, a content-based image retrieval system that exploits implicit relevance feedback collected during a search session. PinView contains several novel methods to infer the intent of the user. From relevance feedback, such as eye movements or pointer clicks, and visual features of images, PinView learns a similarity metric between images which depends on the current interests of the user. It then retrieves images with a specialized online learning algorithm that balances the tradeoff between exploring new images and exploiting the already inferred interests of the user. We have integrated PinView to the content-based image retrieval system PicSOM, which enables applying PinView to real-world image databases. With the new algorithms PinView outperforms the original PicSOM, and in online experiments with real users the combination of implicit and explicit feedback gives the best results.