 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePair-Wise Cluster Analysis
Sep 19, 2010

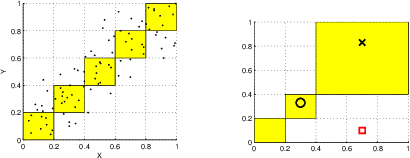
This paper studies the problem of learning clusters which are consistently present in different (continuously valued) representations of observed data. Our setup differs slightly from the standard approach of (co-) clustering as we use the fact that some form of `labeling' becomes available in this setup: a cluster is only interesting if it has a counterpart in the alternative representation. The contribution of this paper is twofold: (i) the problem setting is explored and an analysis in terms of the PAC-Bayesian theorem is presented, (ii) a practical kernel-based algorithm is derived exploiting the inherent relation to Canonical Correlation Analysis (CCA), as well as its extension to multiple views. A content based information retrieval (CBIR) case study is presented on the multi-lingual aligned Europal document dataset which supports the above findings.
A Nonconformity Approach to Model Selection for SVMs
Sep 12, 2009
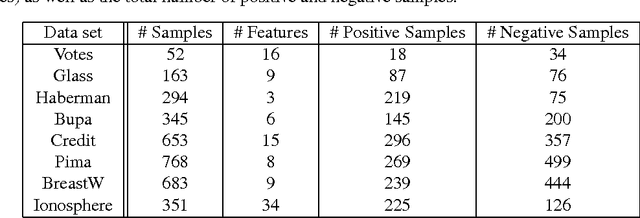
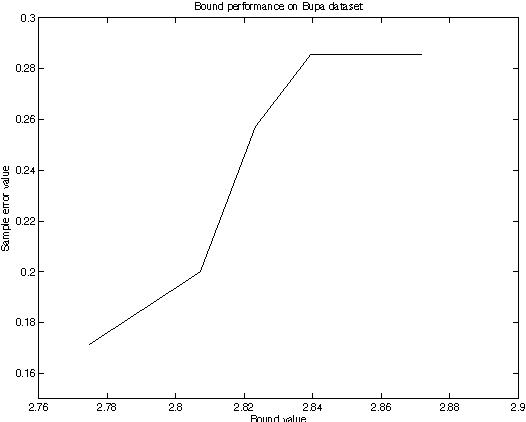
We investigate the issue of model selection and the use of the nonconformity (strangeness) measure in batch learning. Using the nonconformity measure we propose a new training algorithm that helps avoid the need for Cross-Validation or Leave-One-Out model selection strategies. We provide a new generalisation error bound using the notion of nonconformity to upper bound the loss of each test example and show that our proposed approach is comparable to standard model selection methods, but with theoretical guarantees of success and faster convergence. We demonstrate our novel model selection technique using the Support Vector Machine.
Sparse Canonical Correlation Analysis
Aug 19, 2009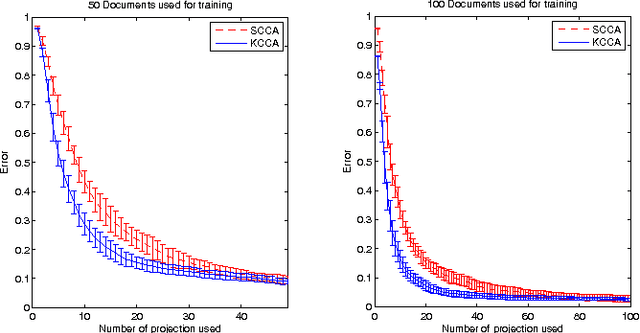
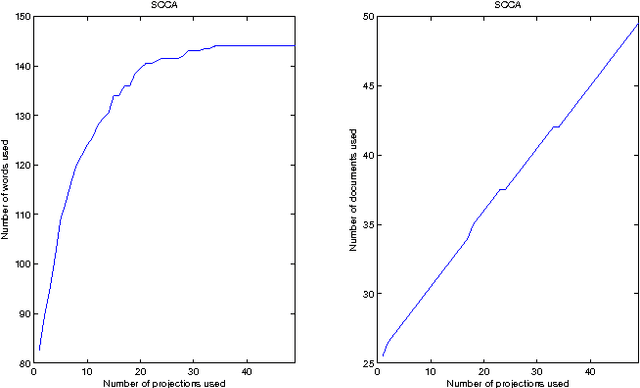
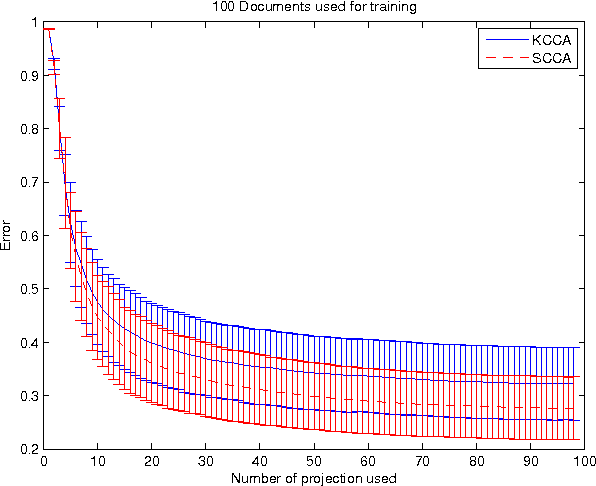
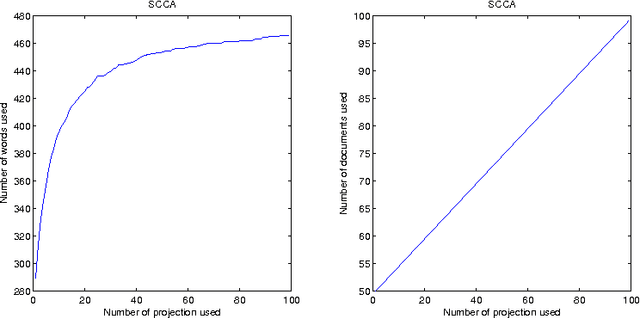
We present a novel method for solving Canonical Correlation Analysis (CCA) in a sparse convex framework using a least squares approach. The presented method focuses on the scenario when one is interested in (or limited to) a primal representation for the first view while having a dual representation for the second view. Sparse CCA (SCCA) minimises the number of features used in both the primal and dual projections while maximising the correlation between the two views. The method is demonstrated on two paired corpuses of English-French and English-Spanish for mate-retrieval. We are able to observe, in the mate-retreival, that when the number of the original features is large SCCA outperforms Kernel CCA (KCCA), learning the common semantic space from a sparse set of features.