 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVOC: Enhancing Hour-Level Audio-Video Understanding in Omni-Modal LLMs via Retrieval-Inspired Token Compression
Jun 23, 2026Multimodal Large Language Models have achieved remarkable progress in short-form audio-video understanding, yet long-form audio-video comprehension remains challenged by limited context windows and severe information redundancy. To address these bottlenecks, we propose AVOC, a framework for long-form audio-video understanding in Omni-modal Large Language Models. AVOC introduces a learnable token compression module between the modality encoders and the LLM backbone. We reframe multimodal token compression as a top-$K$ retrieval problem: given a fixed context budget, the module must retrieve a compact subset of tokens that best supports answering the user query. We draw inspiration from three classical Information Retrieval criteria for selecting informative units from a large candidate pool: relevance, importance, and diversity. AVOC instantiates each criterion as a tailored mechanism for audio-video understanding, and integrates them into a unified retrieval-style compression pipeline. Experiments show that AVOC achieves state-of-the-art performance on long-form audio-video benchmarks, surpassing the second-best model by 4.9 and 5.5 points in average accuracy on OmniVideoBench and LVOmniBench, respectively. Moreover, AVOC maintains robust performance on Audio-Video Needle-in-a-Haystack task at durations up to one hour.
Unified Synthesis of Compositional Speech and Sound from Free-Form Text Prompts
May 27, 2026Audio generation has made significant progress, yet synthesizing unified audio where speech and sounds are naturally composited remains a challenge. Current methods either rely on disjoint pipelines, which fail to capture fine-grained interactions, or require structured inputs and external text rewriting, which limits the flexibility of free-form text prompts. In this paper, we introduce a new task: Free-Form-Text-Prompt-to-Unified-Audio generation, which aims to directly synthesize unified audio containing speech, sound, and their composites from unconstrained natural language. To address this task, we propose PlanAudio, a unified, autoregressive LLM-based framework. First, it simplifies the model architecture by leveraging intrinsic LLM reasoning capability instead of traditional text encoders. Second, it introduces a semantic latent chain-of-thought mechanism, an implicit planning mechanism that bridges high-level semantic understanding and low-level acoustic synthesis. Furthermore, we create PlanAudio-Bench, a specialized benchmark for evaluating composite audio scenarios. We perform evaluations in the scenarios of speech, sound, and their composites. The results demonstrate that PlanAudio generally outperforms the existing pipeline and unified baselines, while staying competitive with models designed for a single scenario. Our analysis further reveals the superiority of semantic latent CoT over other CoT mechanisms and highlights the importance of continuous multi-scenario training curricula.
SyncDPO: Enhancing Temporal Synchronization in Video-Audio Joint Generation via Preference Learning
May 12, 2026Recent advancements in video-audio joint generation have achieved remarkable success in semantic correspondence. However, achieving precise temporal synchronization, which requires fine-grained alignment between audio events and their visual triggers, remains a challenging problem. The post-training method for joint generation is largely dominated by Supervised Fine-Tuning, but the commonly used Mean Squared Error loss provides insufficient penalties for subtle temporal misalignments. Direct Preference Optimization offers an alternative by introducing explicit misaligned counterparts to better improve temporal sensitivity. In this paper we propose a post-training framework SyncDPO, leveraging DPO to improve the temporal sensitivity of V-A joint generation. Conventional DPO pipelines typically depend on costly sampling-and-ranking procedures to construct preference pairs, resulting in substantial computational cost. To improve efficiency, we introduce a suite of on-the-fly rule-based negative construction strategies that distort temporal structures without incurring additional annotation or sampling. We demonstrate that the temporal alignment capability can be effectively reinforced by providing explicit negative supervision through temporally distorted V-A pairs. Accordingly, we implement a curriculum learning strategy that progressively increases the difficulty of negative samples, transitioning from coarse misalignment to subtle inconsistencies. Extensive objective and subjective experiments across four diverse benchmarks, ranging from ambient sound videos to human speech videos, demonstrate that SyncDPO significantly outperforms other methods in improving model's temporal alignment capability. It also demonstrates superior generalization on out-of-distribution benchmark by capturing intrinsic motion-sound dynamics. Demo and code is available in https://syncdpo.github.io/syncdpo/.
ChronusOmni: Improving Time Awareness of Omni Large Language Models
Dec 10, 2025Time awareness is a fundamental ability of omni large language models, especially for understanding long videos and answering complex questions. Previous approaches mainly target vision-language scenarios and focus on the explicit temporal grounding questions, such as identifying when a visual event occurs or determining what event happens at aspecific time. However, they often make insufficient use of the audio modality, and overlook implicit temporal grounding across modalities--for example, identifying what is visually present when a character speaks, or determining what is said when a visual event occurs--despite such cross-modal temporal relations being prevalent in real-world scenarios. In this paper, we propose ChronusOmni, an omni large language model designed to enhance temporal awareness for both explicit and implicit audiovisual temporal grounding. First, we interleave text-based timestamp tokens with visual and audio representations at each time unit, enabling unified temporal modeling across modalities. Second, to enforce correct temporal ordering and strengthen fine-grained temporal reasoning, we incorporate reinforcement learning with specially designed reward functions. Moreover, we construct ChronusAV, a temporally-accurate, modality-complete, and cross-modal-aligned dataset to support the training and evaluation on audiovisual temporal grounding task. Experimental results demonstrate that ChronusOmni achieves state-of-the-art performance on ChronusAV with more than 30% improvement and top results on most metrics upon other temporal grounding benchmarks. This highlights the strong temporal awareness of our model across modalities, while preserving general video and audio understanding capabilities.
SpeechComposer: Unifying Multiple Speech Tasks with Prompt Composition
Jan 31, 2024Recent advancements in language models have significantly enhanced performance in multiple speech-related tasks. Existing speech language models typically utilize task-dependent prompt tokens to unify various speech tasks in a single model. However, this design omits the intrinsic connections between different speech tasks, which can potentially boost the performance of each task. In this work, we propose a novel decoder-only speech language model, SpeechComposer, that can unify common speech tasks by composing a fixed set of prompt tokens. Built upon four primary tasks -- speech synthesis, speech recognition, speech language modeling, and text language modeling -- SpeechComposer can easily extend to more speech tasks via compositions of well-designed prompt tokens, like voice conversion and speech enhancement. The unification of prompt tokens also makes it possible for knowledge sharing among different speech tasks in a more structured manner. Experimental results demonstrate that our proposed SpeechComposer can improve the performance of both primary tasks and composite tasks, showing the effectiveness of the shared prompt tokens. Remarkably, the unified decoder-only model achieves a comparable and even better performance than the baselines which are expert models designed for single tasks.
ComedicSpeech: Text To Speech For Stand-up Comedies in Low-Resource Scenarios
May 20, 2023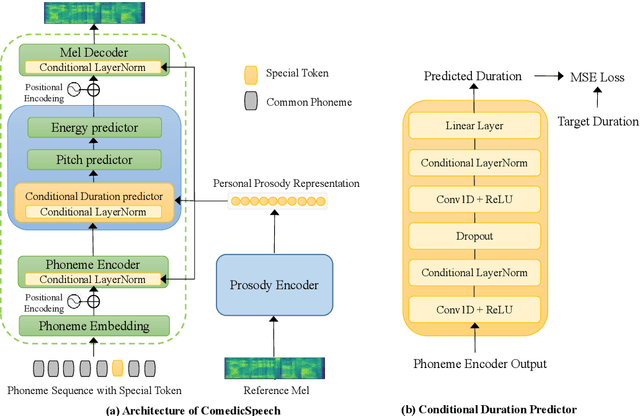

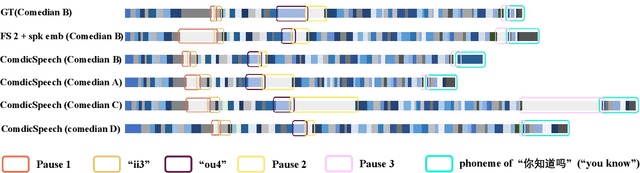
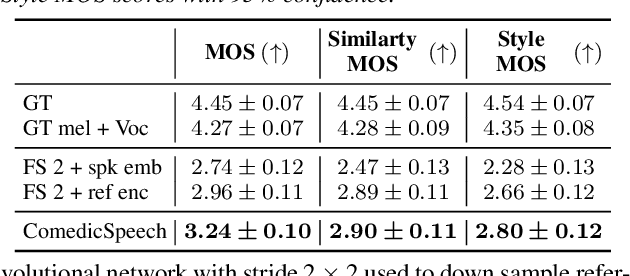
Text to Speech (TTS) models can generate natural and high-quality speech, but it is not expressive enough when synthesizing speech with dramatic expressiveness, such as stand-up comedies. Considering comedians have diverse personal speech styles, including personal prosody, rhythm, and fillers, it requires real-world datasets and strong speech style modeling capabilities, which brings challenges. In this paper, we construct a new dataset and develop ComedicSpeech, a TTS system tailored for the stand-up comedy synthesis in low-resource scenarios. First, we extract prosody representation by the prosody encoder and condition it to the TTS model in a flexible way. Second, we enhance the personal rhythm modeling by a conditional duration predictor. Third, we model the personal fillers by introducing comedian-related special tokens. Experiments show that ComedicSpeech achieves better expressiveness than baselines with only ten-minute training data for each comedian. The audio samples are available at https://xh621.github.io/stand-up-comedy-demo/