 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComedicSpeech: Text To Speech For Stand-up Comedies in Low-Resource Scenarios
May 20, 2023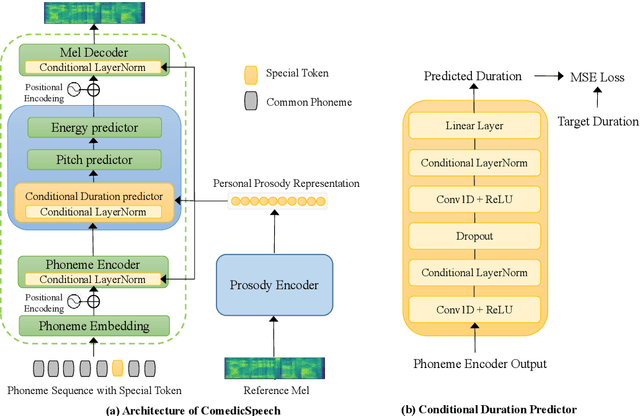

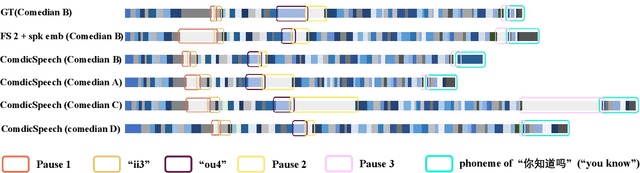
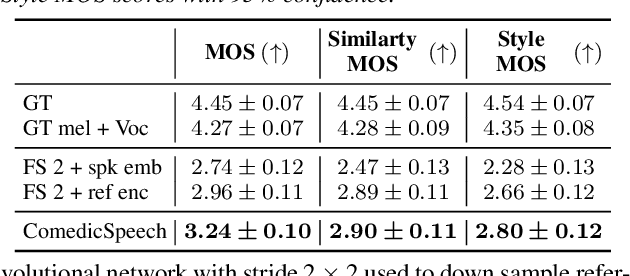
Text to Speech (TTS) models can generate natural and high-quality speech, but it is not expressive enough when synthesizing speech with dramatic expressiveness, such as stand-up comedies. Considering comedians have diverse personal speech styles, including personal prosody, rhythm, and fillers, it requires real-world datasets and strong speech style modeling capabilities, which brings challenges. In this paper, we construct a new dataset and develop ComedicSpeech, a TTS system tailored for the stand-up comedy synthesis in low-resource scenarios. First, we extract prosody representation by the prosody encoder and condition it to the TTS model in a flexible way. Second, we enhance the personal rhythm modeling by a conditional duration predictor. Third, we model the personal fillers by introducing comedian-related special tokens. Experiments show that ComedicSpeech achieves better expressiveness than baselines with only ten-minute training data for each comedian. The audio samples are available at https://xh621.github.io/stand-up-comedy-demo/