 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Detection Classification via Clustering SVM for Various Robot Collaboration Task
May 05, 2024We introduce an advanced, swift pattern recognition strategy for various multiple robotics during curve negotiation. This method, leveraging a sophisticated k-means clustering-enhanced Support Vector Machine algorithm, distinctly categorizes robotics into flying or mobile robots. Initially, the paradigm considers robot locations and features as quintessential parameters indicative of divergent robot patterns. Subsequently, employing the k-means clustering technique facilitates the efficient segregation and consolidation of robotic data, significantly optimizing the support vector delineation process and expediting the recognition phase. Following this preparatory phase, the SVM methodology is adeptly applied to construct a discriminative hyperplane, enabling precise classification and prognostication of the robot category. To substantiate the efficacy and superiority of the k-means framework over traditional SVM approaches, a rigorous cross-validation experiment was orchestrated, evidencing the former's enhanced performance in robot group classification.
Measure of Uncertainty in Human Emotions
Aug 08, 2023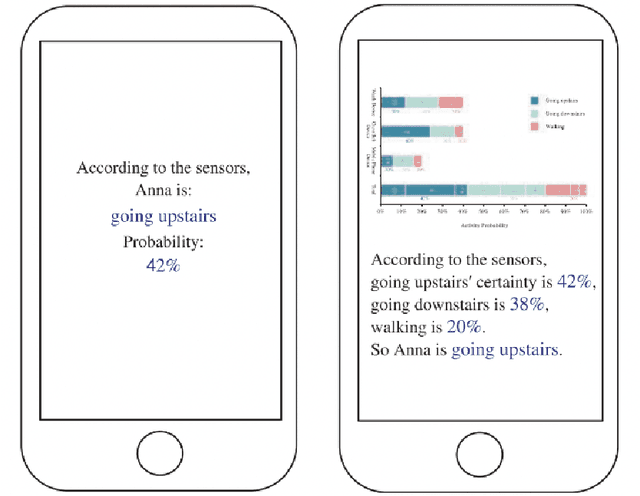
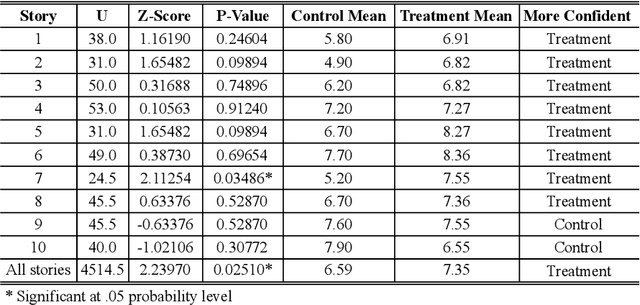


Many research explore how well computers are able to examine emotions displayed by humans and use that data to perform different tasks. However, there have been very few research which evaluate the computers ability to generate emotion classification information in an attempt to help the user make decisions or perform tasks. This is a crucial area to explore as it is paramount to the two way communication between humans and computers. This research conducted an experiment to investigate the impact of different uncertainty information displays of emotion classification on the human decision making process. Results show that displaying more uncertainty information can help users to be more confident when making decisions.
Relational Data Synthesis using Generative Adversarial Networks: A Design Space Exploration
Aug 28, 2020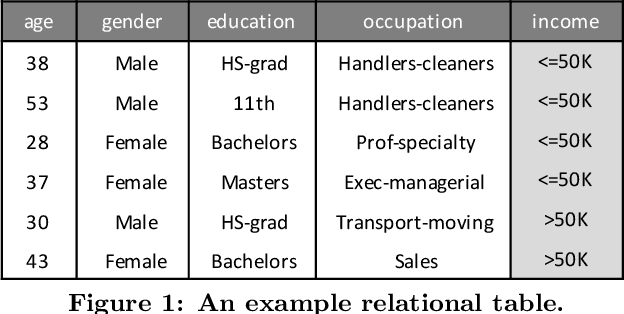
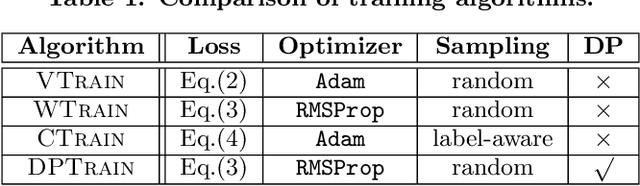


The proliferation of big data has brought an urgent demand for privacy-preserving data publishing. Traditional solutions to this demand have limitations on effectively balancing the tradeoff between privacy and utility of the released data. Thus, the database community and machine learning community have recently studied a new problem of relational data synthesis using generative adversarial networks (GAN) and proposed various algorithms. However, these algorithms are not compared under the same framework and thus it is hard for practitioners to understand GAN's benefits and limitations. To bridge the gaps, we conduct so far the most comprehensive experimental study that investigates applying GAN to relational data synthesis. We introduce a unified GAN-based framework and define a space of design solutions for each component in the framework, including neural network architectures and training strategies. We conduct extensive experiments to explore the design space and compare with traditional data synthesis approaches. Through extensive experiments, we find that GAN is very promising for relational data synthesis, and provide guidance for selecting appropriate design solutions. We also point out limitations of GAN and identify future research directions.