 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a User Privacy-Aware Mobile Gaming App Installation Prediction Model
Feb 07, 2023


Over the past decade, programmatic advertising has received a great deal of attention in the online advertising industry. A real-time bidding (RTB) system is rapidly becoming the most popular method to buy and sell online advertising impressions. Within the RTB system, demand-side platforms (DSP) aim to spend advertisers' campaign budgets efficiently while maximizing profit, seeking impressions that result in high user responses, such as clicks or installs. In the current study, we investigate the process of predicting a mobile gaming app installation from the point of view of a particular DSP, while paying attention to user privacy, and exploring the trade-off between privacy preservation and model performance. There are multiple levels of potential threats to user privacy, depending on the privacy leaks associated with the data-sharing process, such as data transformation or de-anonymization. To address these concerns, privacy-preserving techniques were proposed, such as cryptographic approaches, for training privacy-aware machine-learning models. However, the ability to train a mobile gaming app installation prediction model without using user-level data, can prevent these threats and protect the users' privacy, even though the model's ability to predict may be impaired. Additionally, current laws might force companies to declare that they are collecting data, and might even give the user the option to opt out of such data collection, which might threaten companies' business models in digital advertising, which are dependent on the collection and use of user-level data. We conclude that privacy-aware models might still preserve significant capabilities, enabling companies to make better decisions, dependent on the privacy-efficacy trade-off utility function of each case.
Implementation and Evaluation of a System for Assessment of The Quality of Long-Term Management of Patients at a Geriatric Hospital
Nov 23, 2022



Background The use of a clinical decision support system for assessing the quality of care, based on computerized clinical guidelines (GLs), is likely to improve care, reduce costs, save time, and enhance the staff's capabilities. Objectives Implement and evaluate a system for assessment of the quality of the care, in the domain of management of pressure ulcers, by investigating the level of compliance of the staff to the GLs. Methods Using data for 100 random patients from the local EMR system we performed a technical evaluation, checking the applicability and usability, followed by a functional evaluation of the system investigating the quality metrics given to the compliance of the medical's staff to the protocol. We compared the scores given by the nurse when supported by the system, to the scores given by the nurse without the system's support, and to the scores given by the system. We also measured the time taken to perform the assessment with and without the system's support. Results There were no significant differences in the scores of most measures given by the nurse using the system, compared to the scores given by the system. There were also no significant differences across the values of most quality measures given by the nurse without support compared to the values given by the nurse with support. Using the system, however, significantly reduced the nurse's average assessment time. Conclusions Using an automated quality-assessment system, may enable a senior nurse, to quickly and accurately assess the quality of care. In addition to its accuracy, the system considerably reduces the time taken to assess the various quality measures.
Meta-Learning Approaches for a One-Shot Collective-Decision Aggregation: Correctly Choosing how to Choose Correctly
Apr 03, 2022
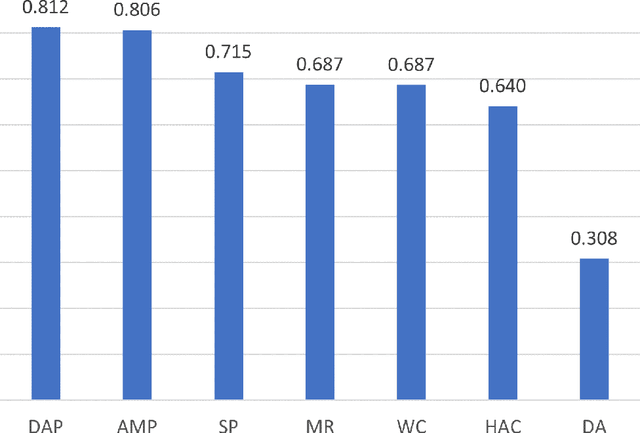

Aggregating successfully the choices regarding a given decision problem made by the multiple collective members into a single solution is essential for exploiting the collective's intelligence and for effective crowdsourcing. There are various aggregation techniques, some of which come down to a simple and sometimes effective deterministic aggregation rule. However, it has been shown that the efficiency of those techniques is unstable under varying conditions and within different domains. Other methods mainly rely on learning from the decision-makers previous responses or the availability of additional information about them. In this study, we present two one-shot machine-learning-based aggregation approaches. The first predicts, given multiple features about the collective's choices, including meta-cognitive ones, which aggregation method will be best for a given case. The second directly predicts which decision is optimal, given, among other things, the selection made by each method. We offer a meta-cognitive feature-engineering approach for characterizing a collective decision-making case in a context-sensitive fashion. In addition, we offer a new aggregation method, the Devil's-Advocate aggregator, to deal with cases in which standard aggregation methods are predicted to fail. Experimental results show that using either of our proposed approaches increases the percentage of successfully aggregated cases (i.e., cases in which the correct answer is returned) significantly, compared to the uniform application of each rule-based aggregation method. We also demonstrate the importance of the Devil's Advocate aggregator.
Exploiting Meta-Cognitive Features for a Machine-Learning-Based One-Shot Group-Decision Aggregation
Jan 20, 2022
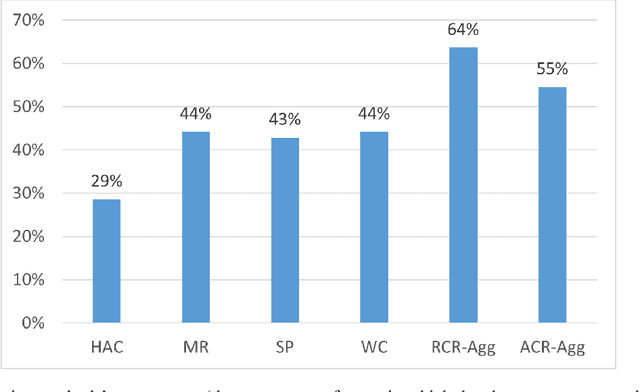

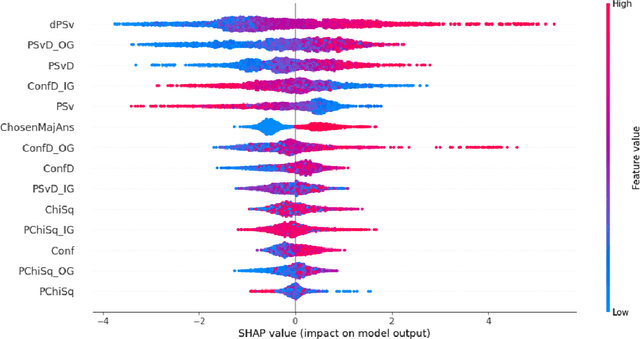
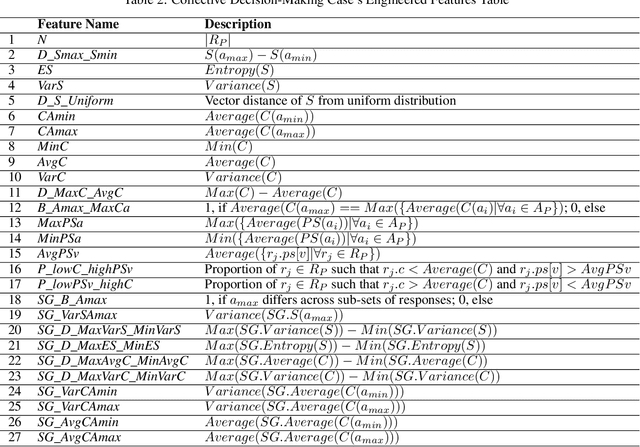
The outcome of a collective decision-making process, such as crowdsourcing, often relies on the procedure through which the perspectives of its individual members are aggregated. Popular aggregation methods, such as the majority rule, often fail to produce the optimal result, especially in high-complexity tasks. Methods that rely on meta-cognitive information, such as confidence-based methods and the Surprisingly Popular Option, had shown an improvement in various tasks. However, there is still a significant number of cases with no optimal solution. Our aim is to exploit meta-cognitive information and to learn from it, for the purpose of enhancing the ability of the group to produce a correct answer. Specifically, we propose two different feature-representation approaches: (1) Response-Centered feature Representation (RCR), which focuses on the characteristics of the individual response instances, and (2) Answer-Centered feature Representation (ACR), which focuses on the characteristics of each of the potential answers. Using these two feature-representation approaches, we train Machine-Learning (ML) models, for the purpose of predicting the correctness of a response and of an answer. The trained models are used as the basis of an ML-based aggregation methodology that, contrary to other ML-based techniques, has the advantage of being a "one-shot" technique, independent from the crowd-specific composition and personal record, and adaptive to various types of situations. To evaluate our methodology, we collected 2490 responses for different tasks, which we used for feature engineering and for the training of ML models. We tested our feature-representation approaches through the performance of our proposed ML-based aggregation methods. The results show an increase of 20% to 35% in the success rate, compared to the use of standard rule-based aggregation methods.
Implementation and Evaluation of a Multivariate Abstraction-Based, Interval-Based Dynamic Time-Warping Method as a Similarity Measure for Longitudinal Medical Records
May 18, 2021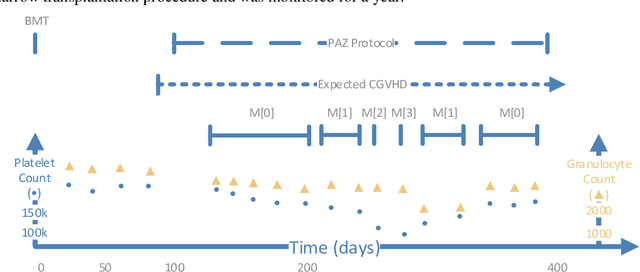


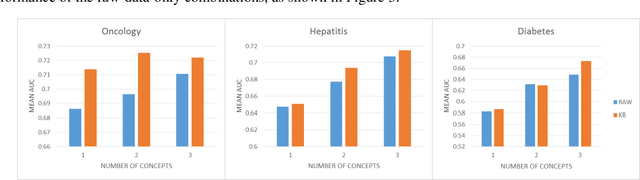
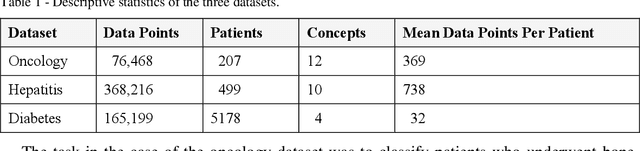
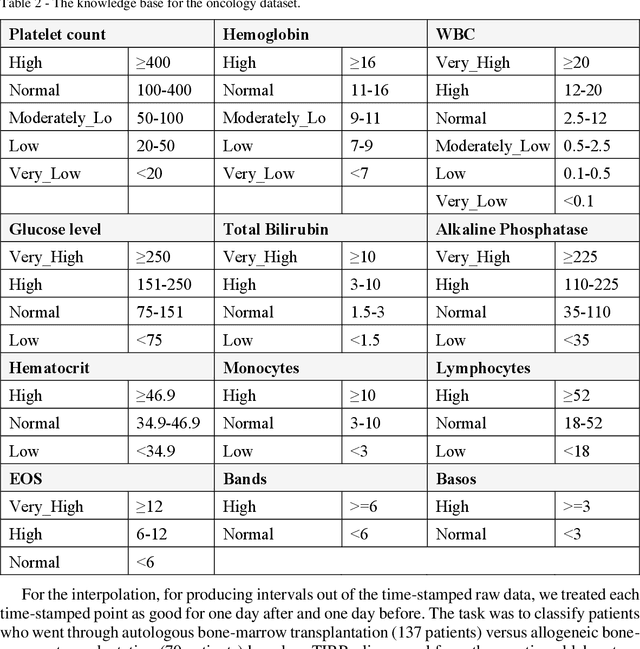
We extended dynamic time warping (DTW) into interval-based dynamic time warping (iDTW), including (A) interval-based representation (iRep): [1] abstracting raw, time-stamped data into interval-based abstractions, [2] comparison-period scoping, [3] partitioning abstract intervals into a given temporal granularity; (B) interval-based matching (iMatch): matching partitioned, abstract-concepts records, using a modified DTW. Using domain knowledge, we abstracted the raw data of medical records, for up to three concepts out of four or five relevant concepts, into two interval types: State abstractions (e.g. LOW, HIGH) and Gradient abstractions (e.g. INCREASING, DECREASING). We created all uni-dimensional (State or Gradient) or multi-dimensional (State and Gradient) abstraction combinations. Tasks: Classifying 161 oncology patients records as autologous or allogenic bone-marrow transplantation; classifying 125 hepatitis patients records as B or C hepatitis; predicting micro- or macro-albuminuria in the next year for 151 Type 2 diabetes patients. We used a k-Nearest-Neighbors majority, k=1 to SQRT(N), N = set size. 50,328 10-fold cross-validation experiments were performed: 23,400 (Oncology), 19,800 (Hepatitis), 7,128 (Diabetes). Measures: Area Under the Curve (AUC), optimal Youden's Index. Paired t-tests compared result vectors for equivalent configurations other than a tested variable, to determine a significant mean accuracy difference (P<0.05). Mean classification and prediction using abstractions was significantly better than using only raw time-stamped data. In each domain, at least one abstraction combination led to a significantly better performance than using raw data. Increasing feature number, and using multi-dimensional abstractions, enhanced performance. Unlike when using raw data, optimal performance was often reached with k=5, using abstractions.
Evaluation of a Bi-Directional Methodology for Automated Assessment of Compliance to Continuous Application of Clinical Guidelines, in the Type 2 Diabetes-Management Domain
Mar 16, 2021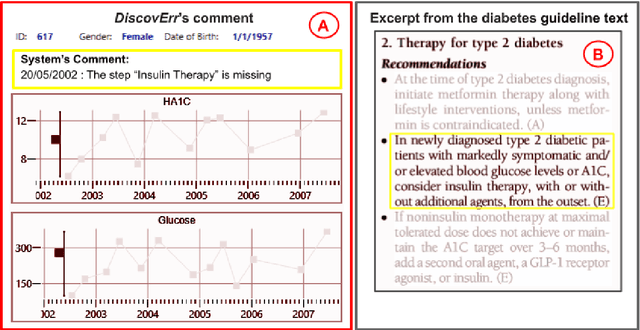

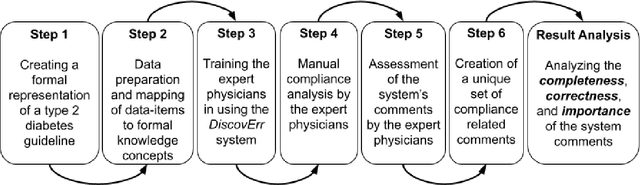
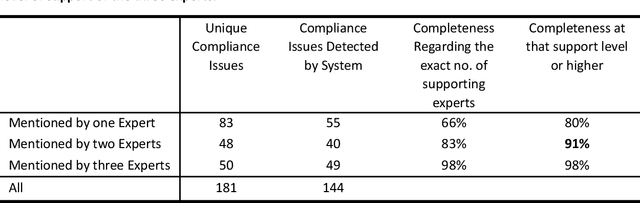
We evaluated the DiscovErr system, in which we had previously implemented a new methodology for assessment of compliance to continuous application of evidence-based clinical guidelines, based on a bidirectional search from the guideline objectives to the patient's longitudinal data, and vice versa. We compared the system comments on 1584 transactions regarding the management, over a mean of 5.23 years, of 10 randomly selected Type 2 diabetes patients, to those of two diabetes experts and a senior family practitioner. After providing their own comments, the experts assessed both the correctness (precision) and the importance of each of the DiscovErr system comments. The completeness (recall or coverage) of the system was computed by comparing its comments to those made by the experts. The system made 279 comments. The experts made 181 unique comments. The completeness of the system was 91% compared to comments made by at least two experts, and 98% when compared to comments made by all three. 172 comments were evaluated by the experts for correctness and importance: All 114 medication-related comments, and a random 35% of the 165 monitoring-related comments. The system's correctness was 81% compared to comments judged as correct by both diabetes experts, and 91% compared to comments judged as correct by a diabetes expert and at least as partially correct by the other. 89% of the comments were judged as important by both diabetes experts, 8% were judged as important by one expert, 3% were judged as less important by both experts. The completeness scores of the three experts (compared to the comments of all experts plus the validated system comments) were 75%, 60%, and 55%; the experts' correctness scores (compared to their majority) were respectively 99%, 91%, and 88%. Conclusion: Systems such as DiscovErr can assess the quality of continuous guideline-based care.
A Methodology for Bi-Directional Knowledge-Based Assessment of Compliance to Continuous Application of Clinical Guidelines
Mar 13, 2021
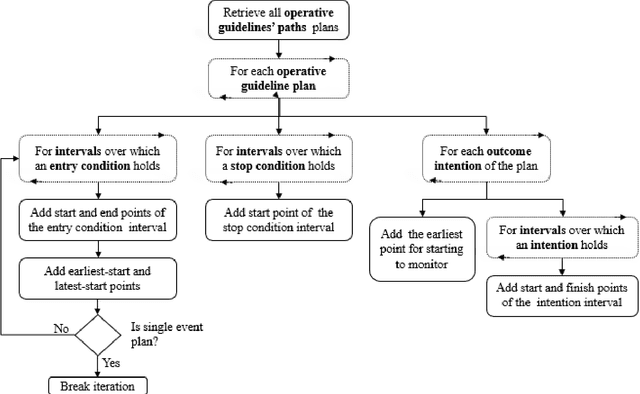
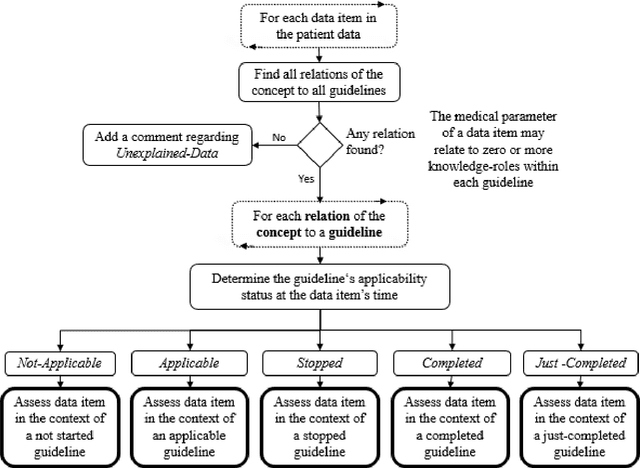
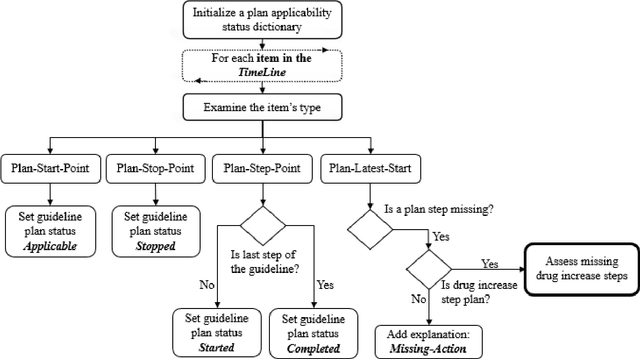
Clinicians often do not sufficiently adhere to evidence-based clinical guidelines in a manner sensitive to the context of each patient. It is important to detect such deviations, typically including redundant or missing actions, even when the detection is performed retrospectively, so as to inform both the attending clinician and policy makers. Furthermore, it would be beneficial to detect such deviations in a manner proportional to the level of the deviation, and not to simply use arbitrary cut-off values. In this study, we introduce a new approach for automated guideline-based quality assessment of the care process, the bidirectional knowledge-based assessment of compliance (BiKBAC) method. Our BiKBAC methodology assesses the degree of compliance when applying clinical guidelines, with respect to multiple different aspects of the guideline (e.g., the guideline's process and outcome objectives). The assessment is performed through a highly detailed, automated quality-assessment retrospective analysis, which compares a formal representation of the guideline and of its process and outcome intentions (we use the Asbru language for that purpose) with the longitudinal electronic medical record of its continuous application over a significant time period, using both a top-down and a bottom-up approach, which we explain in detail. Partial matches of the data to the process and to the outcome objectives are resolved using fuzzy temporal logic. We also introduce the DiscovErr system, which implements the BiKBAC approach, and present its detailed architecture. The DiscovErr system was evaluated in a separate study in the type 2 diabetes management domain, by comparing its performance to a panel of three clinicians, with highly encouraging results with respect to the completeness and correctness of its comments.
Distributed Application of Guideline-Based Decision Support through Mobile Devices: Implementation and Evaluation
Feb 22, 2021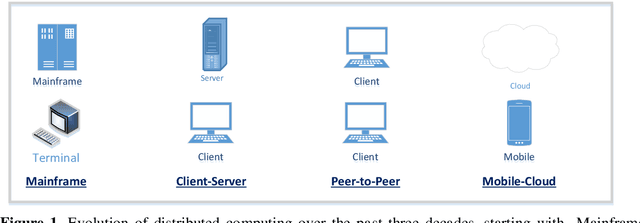

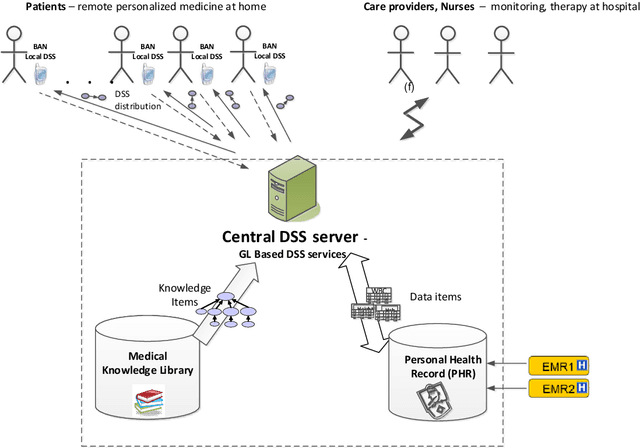
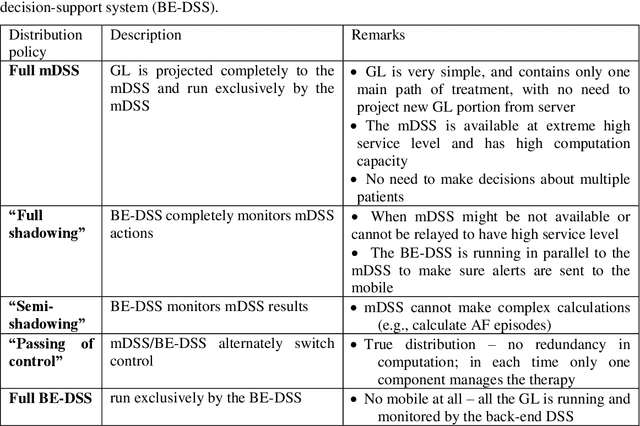
Traditionally Guideline(GL)based Decision Support Systems (DSSs) use a centralized infrastructure to generate recommendations to care providers. However, managing patients at home is preferable, reducing costs and empowering patients. We aimed to design, implement, and demonstrate the feasibility of a new architecture for a distributed DSS that provides patients with personalized, context-sensitive, evidence based guidance through their mobile device, and increases the robustness of the distributed application of the GL, while maintaining access to the patient longitudinal record and to an up to date evidence based GL repository. We have designed and implemented a novel projection and callback (PCB) model, in which small portions of the evidence based GL procedural knowledge, adapted to the patient preferences and to their current context, are projected from a central DSS server, to a local DSS on the patient mobile device that applies that knowledge. When appropriate, as defined by a temporal pattern within the projected plan, the local DSS calls back the central DSS, requesting further assistance, possibly another projection. Thus, the GL specification includes two levels: one for the central DSS, one for the local DSS. We successfully evaluated the PCB model within the MobiGuide EU project by managing Gestational Diabetes Mellitus patients in Spain, and Atrial Fibrillation patients in Italy. Significant differences exist between the two GL representations, suggesting additional ways to characterize GLs. Mean time between the central and local interactions was quite different for the two GLs: 3.95 days for gestational diabetes, 23.80 days for atrial fibrillation. Most interactions, 83%, were due to projections to the mDSS. Others were data notifications, mostly to change context. Robustness was demonstrated through successful recovery from multiple local DSS crashes.
The Ethical Implications of Shared Medical Decision Making without Providing Adequate Computational Support to the Care Provider and to the Patient
Feb 03, 2021There is a clear need to involve patients in medical decisions. However, cognitive psychological research has highlighted the cognitive limitations of humans with respect to 1. Probabilistic assessment of the patient state and of potential outcomes of various decisions, 2. Elicitation of the patient utility function, and 3. Integration of the probabilistic knowledge and of patient preferences to determine the optimal strategy. Therefore, without adequate computational support, current shared decision models have severe ethical deficiencies. An informed consent model unfairly transfers the responsibility to a patient who does not have the necessary knowledge, nor the integration capability. A paternalistic model endows with exaggerated power a physician who might not be aware of the patient preferences, is prone to multiple cognitive biases, and whose computational integration capability is bounded. Recent progress in Artificial Intelligence suggests adding a third agent: a computer, in all deliberative medical decisions: Non emergency medical decisions in which more than one alternative exists, the patient preferences can be elicited, the therapeutic alternatives might be influenced by these preferences, medical knowledge exists regarding the likelihood of the decision outcomes, and there is sufficient decision time. Ethical physicians should exploit computational decision support technologies, neither making the decisions solely on their own, nor shirking their duty and shifting the responsibility to patients in the name of informed consent. The resulting three way (patient, care provider, computer) human machine model that we suggest emphasizes the patient preferences, the physician knowledge, and the computational integration of both aspects, does not diminish the physician role, but rather brings out the best in human and machine.
The Semantic Adjacency Criterion in Time Intervals Mining
Jan 11, 2021
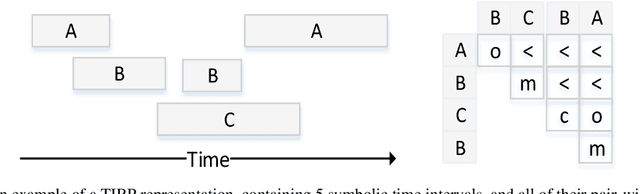
Frequent temporal patterns discovered in time-interval-based multivariate data, although syntactically correct, might be non-transparent: For some pattern instances, there might exist intervals for the same entity that contradict the pattern's usual meaning. We conjecture that non-transparent patterns are also less useful as classification or prediction features. We propose a new pruning constraint during a frequent temporal-pattern discovery process, the Semantic Adjacency Criterion [SAC], which exploits domain knowledge to filter out patterns that contain potentially semantically contradictory components. We have defined three SAC versions, and tested their effect in three medical domains. We embedded these criteria in a frequent-temporal-pattern discovery framework. Previously, we had informally presented the SAC principle and showed that using it to prune patterns enhances the repeatability of their discovery in the same clinical domain. Here, we define formally the semantics of three SAC variations, and compare the use of the set of pruned patterns to the use of the complete set of discovered patterns, as features for classification and prediction tasks in three different medical domains. We induced four classifiers for each task, using four machine-learning methods: Random Forests, Naive Bayes, SVM, and Logistic Regression. The features were frequent temporal patterns discovered in each data set. SAC-based temporal pattern-discovery reduced by up to 97% the number of discovered patterns and by up to 98% the discovery runtime. But the classification and prediction performance of the reduced SAC-based pattern-based features set, was as good as when using the complete set. Using SAC can significantly reduce the number of discovered frequent interval-based temporal patterns, and the corresponding computational effort, without losing classification or prediction performance.