 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Approaches for a One-Shot Collective-Decision Aggregation: Correctly Choosing how to Choose Correctly
Apr 03, 2022
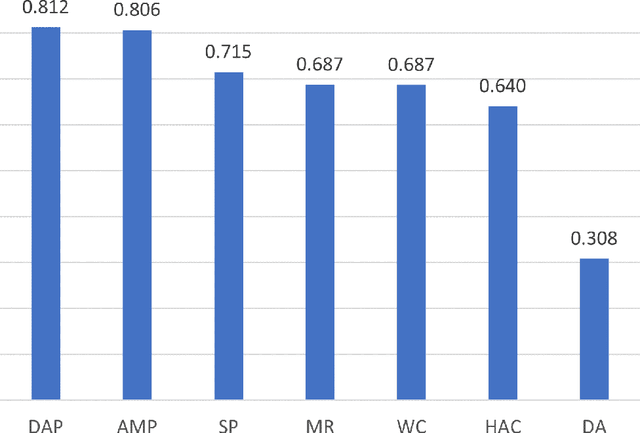

Aggregating successfully the choices regarding a given decision problem made by the multiple collective members into a single solution is essential for exploiting the collective's intelligence and for effective crowdsourcing. There are various aggregation techniques, some of which come down to a simple and sometimes effective deterministic aggregation rule. However, it has been shown that the efficiency of those techniques is unstable under varying conditions and within different domains. Other methods mainly rely on learning from the decision-makers previous responses or the availability of additional information about them. In this study, we present two one-shot machine-learning-based aggregation approaches. The first predicts, given multiple features about the collective's choices, including meta-cognitive ones, which aggregation method will be best for a given case. The second directly predicts which decision is optimal, given, among other things, the selection made by each method. We offer a meta-cognitive feature-engineering approach for characterizing a collective decision-making case in a context-sensitive fashion. In addition, we offer a new aggregation method, the Devil's-Advocate aggregator, to deal with cases in which standard aggregation methods are predicted to fail. Experimental results show that using either of our proposed approaches increases the percentage of successfully aggregated cases (i.e., cases in which the correct answer is returned) significantly, compared to the uniform application of each rule-based aggregation method. We also demonstrate the importance of the Devil's Advocate aggregator.
Exploiting Meta-Cognitive Features for a Machine-Learning-Based One-Shot Group-Decision Aggregation
Jan 20, 2022
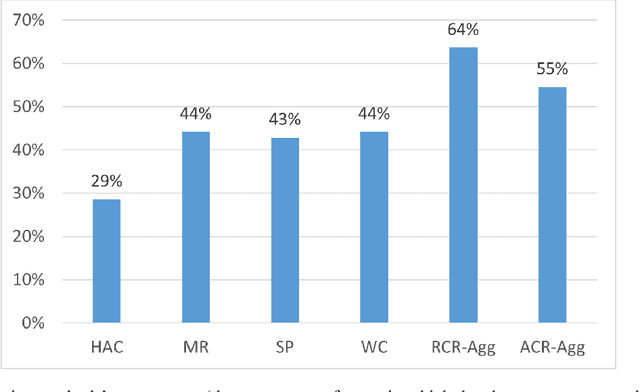

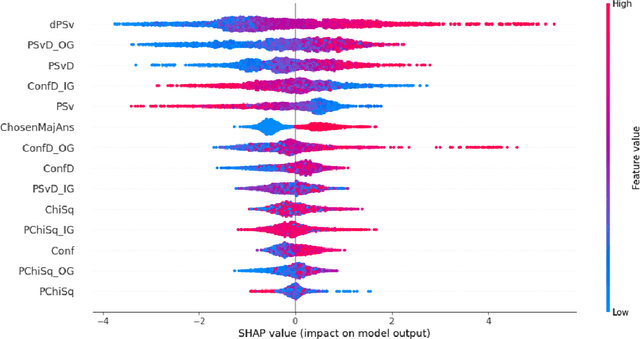
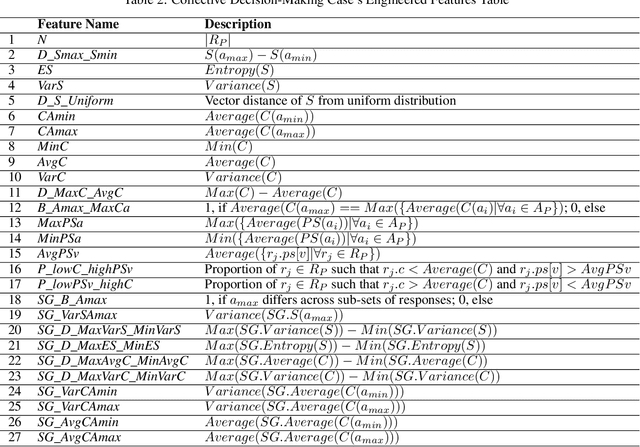
The outcome of a collective decision-making process, such as crowdsourcing, often relies on the procedure through which the perspectives of its individual members are aggregated. Popular aggregation methods, such as the majority rule, often fail to produce the optimal result, especially in high-complexity tasks. Methods that rely on meta-cognitive information, such as confidence-based methods and the Surprisingly Popular Option, had shown an improvement in various tasks. However, there is still a significant number of cases with no optimal solution. Our aim is to exploit meta-cognitive information and to learn from it, for the purpose of enhancing the ability of the group to produce a correct answer. Specifically, we propose two different feature-representation approaches: (1) Response-Centered feature Representation (RCR), which focuses on the characteristics of the individual response instances, and (2) Answer-Centered feature Representation (ACR), which focuses on the characteristics of each of the potential answers. Using these two feature-representation approaches, we train Machine-Learning (ML) models, for the purpose of predicting the correctness of a response and of an answer. The trained models are used as the basis of an ML-based aggregation methodology that, contrary to other ML-based techniques, has the advantage of being a "one-shot" technique, independent from the crowd-specific composition and personal record, and adaptive to various types of situations. To evaluate our methodology, we collected 2490 responses for different tasks, which we used for feature engineering and for the training of ML models. We tested our feature-representation approaches through the performance of our proposed ML-based aggregation methods. The results show an increase of 20% to 35% in the success rate, compared to the use of standard rule-based aggregation methods.